 夜雨聆风
夜雨聆风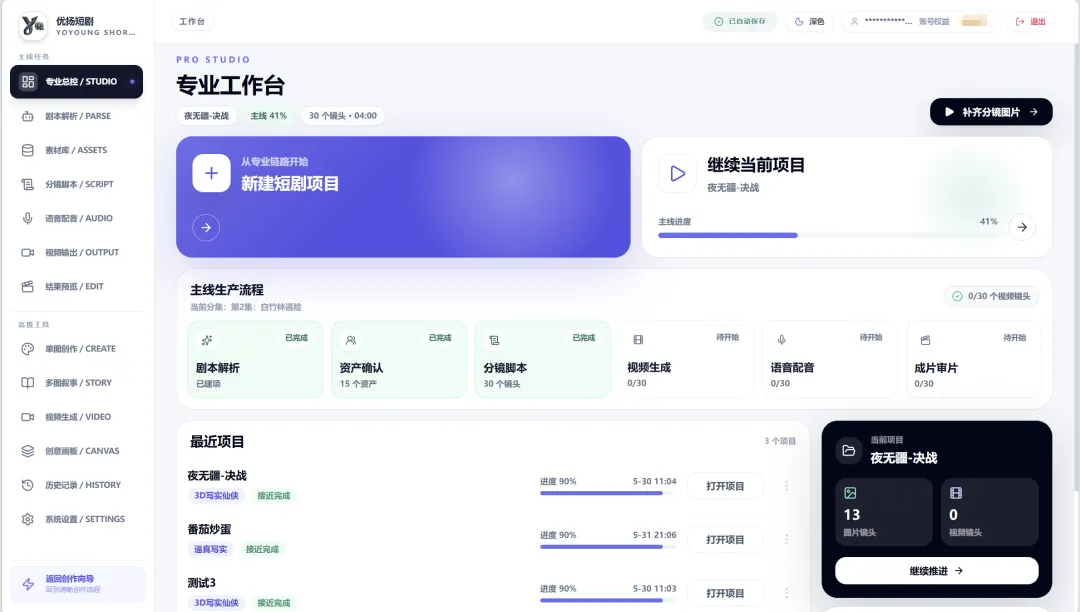
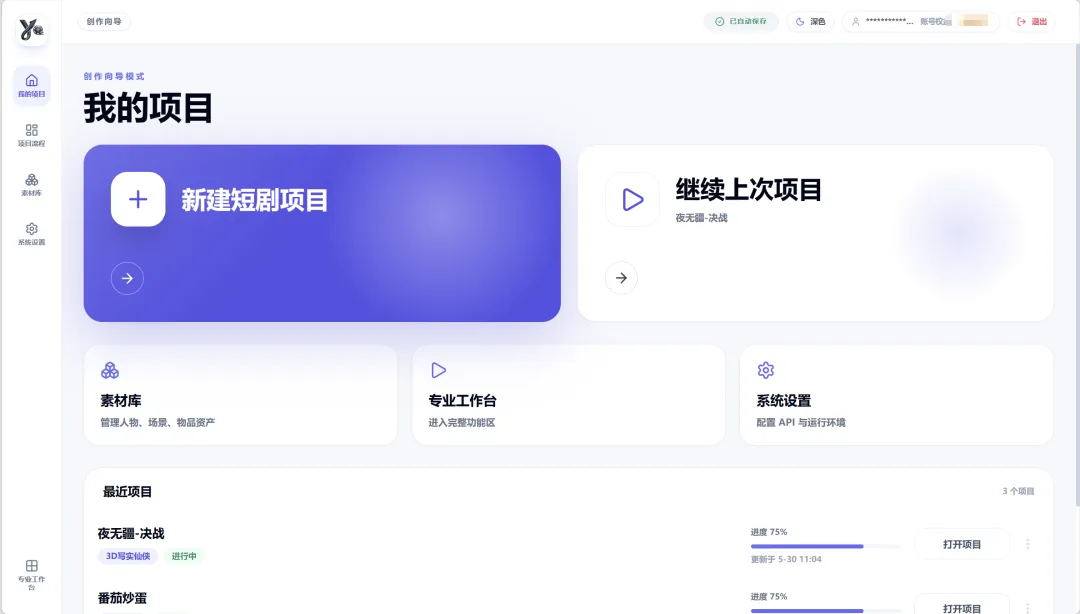
(2.0版本的2套前端IU)
上个月终于把影视短剧创作平台的 1.0 版本(Docker 本地包)完成并推送到 Github 上面去了,算是小小的一个里程碑。回想去年下半年,因为爱好接触到了动漫视频制作,也因为一时的冲动,怒冲了一年的可灵黑金会员。
但当时做视频需要结合 gemini 规划分镜的图片及视频提示词,再到可灵的网页版上面输出视频,就觉得非常麻烦。当时我就想为什么不做一个能把脚本、分镜、图片、视频全部搞定的一个应用平台呢!说干就干!但其实当时的我还只是一个使用 web 与 AI 聊天的小白!哪里懂什么前端、后端、云端服务器、备案啊,现在想起来当时的自己真是初生牛犊不怕虎啊。
📌 有话说:很多新人想学编程都是被这种“痛”逼出来的。别嘲笑自己当初的冲动,每一个能跑通的 Docker 镜像背后,都有无数次深夜调试的崩溃瞬间。
第一步:新手有笨办法,先别想架构
我最先接触的国外模型就是 gemini,当时的 gemini 还是挺好用的,多模态的能力不能说非常出色,但至少均衡,然后自己在 AI Studio 上面折腾出了自己的第一个应用前端(google 当时的前端审美依然很顶,自己也还算满意)。
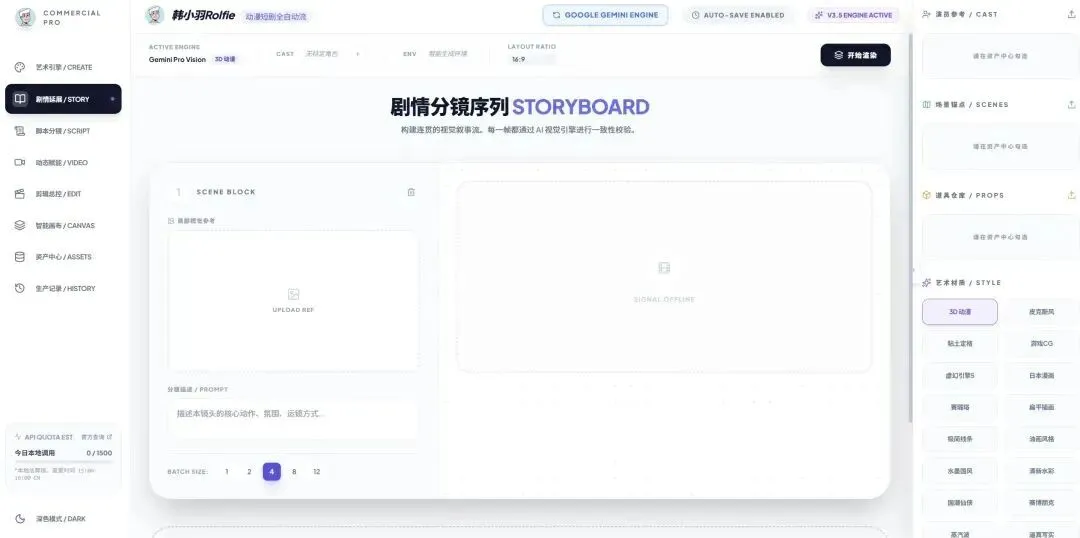
在这个过程学会了上下文过长会卡、也会出现幻觉,需要提前做好文本记忆备份,方便新的对话无缝衔接上,同时可视化的回撤功能对于初期的我很友好,比如我增加了新功能,结果原文件代码居然从 600 行变成了 550 行,从正常的逻辑判断 AI 肯定犯蠢了,我就能马上点击回撤,不让错误继续下去。
- •虽然这个方法很笨,但非常适用于新手的我。
- •不要一上来就想重构代码,能用就行。
- •利用 AI 的回溯能力是低成本试错的关键。
第二步:IDE 大乱斗,环境配置是个坑
光有前端肯定不行呀,所以我就开始折腾 IDE(当时还不习惯 CLI),VS Code、Cursor、OpenCode、Trae、Antigravity、Codex,全都下载了一遍。
也是因为有 gemini pro 的缘故,所以即使知道 Antigravity 不太好用而且对于环境要求比较高,但对于前期不想折腾的我,只能咬牙用它了。
虽然写后端的过程中犯了很多错误,但至少该有的框架以及结构还是帮我做出来了,只能本地跑跑,其实到这里依然只是抱着我自己本地使用的想法。
⚠️ 避坑指南:不要盲目追求最新款的 IDE。Antigravity 听起来高大上,但如果你的电脑硬件跟不上或者环境依赖太复杂,它反而会拖慢你的进度。适合新手的工具不是最牛的,而是最能跑通的。
第三步:产品思维决定上限
我说一点关于产品逻辑的内容。我的想法很简单,在我的应该用里面输入一些想法就能自动出分镜脚本、图片以及视频,而且当前应用也已经实现了。
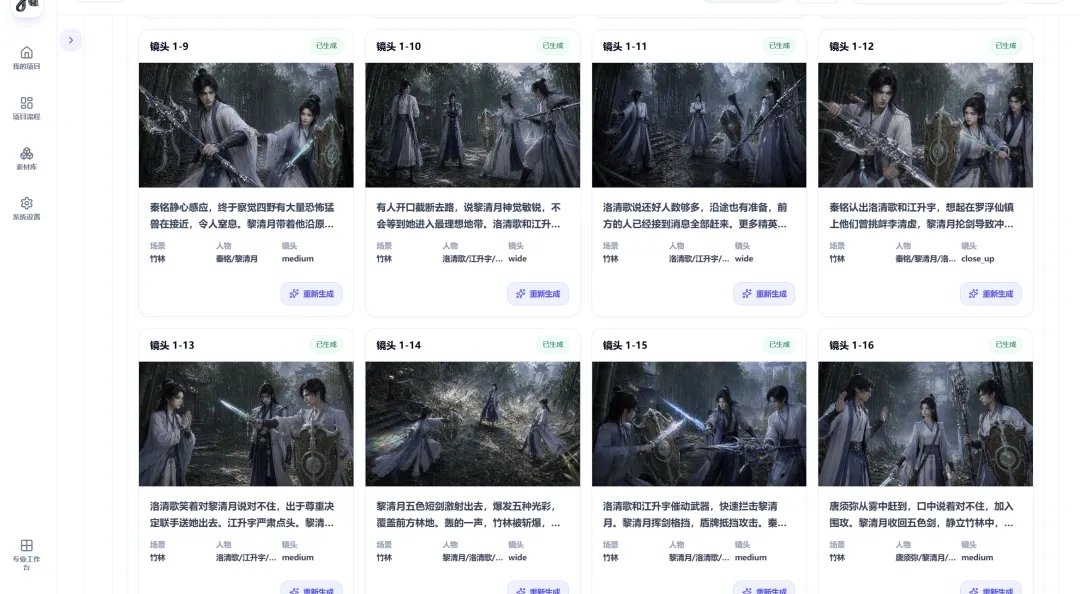
为了确保生图的人物、场景、物品的一致性,我增加了参考图锚定功能,也就是生成图片、生成分镜脚本、生成视频都是能看到有哪些人物、哪些场景、哪些物品的。
确保让人物在不同分镜里面表现得更自然,除了输出人物的多维视角图,我还增加了 6 种情绪图(喜怒哀惊惧肃),不同的场景调用不同的情绪。、

✅ 核心功能清单:1. 参考图锚定(解决一致性)2. 6 种情绪图(喜、怒、哀、惊、惧、肃)3. 多维空间逻辑理解(正、上帝、侧、后、仰、俯)4. 多图宫格功能(最高 12 宫格,弥补缺失镜头)5. 语音绑定(MINIMAX 接入 + 自定义声音)
还有一个痛点就是初期人物与场景的融合,非常僵硬,图片总是被作为背景板,人物也总是看着镜头。
因此我对场景图增加了多维空间逻辑理解(正面视角、上帝视角、侧视角、后视角、仰视角、俯视角),这样人物就能很好的融入到场景中去,当然还需配合不同的运镜视角,解决了人物一直盯着镜头看的尴尬画面。
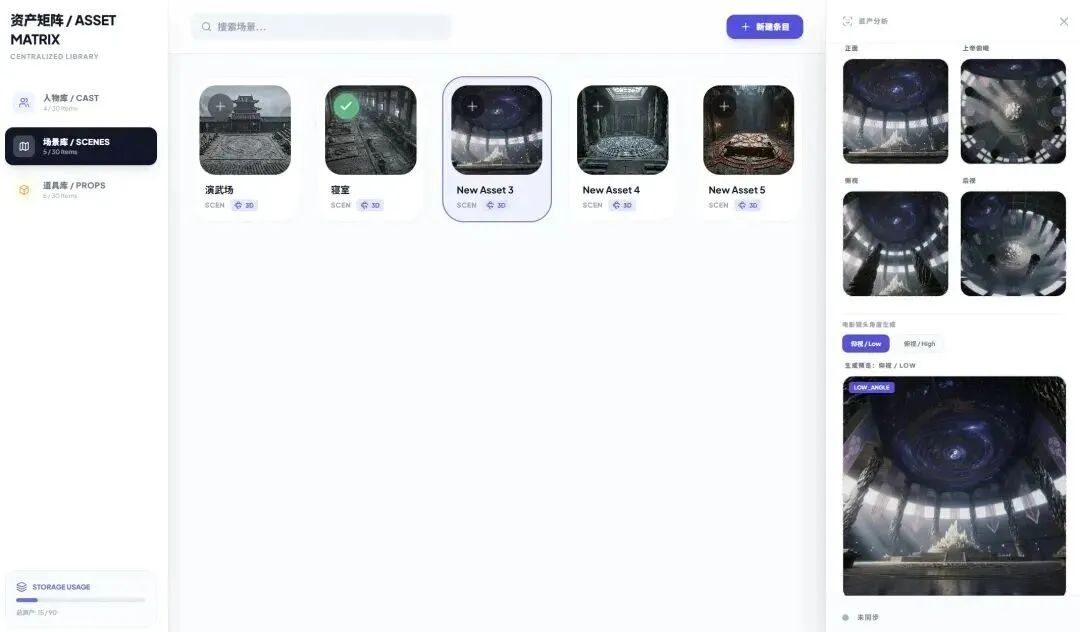
分镜脚本有可能依然存在不如意的剧情或者漏掉的剧情画面,所以我又增加了一个多图功能,其实就是多宫格,目前最高可以连续输出 12 个不同分镜画面,当然我想的话,也是可以增加到 24 宫格、36 宫的,这个功能的核心主要是弥补缺失的镜头,比如我想做一段高燃打斗场景,那这一组不同的运镜方式、不同的打斗动作、不同的视角就能帮我很好的实现。
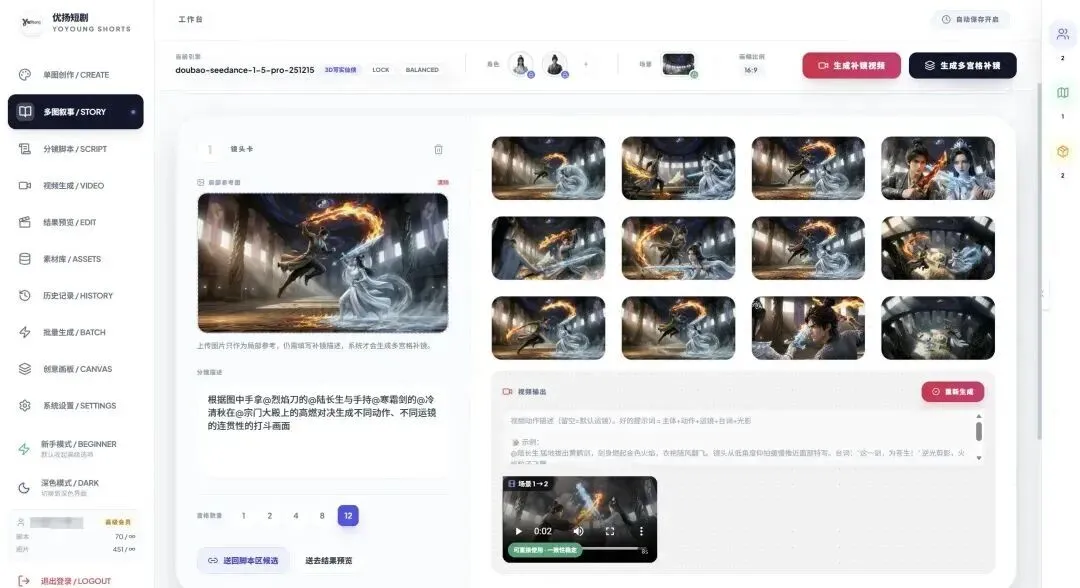
当然还做了不同情绪的语音功能,接入了 MINIMAX,也可以上传自定义声音全程绑定角色的音色,还有简单的画布,就不一一展开了。
第四步:从本地私有化到云端 SaaS
这个时候的我已经习惯使用 CLI 了,产品不知不觉做成了偏系统的多功能,所以就想着把它做成其他人也可以用呢?那就继续干吧!今年用的最多就是 CODEX,因为 CODEX 的客户端个人觉得还挺不错,所以客户端+CLI 同时用,有一点很好的就是客户端与 CLI 的历史对话是时时互通的,即使我用多个会员账号交替登录,也不影响我的对话记录,OpenAI 简直是我的救世主啊!
接着我又做了私有化本地部署、Docker 镜像包以及云端 SaaS 端口,以及云端服务器部署,这个过程说实话对于不是科班出身的我来说,是有挑战的。
但黑暗过后就是黎明,我也看到了一丝曙光,最重要的是通过这个项目我真的掌握了很多自己以前不曾接触到的知识和工具!
最后:给想入局AI Coding的同学一点建议
整体来讲就是从一开始只是简单想做一个功能,而且是自用的,到现在越来越系统,每个功能区之间都是有链路逻辑的,只要触碰其中一个环节:可能是顺序、也可能是传递层、也可能是语义、也可能是请求规则,都有可能影响到图片的一致性、视频的一致性,总体来说是一个慢工细活,因为有太多太多的细节需要打磨了。
💡 行动指令:如果你想验证一个想法,不要等所有技术都精通了再开始。像我一样,先用笨办法把流程跑通,再一步步优化架构。GitHub 上的开源项目不是终点,而是能力的最好证明。
这个笔记其实是上个月我项目发布1.0版本的时候随手记录的,一直没时间发出来。现在应用已经升级到2.0版本,功能更全、流程更清晰、全栈结构更完善、自动化更系统,后续也会持续分享开发的经历!
目前该项目属于免费内测阶段,有兴趣可以去 Github 看看,也顺便帮忙点下小星星。地址:
https://github.com/rolfie-han/yoyoung-shorts
