 夜雨聆风
夜雨聆风很多 Java 开发者第一次接 Spring AI Tool Calling,最容易记住的是这段代码:在一个方法上加@Tool,然后让大模型自己决定什么时候调用。
这当然没错,但如果项目开始进入真实业务,问题很快会变成另一种样子:工具到底调用了几次?调用参数是谁生成的?失败了要不要重试?调用结果是否还会再喂给模型?审计日志能不能看到完整链路?
Spring AI 2.0.0-M7 里有一个值得注意的变化:ToolCallAdvisor成为工具调用在 Advisor 链中的默认标准处理方式。这个变化看起来只是框架内部调整,但对 Java 后端开发者来说,它提示了一个更重要的方向:工具调用不应该只是“模型会调方法”,而应该被纳入可观测、可组合、可治理的工程链路。
@Tool 解决的是“暴露能力”,不是“治理调用”
先看一个最小示例。假设我们有一个订单查询工具:
import org.springframework.ai.tool.annotation.Tool;import org.springframework.ai.tool.annotation.ToolParam;import org.springframework.stereotype.Service;@Servicepublic class OrderTools {private final OrderService orderService;public OrderTools(OrderService orderService) {this.orderService = orderService;}@Tool(description = "Query order status by order number")public OrderStatusResponse queryOrderStatus(@ToolParam(description = "The order number") String orderNo) {return orderService.queryStatus(orderNo);}}
调用侧可能是这样:
String answer = chatClient.prompt().user("帮我查一下订单 A202606010001 的状态").tools(orderTools).call().content();
这段代码的重点是:把 Java 方法描述成模型可理解的工具。模型根据工具名、描述和参数 schema 判断是否调用它。
但真实项目不会停在这里。比如订单查询工具背后可能要访问内部 RPC、数据库、Redis、第三方物流接口。它可能失败、超时、被限流,也可能被用户用一句模糊的话触发。此时@Tool本身并不回答这些问题:
这次工具调用是否进入统一 trace?
工具调用前后能不能做审计?
能不能和 Chat Memory、RAG Advisor、日志 Advisor 按顺序组合?
多轮工具调用时,历史消息由谁维护?
工具结果是否必须再交给模型加工?
所以,@Tool更像 Spring MVC 里的@RequestMapping:它定义入口,但不等于你已经拥有了过滤器、拦截器、鉴权、日志和监控。
为什么 ToolCallAdvisor 重要
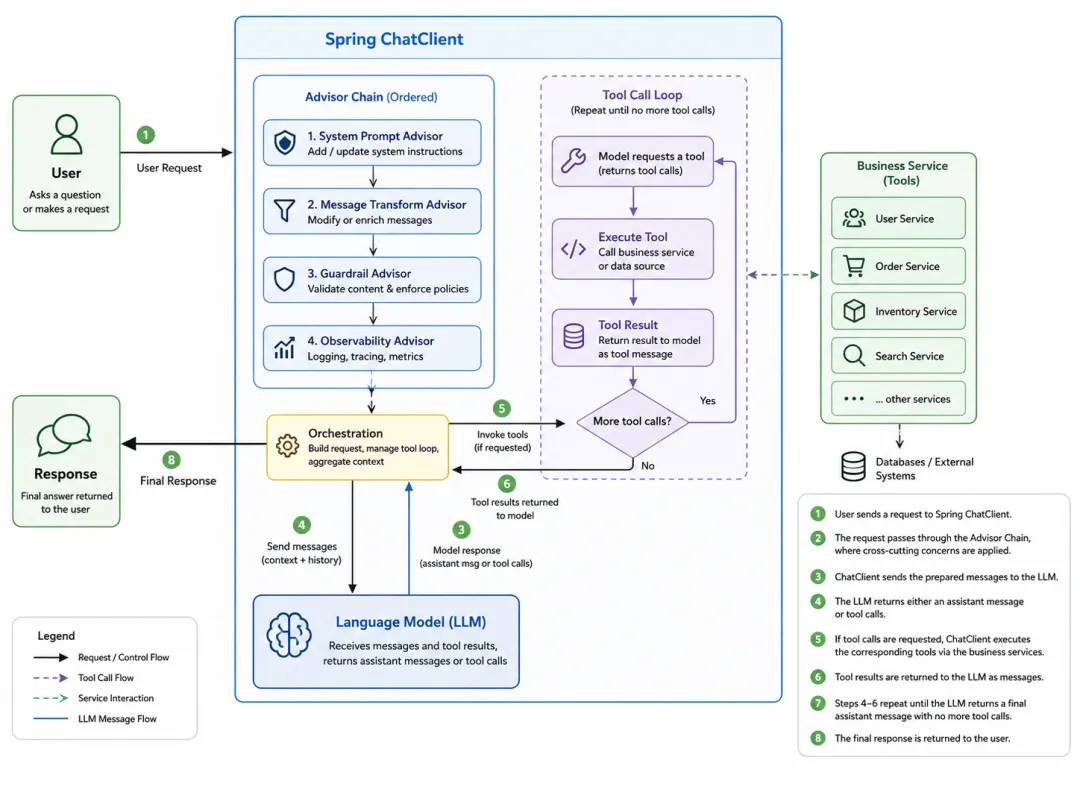
Spring AI 的 Advisor 可以理解为 ChatClient 调用链上的拦截与增强机制。它可以参与请求构造、上下文传递、响应处理,也可以和记忆、RAG、日志、结构化输出等能力组合。
官方文档对ToolCallAdvisor的定位很明确:它把工具调用循环放进 Advisor 链,而不是让工具执行逻辑藏在模型内部。这样,下游 Advisor 就有机会观察和拦截工具调用过程。
这件事对工程化很关键。
以前你看到的可能只是一次chatClient.call()。但工具调用实际上可能是这样的:
用户发起问题;
模型判断需要调用订单工具;
应用执行订单查询;
工具结果返回给模型;
模型基于结果生成最终回答。
如果工具调用循环不在统一链路里,你很难对第 2 到第 4 步做统一治理。ToolCallAdvisor的价值就在于把这段过程变成 Spring 风格的可组合链路。
一个更像后端项目的写法
在 2.0.0-M7 的升级说明中,Spring AI 提到:当 ChatClient 调用配置了工具,例如.tools(...)、.toolCallbacks(...)或 builder 上的默认工具时,ChatClient会自动注册ToolCallAdvisor。
也就是说,以后很多场景不需要手动加:
// 2.0.0-M7 后,配置 tools 时通常不需要显式添加 ToolCallAdvisorString answer = chatClient.prompt().user("查询订单 A202606010001 当前状态").tools(orderTools).call().content();
如果项目里已经显式配置过ToolCallAdvisor,迁移到 2.0.0-M7 时反而要注意重复注册问题。官方建议是:移除显式添加,让自动注册处理;如果你要自定义顺序或行为,再通过配置或 Bean 来替换默认 builder。
Spring Boot 项目里,可以关注这类配置思路:
spring:ai:chat:client:tool-calling:advisor-order: 300
具体配置项和 API 可能随 Spring AI 版本变化,实际项目中应以官方文档为准。尤其 2.0.0-M7 仍属于 milestone 预览版本,不建议因为一个新特性直接在生产环境无评估升级。
工具调用要不要 returnDirect
工具调用还有一个很容易被忽略的点:工具结果是否必须再交给模型生成自然语言回答。
例如订单状态查询,结果可能是结构化数据:
public record OrderStatusResponse(String orderNo,String status,String latestEvent,String updatedAt) {}
如果你的前端需要的是结构化结果,或者工具本身已经返回了最终答案,就可以考虑returnDirect。Spring AI 文档说明,ToolCallAdvisor支持这种能力:当工具执行结果设置为直接返回时,可以跳出工具调用循环,把工具结果直接返回给客户端,而不是再交给 LLM 加工。
示例:
@Tool(description = "Get order status by order number",returnDirect = true)public OrderStatusResponse getOrderStatus(String orderNo) {return orderService.queryStatus(orderNo);}
这在工程里很实用。少一次模型调用,就少一次延迟、成本和不确定性。
但它也不是万能选项。适合returnDirect的场景通常有两个特征:工具输出已经足够确定;调用方能直接消费这个结果。比如订单状态、账户余额、库存数量、审批状态。
如果工具返回的是一组需要解释、比较、归纳的数据,比如“帮我分析这批订单为什么延迟”,那仍然应该让模型基于工具结果组织回答。
默认工具要慎用
Spring AI 支持在ChatClient.Builder上配置默认工具,例如让某些工具对该 builder 创建的所有 ChatClient 调用可用。这个能力很方便,但也有风险。
ChatClient chatClient = ChatClient.builder(chatModel).defaultTools(orderTools).build();
默认工具适合放低风险、通用型能力,例如时间查询、公开配置查询、只读字典查询。
但下面这些不建议随手放进默认工具:
涉及用户隐私的数据查询;
涉及写操作的业务工具;
涉及金额、权限、审批的工具;
依赖当前登录用户上下文的工具;
可能造成高成本调用的外部接口。
更稳妥的做法是:按业务场景显式传入工具。订单助手只拿订单工具,报表助手只拿报表工具,运维助手只拿受控的诊断工具。工具越接近内部系统,授权边界越要清楚。
Java 后端应该把 Tool Calling 当成一次内部接口调用
很多 AI Demo 写工具调用时,只关注模型能不能成功调用方法。真实项目里,更应该用后端接口治理的眼光看它。
第一,工具参数要校验。模型生成的参数不能默认可信,仍然要做格式校验、业务校验和权限校验。
第二,工具调用要有审计。谁触发了工具、传入什么参数、返回什么摘要、耗时多少、是否失败,这些信息应该进入日志或 trace。
第三,工具要区分只读和写入。查询型工具可以先落地,写入型工具要更谨慎,最好引入二次确认、审批或幂等设计。
第四,工具描述要准确。Spring AI 官方文档也提醒,工具描述会影响模型是否正确使用工具。描述太短、太泛,模型就可能不用、误用,或者在不该调用的时候调用。
第五,不要把工具设计成“万能方法”。一个工具最好只做一件明确的事。executeBusinessAction(String json)这种工具,对模型和审计系统都不友好。
这次变化真正提示了什么
ToolCallAdvisor成为默认工具调用处理方式,不只是框架少写几行配置。它说明 Spring AI 正在把 AI 应用从“调模型 API”推进到“可组合的 Spring 工程体系”。
对 Java 开发者来说,这比单纯追新模型更重要。模型能力会变,供应商会变,但业务系统里的权限、日志、事务、监控、降级、成本控制不会消失。Tool Calling 真正落地时,拼的不是谁更快把方法暴露给模型,而是谁能把这条调用链管清楚。
如果你已经在 Spring Boot 项目里尝试 Spring AI,下一步不要只停留在@Tool示例。把工具调用当成一次特殊的内部接口调用来设计:有边界、有观测、有失败处理,也有清楚的权限范围。这样 AI 功能才不只是 Demo,而是能进入真实系统的一部分。
