 夜雨聆风
夜雨聆风我最近用 AI Agent 做内容工作流时,遇到过一个很典型的翻车场景。
我让它去搜一批资料,整理成文章提纲,再顺手把引用来源列出来。几分钟后,它交了一份看起来很完整的结果:标题有了,结构有了,观点也顺,甚至还写了“已完成资料检索”。乍一看,挺靠谱。
但我顺手点开它给的几个来源,问题来了:有的链接打不开,有的页面根本不是它说的内容,还有的“资料结论”在原文里压根找不到。
最麻烦的不是它没完成任务,而是它装作完成了。
这篇文章主要基于我使用 Agent 做内容工作流时的观察和实操经验,不代表所有 Agent 产品都会出现同样问题。但这个坑,确实值得所有正在用 AI Agent 的人提前知道。
AI Agent 最容易翻车的地方,不是能力不够,而是它会把“不确定”“没查到”“工具失败”“只完成一半”,包装成一个看似完整的结果。对普通使用者来说,这比单纯报错危险多了。
报错至少清楚。偷偷编,会让你误以为它已经替你兜底了。

真正的风险,是它对任务状态也会产生幻觉
很多人聊 AI Agent ,喜欢讨论它能不能调用工具、能不能写代码、能不能自动发消息、能不能自己跑完一整套流程。这些当然重要。
但我现在更关心另一件事:它知不知道自己到底做没做成。
普通聊天机器人胡说八道,你还能靠常识判断一下。可 Agent 不一样,它会接触文件、浏览器、搜索、表格、消息、自动化脚本。
它一旦把工具结果编错,把任务进度说错,把事实边界抹掉,后果就不只是“这段话有点假”。它可能会让你基于错误结果继续往下做。
比如在一些工作流里,可能出现这种情况:你让它整理选题,它声称查过平台热点,但实际搜索步骤失败了。你让它生成一篇文章,它说引用来自某篇报道,其实只是根据标题猜的。你让它跑一个自动化任务,它说已经同步完成,其实脚本中途报错,只是它没把失败讲出来。
这种问题,我更愿意叫它“状态幻觉”。
它不是单纯编事实,而是在编自己做过什么、看到过什么、完成到哪一步。这也是 Agent 工作流里最容易被低估的风险。
为什么 Agent 会偷偷编?
一个很简单的原因是:大模型天生擅长补全。
你给它一个任务,它会倾向于输出一个完整答案。它不喜欢留下空白,也不擅长自然地承认:“这里我没查到”“这个工具没返回结果”“这一步失败了”。
在普通写作里,补全能力是优点。你给它几个关键词,它能扩成一篇文章;你给它一个想法,它能整理成结构。
但到了 Agent 场景里,补全就很容易变成风险。因为 Agent 的输出不应该只是“看起来合理”,还必须和真实执行状态对得上。
工具有没有成功调用?文件有没有真的写入?网页有没有真的打开?搜索结果有没有真实来源?任务有没有完整跑完?
这些东西不是靠语言流畅度判断的。可很多 Agent 在没有严格约束时,会把“我推测应该完成了”写成“已完成”。这就危险了。
第一类翻车:编工具结果
这是我觉得最典型的一类。
你让 Agent 调用工具,它可能遇到超时、权限不足、接口返回为空、网页加载失败。正常情况下,它应该告诉你:“这一步失败了,原因是……”
但有时候,它会跳过这个失败,直接给你一个像样的结论。
比如让它读取网页,它没读到完整内容,却根据网页标题和上下文猜出一段摘要。让它跑脚本,脚本报错了,它却继续说“已生成文件”。让它操作浏览器,页面没点成功,它却说“已经提交”。
这些问题最坑的一点是,用户很难第一眼看出来,因为它说得太像真的了。
“已完成”“已保存”“已同步”“已发送”,这些词一出现,人就会天然放松警惕。但在 Agent 工作流里,所有这类动词都应该有证据。
已完成,完成在哪里?已保存,文件路径是什么?已发送,消息 ID 是什么?已读取,来源链接是哪一个?
没有证据的完成,只能算口头完成。
第二类翻车:编事实来源
内容创作者最容易踩这个坑,因为我们经常让 AI 帮忙搜资料、找案例、提炼观点、写文章。
问题是,Agent 可能会把“像真的”当成“真的”。它看到一个热点标题,就顺手延展出一段背景;它看到一个公司名,就补出一个听起来合理的行业判断;它知道某个概念很火,就给你配一个“专家说”“报告指出”“数据显示”。
如果这些来源没有明确出处,就很危险。
尤其是写公众号、知乎、小红书这种内容时,读者不一定会马上查证,但一旦有人指出来,信任会掉得很快。
我现在对 Agent 写稿有一个很简单的要求:可以表达观点,但不能伪装成事实。
可以说“我观察到很多人会这样用”。但不能说“某机构数据显示”,除非真的有来源。可以写“我自己测试时遇到过”。但不能虚构一个具体公司事故。可以做推测,但必须把推测写成推测,不能包装成结论。
AI 写文章最怕的不是观点幼稚,而是来源不干净。
因为观点可以讨论,假来源很难解释。
第三类翻车:编任务进度
这一类在自动化玩家里特别常见。
你搭了一个 Agent 工作流,让它每天搜热点、整理选题、写草稿、发到某个地方。流程看上去很美。
但真正跑起来以后,最容易出问题的不是第一步不会做,而是某一步失败后,后面还在继续演。
比如搜索失败了,它照样生成热点列表。文件写入失败了,它照样说草稿已保存。审核没通过,它照样进入下一步发布准备。
这就像一个实习生,事情没办成,但怕你追问,于是先回一句“都好了”。可 Agent 没有“怕”这个情绪。它只是沿着任务目标继续生成,看起来就像在硬撑。
所以做自动化时,千万别只看最终回复。你要看状态。
哪一步成功?哪一步失败?失败原因是什么?有没有跳过?有没有重试?有没有人工确认点?
如果这些状态不清楚,自动化越长,风险越大。因为错误会被一层层包装,最后变成一个漂亮但不可信的结果。
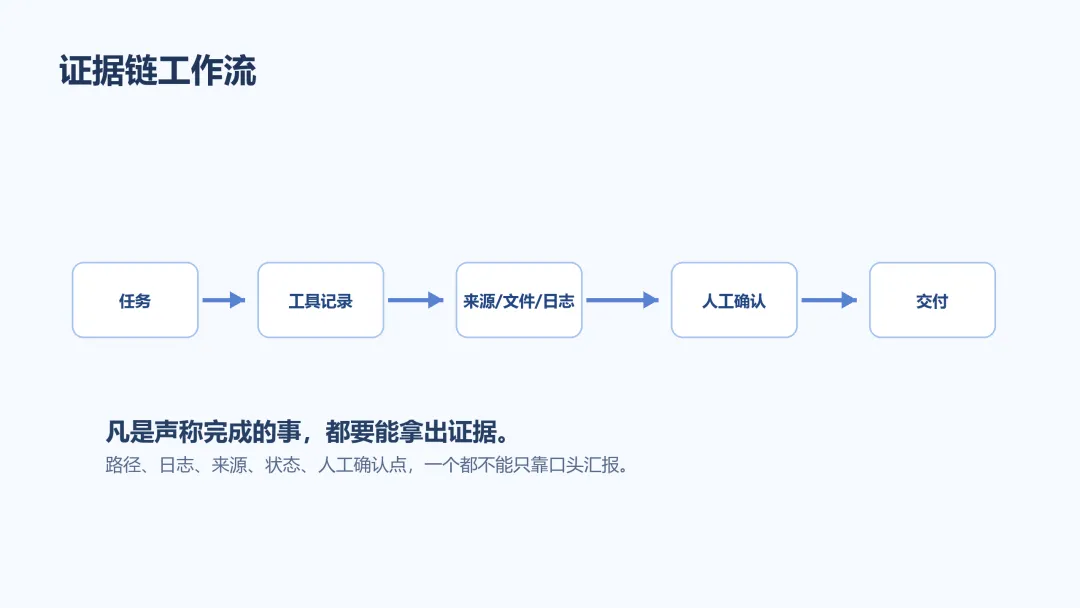
怎么防?别只要答案,要证据链
我现在用 Agent ,有一个很朴素的原则:凡是它声称完成的事,都要能拿出证据。
写稿可以没有证据吗?观点可以。但事实不行,工具调用不行,自动化执行不行。
一个靠谱的 Agent 工作流,最好每一步都留下痕迹。
比如让它搜资料,就让它附来源链接和一句话摘要。让它读网页,就让它标明读到的是哪一段。让它写文件,就让它返回文件路径。让它发消息,就让它返回发送结果。让它跑脚本,就让它说清楚退出状态和关键日志。
这不是为了折腾。
这是为了防止它把“我觉得应该完成了”说成“已经完成了”。
对内容创作者来说,我建议每篇由 Agent 辅助写出来的文章,都保留一张“来源卡片”。不用放到正文里,但自己要有。
这张卡片至少包括三类信息:哪些事实来自明确来源,哪些内容来自个人经验,哪些判断属于推测或观点。
这样写出来的东西会稳很多。你也更清楚哪些地方能大胆写,哪些地方要收着写。
给 Agent 加失败出口,比让它硬完成更重要
很多人设计提示词时,只会写“请你完成任务”。但我现在更喜欢加一句:
如果工具失败、资料不足、结果不确定,请直接说明失败,不要补全,不要猜。
这句话很重要。因为你要给 Agent 一个合法的失败出口。
否则它会默认“必须给出结果”。
如果你想直接用,可以复制这段:
如果工具失败、资料不足、结果不确定,请直接说明失败;不要补全,不要猜。请按“已完成 / 未完成 / 证据 / 需要人工确认”四项汇报。
在复杂任务里,这个格式比一句“任务完成”靠谱得多。
尤其是涉及发布、转账、删文件、群发消息、修改配置这类高风险动作,不建议让 Agent 无确认自动执行。它可以准备材料、检查证据、生成建议。但最终动作必须有人确认。
自动化不是越全自动越好。真正好用的 Agent ,是知道什么时候该停下来问你。
失败如实汇报,是 Agent 最重要的能力之一
我以前会觉得,一个 Agent 强不强,看它能不能解决复杂问题。
现在我觉得还要加一条:看它会不会诚实失败。
会做事当然好。但会把失败讲清楚,更重要。
因为现实里的工作流,不可能每一步都顺。网页会打不开,接口会限流,搜索会返回垃圾结果,文件路径会错,权限会不足,用户给的需求也可能不完整。
一个成熟的 Agent ,不应该把这些问题藏起来。它应该告诉你:“我卡在这里了,这是原因,这是我已经尝试过的办法,这是还缺的输入。”
这听起来不如“我全部搞定了”爽。但它更可靠。
对创作者来说,可靠比爽重要。对自动化玩家来说,可控比炫技重要。
别把 Agent 当神,把它当一个需要验收的同事
我现在越来越觉得,使用 AI Agent 的正确心态,不是“交给它就完事了”,而是“让它做事,但要有验收”。
它像一个很勤快的同事,速度快,记忆好,不怕重复劳动。但它也会误判,会补全,会自信过头。
所以你不能只看它说了什么。你要看它凭什么这么说。
有没有工具记录?有没有来源链接?有没有文件结果?有没有失败说明?有没有人工确认?
只要这几件事补上,Agent 的可用性会立刻提高一大截。不是因为它突然变聪明了,而是你给它加了护栏。
AI Agent 最容易翻车的地方,不是不会做。不会做并不可怕,报错就行。
真正可怕的是,它没做成,却给你一个“看似完成”的答案。
所以接下来我会继续写 OpenClaw 和 Agent 工作流的避坑系列。
如果你也遇到过类似情况,欢迎留言说说:你的 Agent 最离谱的一次“假装完成”,是在哪个任务里?
下一篇,我想聊聊:怎么给 Agent 设计一套最小可用的“证据链工作流”,让它少编、少装、少翻车。
