 夜雨聆风
夜雨聆风OpenClaw 联合 NVIDIA 对 67,453 个 ClawHub 公开插件做了三重安全扫描,结果令人不安:NVIDIA SkillSpector 把近半插件标记为存在 agentic 风险,但最终只有 0.31% 被平台判定为恶意。更关键的发现在于,三种扫描器之间几乎没有共识,81.9% 的风险发现只被一种工具捕捉到。agent 插件生态的安全治理,正式进入「多信号仲裁」时代。
67453 个 skills,过三道安检
2026 年 6 月 1 日,OpenClaw 官方在 X 上发了一条帖子。
"In collaboration with @nvidia, we're open-sourcing a dataset of security scans for 67,453 ClawHub skills on @huggingface"
「我们联合 NVIDIA,在 Hugging Face 上开源了一份针对 67,453 个 ClawHub 技能的安全扫描数据集。」
▲ OpenClaw 官方推文,5.2 万次浏览,421 个点赞
帖子里三个数据点直接抛出来:
NVIDIA SkillSpector 把接近一半的插件标记为存在 agentic 风险 只有 0.31% 被判定为恶意 任何两种扫描器在风险判定上的重合度,不超过 8.5%
看起来只是一个数据集发布。但仔细看这三个数字的组合,问题就来了。
近半被标记,只有 0.31% 恶意——中间那片灰区有多大?
先看数字全景。
OpenClaw 这次扫描动用了三套工具:
1.VirusTotal——传统恶意软件声誉扫描,positive 率 7.75%(5,225 个) 2.静态分析——代码和文本模式风险检测,positive 率 6.57%(4,434 个) 3.NVIDIA SkillSpector——专门针对 agent 场景的语义风险扫描,positive 率48.71%(32,856 个)
最终,平台综合三路信号加上来源校验、元数据和历史记录,给出 verdict(裁决):
- Clean
:绝大多数 - Suspicious
:25,504 个 - Malicious
:206 个,占比约 0.31%
0.31% 看起来不高。但 25,504 个 suspicious——这意味着超过三分之一的插件处在「说它有毒不准确,说它安全也不对」的灰色地带。
▲ OpenClaw 官方博客详细说明了 ClawHub 安全协作的背景和流程
三种扫描器「各说各话」——这才是真正的炸弹
如果三种工具高度一致,这条新闻会变成:「OpenClaw 用三种方法验证了插件安全数据,结果互相印证。」
但实际情况完全相反。
根据 OpenClaw 同步发布的论文《ClawHub Security Signals: When VirusTotal, Static Analysis, and SkillSpector Disagree》:
任意两种 scanner 的 combined positives overlap最高只有 10.4% 三者同时命中的只有468 个,占总量的 0.69% - 81.9% 的风险发现,只被单一 scanner 捕捉到

▲ 官方论文首页,标题直接点明核心发现:三种扫描器「意见不合」
论文的逻辑主轴落在一个判断上:
"Disagreement is the finding, not a defect."
翻译过来:分歧本身就是核心发现,不需要当成缺陷去修复。
说白了,这三种扫描器压根就在看不同的东西。
- VirusTotal
看的是传统供应链风险、恶意软件声誉 - 静态分析
看的是危险 API 调用、shell 模式、密钥泄露 - SkillSpector
看的是 agent 行为意图、权限范围、声明与实际行为的错配
它们各自覆盖了不同的攻击面。所以 overlap 低,恰恰说明 agent 插件面临的风险维度比传统软件更分散、更复杂。
为什么 48% 的 SkillSpector 标记率引发质疑?
社区里讨论最热的一个点:SkillSpector 把近半插件都标记了,这个阈值是否合理?
质疑的逻辑可以理解——如果一个安全工具对接近一半的样本发出警告,它到底是「检测器」还是「噪音源」?
但 OpenClaw 的博客里给了一个关键区分:SkillSpector 的 positive 定义和 VirusTotal 完全不同。VirusTotal 的阳性意味着有已知恶意签名或声誉问题;SkillSpector 的阳性更接近「这个插件有能力做一些超出声明范围的事」。
打个比方:VirusTotal 在找「谁带了刀」,SkillSpector 在标记「谁有能力伤人」。
capability 和 intent,是两条完全不同的轴。
更有意思的是,在 206 个最终被判定为 malicious 的插件里,VirusTotal 命中了 150 个(72.8%),而SkillSpector 只命中了 14 个(6.8%)。反过来,在 25,504 个 suspicious 判定里,SkillSpector positive 占了19,209 个(75.3%)。
这组对比的指向很明确:SkillSpector 擅长标记灰区风险,VirusTotal 擅长抓已知恶意。它们各有盲区,也各有强项。
数据集已上 Hugging Face,MIT 协议开放
OpenClaw 这次把完整数据集放在了 Hugging Face 上,MIT 协议,任何人可以下载使用。
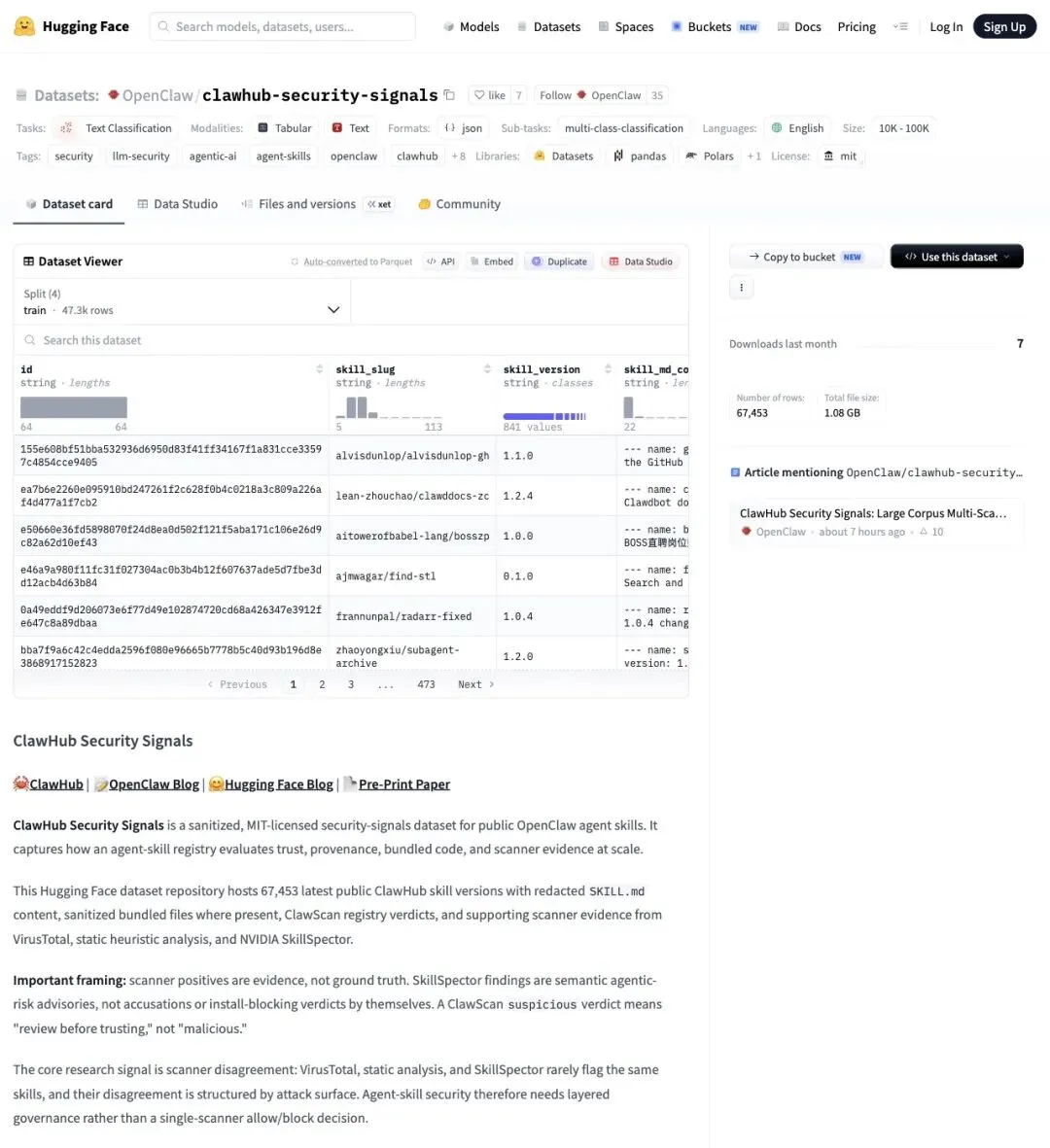
▲ Hugging Face 数据集页面:67,453 rows,1.08 GB,4 个 split
数据集包含四个 split:
- train
:47,300 条 - validation
:10,100 条 - test
:6,750 条 - eval_holdout
:3,370 条
这个 split 结构说明 OpenClaw 的目标远不止发个报告——它在试图把 agent skill 安全做成一个可训练、可评测的社区基准。
论文也明确标注了数据集的边界:这是 sanitized silver-standard dataset(银标准数据集),不是人工标注的 gold standard。研究核心聚焦的是不同检测器之间的分歧模式,至于恶意插件在整个生态里到底占多少,反而排在次要位置。
agent 插件生态正在走传统软件安全的老路
回头看 ClawHub 现在的安全架构:
有registry(注册表) 有Skill Card(插件安全卡片) 有上架前 verification gate(预审机制) 有恶意软件扫描(VirusTotal) 有静态代码分析 有语义风险扫描(SkillSpector) 有来源校验、元数据审计、管理历史 有平台最终 verdict(裁决)
这套东西已经非常像传统应用商店的安全栈——只不过审的对象从 app / package 变成了 agent skill。
传统软件生态走过的路是:先解决「怎么装」,规模大了开始解决「该不该装」,再往后单一安全工具不够,需要平台策略、来源校验、行为分析、社区信誉协同工作。
agent skills 正在走同一条路。OpenClaw 这套数据集,算是把这个进程摊到了台面上。
社区怎么看?三种声音
从推特回复和引用帖来看,讨论大致分成三派。
第一派:把注意力放在 scanner disagreement 上
这批人觉得恶意率占比反而是次要信息,scanner 之间的分歧才是最有价值的发现。代表观点包括:capability 和 intent 应该分开评估;未来安全架构更像 signal stack(信号栈),靠多层信号叠加做判断。
这类观点和论文的核心结论高度一致。
第二派:质疑 SkillSpector 48% 标记率是否过高
他们的担心可以总结为:如果一个扫描器把将近一半样本都标记了风险,它的实际产品价值可能从「拦截器」滑向「解释器」——标记了一堆,但开发者不知道该拿这些标记怎么办。
这个质疑没有标准答案,但它点出了一个现实问题:安全工具的可操作性和覆盖面之间需要平衡。
第三派:直接把结果理解成「扫描器根本没用」
这种解读被讨论得最多,但也最容易误导。论文给出的结论指向完全不同的方向——scanner disagreement 说明需要多层检测协同,单一工具搞不定全貌。
你不能拿任何一种扫描器的输出当最终真相。这是数据给出的最明确信号。
回到这件事本身
OpenClaw 这份数据集的重要性,远超「扫出了多少恶意插件」这件事本身。
真正有冲击力的部分是:它第一次用公开数据证明了,agent 插件的风险定义本身还没有行业共识。三种主流扫描手段看到的风险画面几乎不重叠,每种工具都有大面积盲区。
这份数据集覆盖了 67,453 个插件,用了三种扫描器,结果发现 81.9% 的风险只被一种工具捕捉到。结论很明确:agent 插件生态的安全,靠单一工具解决不了。它需要分层治理,需要多信号仲裁,需要一整套从扫描到裁决的信任流水线。
AI agent 的插件生态,正在从「插件市场」进入「插件市场 + 安全中心」的时代。
— END —
