 夜雨聆风
夜雨聆风Salt Security 在 6 月 1 日发布了一个叫 Salt Code 的东西。
它不是又一个帮你写代码的 AI。
它干的是另一件事:
让 Claude Code、Cursor、GitHub Copilot、Windsurf、Kiro、Codex、Gemini CLI 这些 AI Coding 工具,在生成代码的时候,就按公司的安全规则来。
换句话说,之前是代码写完以后,安全团队再过来扫一遍。
现在是你第一句 prompt 打出去的时候,安全规矩就已经坐在旁边了。


Salt 官方发布页里提到,它预置了几类规则包:
OWASP API Top 10
MCP Security Top 10
LLM Security Top 10
OpenAPI / Swagger 合规
企业自己的自定义安全策略
这事听着有点厂商味。
但里面那个信号挺真实。
以前大家讨论 AI Coding,重点是:
这玩意能不能帮我少写几行代码?
现在企业开始问另一件事:
它写得这么快,谁保证它别把坑也写进去?
"AI 写的代码算谁的?"
"漏洞是模型生成的,锅谁背?"
"面试官问你 AI 项目安全治理,你只答上线前扫一下,还够吗?"
这次就不是抽象焦虑了。
它变成一个很具体的问题:
当 AI Coding 从个人效率工具变成团队默认工具,公司到底该怎么管住它写出来的代码?
鸭鸭说几句不太客气的话。
第一,上线前扫一下,已经太晚了。
以前人写代码,节奏慢。
你写一个接口,提一个 PR,review 一轮,CI 跑一下,安全扫描再补一刀。
虽然慢,但问题还算有地方拦。
AI Coding 不一样。
它一口气能吐出一整个接口、一组测试、一个 MCP Server、几段 OpenAPI 配置。
你让它改个鉴权逻辑,它顺手把参数校验也改了。
你让它接个外部 API,它顺手把 token 放进配置样例里。
这时候只靠最后扫一遍,就像饭店中央厨房配方写错了,等菜都端上桌了才开始查盐放多没多。
能查。
但已经晚了。
第二,AI Coding 会把小错误放大成团队错误。
人写代码的时候,一个初级程序员少写了鉴权,通常只影响他那一个模块。
AI 不一样。
同一个提示词模板、同一套项目上下文、同一个错误示例,可能被几十个人重复使用。
今天一个人让 AI 生成接口没做权限校验。
明天另一个人让 AI 生成后台管理页,也沿用了这个习惯。
后天实习生复制了一份 prompt,继续生成一套类似代码。
问题不是某个人粗心。
问题是坏习惯被工具规模化了。
这也是 Salt Code 这类产品想解决的地方:不指望每个开发者每次都记得安全规则,而是把规则塞到 AI Coding 的工作流里。
让它默认就别乱写。
第三,面试官以后问的不是你会用哪个工具,而是你怎么管这个工具。
2025 年,简历上写会 Cursor、Claude Code、Copilot,可能还算有点新鲜。
到 2026 年下半年,这东西越来越像写熟练使用电脑。
真正能拉开差距的是后半句:
你用 AI 生成代码以后,怎么审?
怎么测?
怎么拦高风险操作?
怎么限制工具权限?
怎么保证它生成的 API 符合公司的鉴权、日志、限流、审计规范?
面试官问这些,不是想听你背一个安全工具名。
他想知道你有没有把 AI 当成生产系统的一部分,而不是当成一个聪明点的自动补全。
AI 生成代码时代,工程师值钱的地方,不是会让模型出活,而是敢对模型出的活签字。
如果面试官现场甩你一段 AI 生成的接口代码,让你说哪里不安全,你会从哪看起?
……
今天鸭鸭和大家分享一道 AI 大模型面试题。
【解释LangChain框架中的Chain和Agent概念,并举例说明各自的应用场景】
回答重点
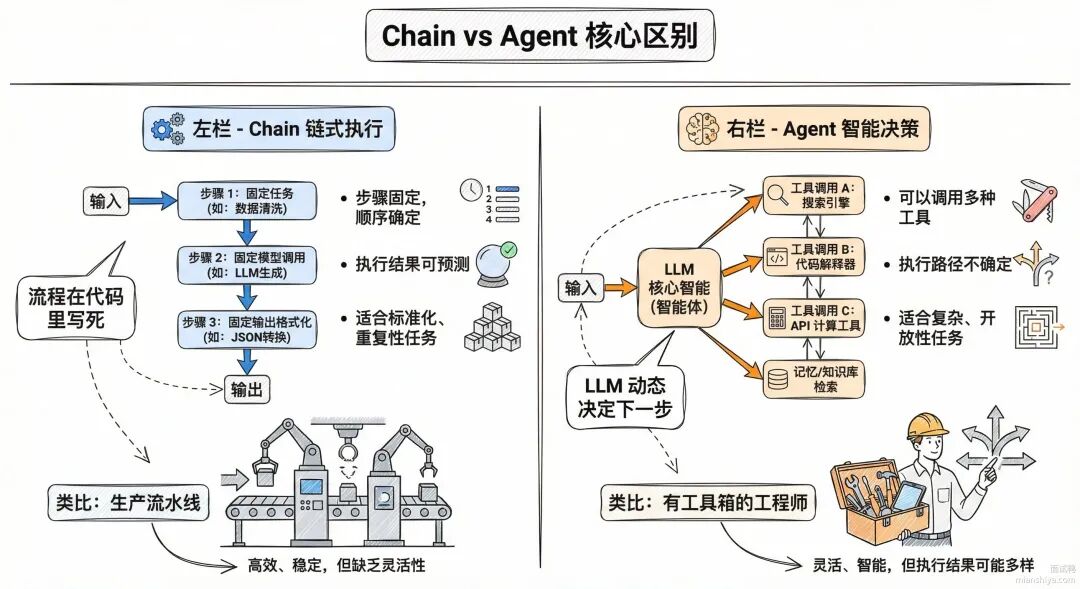
Chain 和 Agent 是 LangChain 里两种完全不同的任务编排方式,核心区别在于执行流程是固定的还是动态决策的。
Chain 是一条预定义的流水线,步骤写死在代码里,输入进去按顺序走完就出结果。比如"拿到用户问题 → 检索相关文档 → 拼成 prompt → 调 LLM 生成答案",每一步干什么、下一步去哪都是确定的。
Agent 是一个能自己思考的智能体,拿到任务后会判断该用什么工具、该怎么一步步推进。它有一个 ReAct 循环:思考当前状态 → 决定下一个动作 → 执行动作 → 观察结果 → 继续思考,直到任务完成。整个过程是 LLM 在做决策,代码只提供工具和约束。
举几个具体场景:
Chain 适用场景:1)RAG 问答系统。用户问题进来,检索 → 拼 prompt → 生成答案,流程固定,Chain 跑起来稳定又快。2)文档摘要。读文档 → 切分 → 分段总结 → 合并,每步都确定。3)数据清洗流水线。格式转换 → 校验 → 入库,不需要 LLM 动态判断。
Agent 适用场景:1)复杂信息查询。用户问"帮我查下 OpenAI 最近的股价走势和新闻",Agent 判断需要先调股票 API 拿数据,再调搜索引擎查新闻,最后整合成答案。2)代码调试助手。拿到报错后,Agent 决定是先看日志、查文档还是搜 Stack Overflow,根据每一步结果动态调整。3)自动化办公。用户说"帮我约下周和张三的会议",Agent 需要查日历、发邮件、等回复,每一步都依赖上一步结果。
扩展知识
Agent 的 ReAct 原理
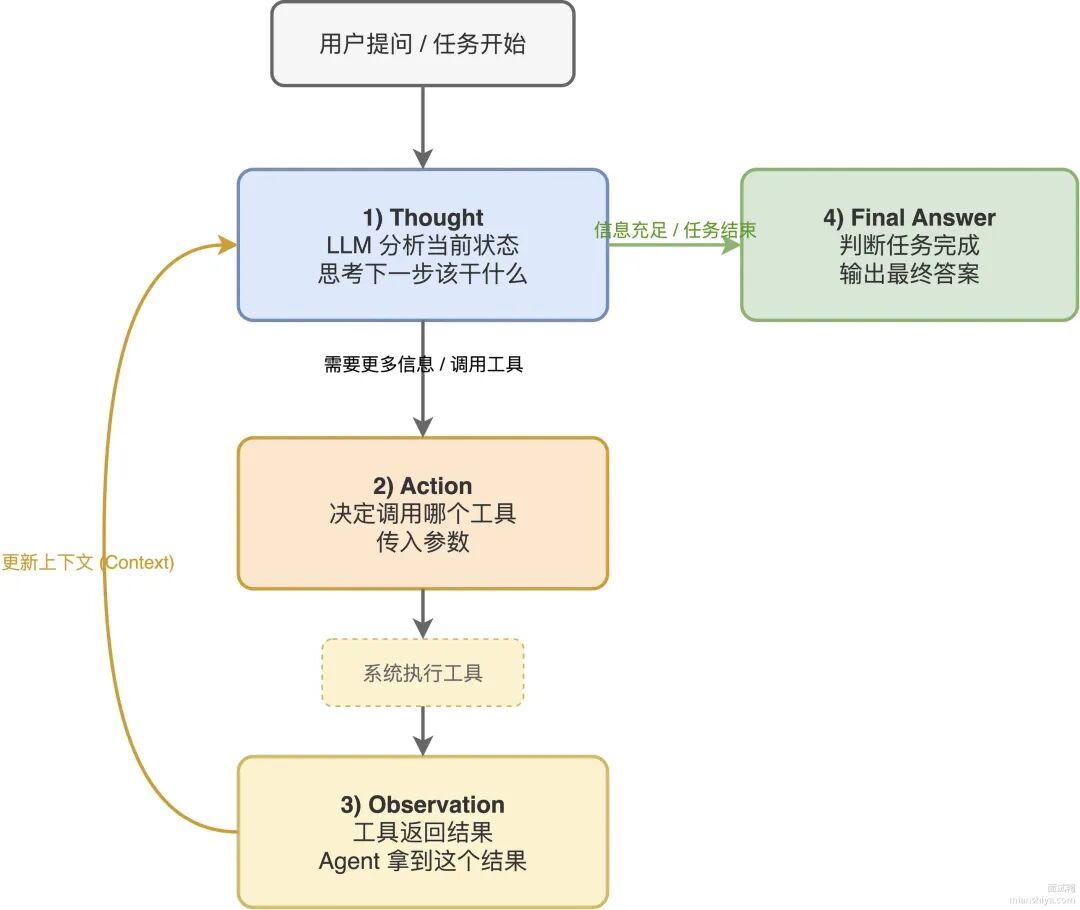
Agent 的核心是 ReAct 范式,全称 Reasoning + Acting。每一轮循环分四步:
1)Thought:LLM 分析当前状态,思考下一步该干什么。2)Action:决定调用哪个工具、传什么参数。3)Observation:工具返回结果,Agent 拿到这个结果。4)重复上述过程,直到 LLM 判断任务完成,输出最终答案。
LangChain 的 Agent 实现会把所有可用工具的描述塞进 prompt 里,让 LLM 根据任务和当前状态选择工具。工具描述写得好不好直接影响 Agent 的决策质量,这也是实际开发中经常要调的地方。
LangChain 的版本演进
LangChain 0.1 之前的 Chain 用继承的方式实现,比如 LLMChain、SequentialChain、RouterChain,每种 Chain 是一个类。代码写起来比较啰嗦,组合起来也不够灵活。
从 0.1 版本开始,LangChain 推出了 LCEL,全称 LangChain Expression Language。用管道符 | 把组件串起来,写法更简洁:
fromlangchain_core.promptsimportChatPromptTemplate
fromlangchain_openaiimportChatOpenAI
fromlangchain_core.output_parsersimportStrOutputParser
prompt=ChatPromptTemplate.from_template("讲一个关于{topic}的笑话")
model=ChatOpenAI()
parser=StrOutputParser()
# LCEL 写法,用管道符串联
chain=prompt|model|parser
result=chain.invoke({"topic": "程序员"})
LCEL 的好处是支持流式输出、自动并行、内置重试,老的 Chain 类慢慢都在往 LCEL 迁移。新项目建议直接用 LCEL 的写法。
Agent 的类型
LangChain 提供了多种 Agent 类型,适配不同场景:
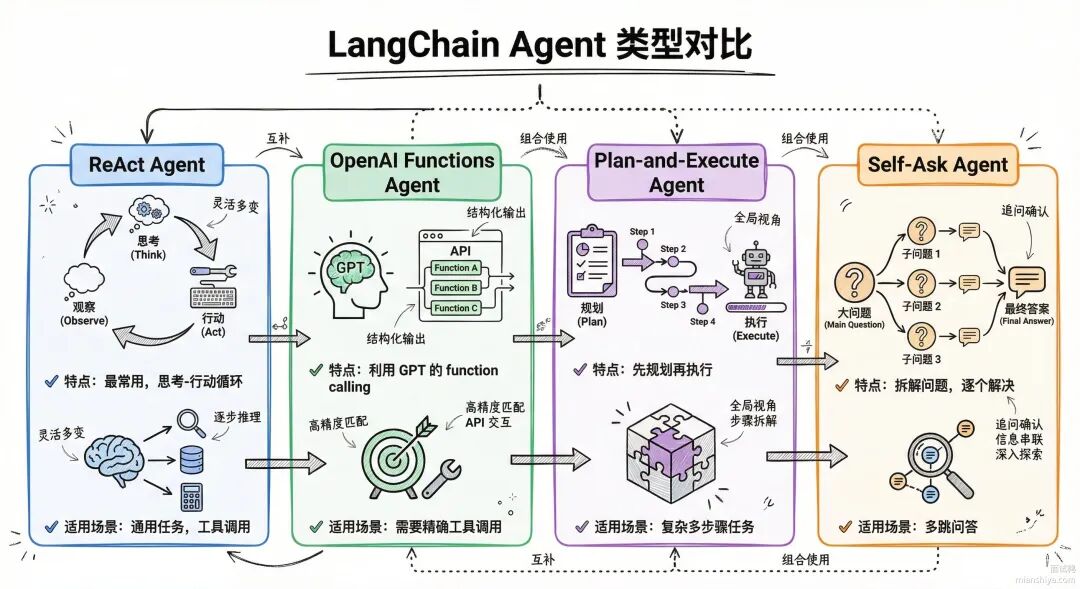
OpenAI Functions Agent 是目前最稳定的选择,因为 GPT-5 的 function calling 能力很强,工具调用的准确率比纯 prompt 高不少。如果用的是非 OpenAI 模型,就得用 ReAct Agent,靠 prompt 引导模型输出结构化的动作。
实际开发中的选型建议
1)能用 Chain 就不用 Agent。Chain 执行路径确定,调试简单,成本可控。Agent 每一步都要调 LLM 做决策,token 消耗是 Chain 的几倍甚至十几倍,而且容易跑偏。
2)Agent 的工具数量别超过 10 个。工具太多,LLM 选择困难,容易选错。可以给工具分组,用路由先判断该用哪组工具。
3)给 Agent 设超时和最大步数。防止死循环,一般限制最多 10-15 轮迭代,超过就强制停止。
4)观察中间步骤。LangChain 支持 verbose=True 打印每一步的思考和动作,调试时一定要开,不然出问题不知道是哪一步挂的。
fromlangchain.agentsimportcreate_openai_functions_agent, AgentExecutor
fromlangchain_openaiimportChatOpenAI
# 创建 Agent
llm=ChatOpenAI(model="gpt-5", temperature=0)
agent=create_openai_functions_agent(llm, tools, prompt)
# 包装成 AgentExecutor,设置最大迭代次数
agent_executor=AgentExecutor(
agent=agent,
tools=tools,
verbose=True, # 打印中间步骤
max_iterations=10, # 最多 10 轮
handle_parsing_errors=True# 解析失败时自动重试
)
和其他框架的对比
LangChain 的 Agent 封装得比较重,学习曲线陡峭。如果只是简单的工具调用,可以直接用 OpenAI 的 function calling,不需要引入 LangChain。
LlamaIndex 更专注于 RAG 场景,数据索引和检索做得更好。如果主要需求是文档问答,LlamaIndex 可能比 LangChain 更合适。
AutoGPT、BabyAGI 这类项目走的是全自动 Agent 路线,LangChain 的 Agent 相对更可控,适合生产环境。
篇幅有限,完整答案可以点击下方进行查阅:
我们精选了近两年的高频面试真题,已经有 10000 多道面试题目啦,由大厂资深面试官手写答案,押题命中率超高!
不仅有传统八股文,场景题、项目题、系统设计题等等应有尽有,还在不断更新中!
目前优惠最低特价 129 元即永久(限时上架)畅看所有面试题和答案,正式运营价格为 399+,不要错过这次优惠哈!
且,现在邀请好友注册并成为会员,还可获得 10% 的分佣🧧!详情见面试鸭拉新邀请有赏规则(网页版面试鸭点击头像查看)
网页端网址:www.mianshiya.com

往期推荐
Leader:“岗位被 AI 替代,降薪 1 万你接受吗?” 我:“不接受。” Leader:“恭喜你,那公司赔你 2N。”
赛博乞讨成真?这泼天的富贵我也想要!
同事:“卧槽,你上班刷BOSS直聘,不怕被发现?“我:“嘘,准备跑路了,听说现在行情很好..“
