 夜雨聆风
夜雨聆风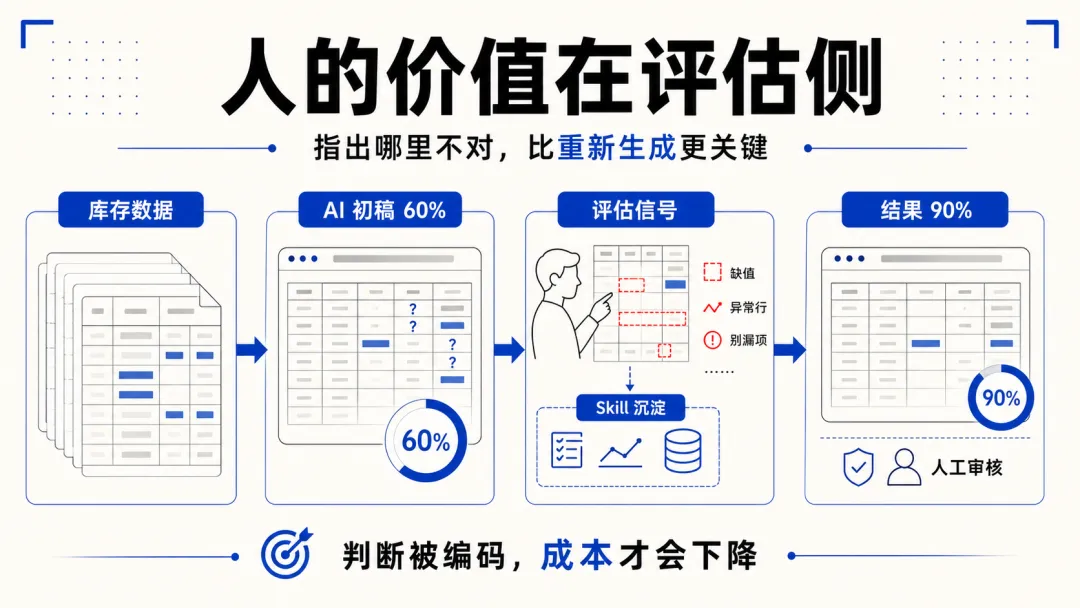
家属做外贸,每个月有两道坎。月初汇总各仓库的上月数据,要 3-5 天;月末做当月库存分析,也要 3-5 天。两件事都有时效要求,加班是常态。
我给她做了一个库存助手。把过去半年的原始数据和最终的汇总分析结果喂给小龙虾,让它学。初始完成度 60%,优化了几轮 skill 之后到 90%,两份工作总耗时压缩到半天。如果把这个助手看成一个员工,月薪至少五千。
整个过程里,有几个体感值得记下来。
她觉得自己的经验不可替代
家属一开始对 AI 不信任。她很自信,说自己不会被替代,因为很多库存整理的隐藏规则和分析方法只有她知道。
这话听起来有道理。她做了几年外贸库存,哪些仓库的数据格式不统一、哪些品类的库存周转要看特殊口径、哪些月份的数据要调整节假日因素——这些东西确实没有写在任何文档里,全在她脑子里。从她的视角看,这些经验是她的不可替代性。
但当我把近半年的原始数据和整理分析结果摆在一起之后,小龙虾学到了 60%。我又优化了几轮 skill,完成度到了 90%。
这说明一件事:在数据搬运和分析类工作中,所谓隐性经验更接近模式匹配,而非创造性判断。从业者觉得经验不可替代,是因为她从来没有外化经验的需求——她就是经验本身,中间过程对她来说是直觉,对外部观察者是黑盒。但输入输出对本身就是经验的显性化载体,规律可以被逆向还原。
不过 90% 之后提升变难了。真正的边缘情况往往不在历史数据里,它们是分布外的异常,需要人的判断力介入。所以库存助手最后留了人工审核环节,这恰好是对瓶颈的正确应对。
优化过程意外地无脑
优化过程让我意外的是它有多无脑。
我对外贸一无所知。优化指令就是这些:"第6行第3列没有值你再检查一下"、"10到15行数据跟其他行不太一样你再检查一下"、"最后核对一下别漏了"。小龙虾拿到这些信号就能自己诊断和修正。
后来想明白了,这件事的本质是评估比生成容易。我不需要知道正确的汇总表长什么样,只需要能看出当前这张表哪里不对。跟梯度下降的逻辑一样——不需要知道最优解在哪,只需要知道当前解的梯度方向。整个优化过程是 harness engineering:指定目标和约束,提供数据维表作为工具,小龙虾实现自我迭代。
这也解释了为什么家属的"隐藏经验"没有她以为的那么不可替代。她掌握的是生成侧的经验——怎么做汇总、怎么做分析——而生成侧的经验可以从数据中学到。真正不可替代的是评估侧的能力:输出哪里不对、什么算一次正确的交付、什么时候该停下来人工介入。这些判断不在历史数据的模式里,它们需要人对业务现实的理解。
每次判断编码进去,翻译成本就降一点
优化完成后,我让小龙虾把整个流程保存下来,命名为库存助手。下次直接用。
虽然本质上这是个 skill,但它已经拥有了一个 B 端产品的雏形。而它的产品化过程,恰好说明了一件事:每次评估判断一旦被编码进 skill——变成规则、校验逻辑、默认配置——下次就不需要人再提供同样的判断,翻译成本递减。
我做的那些优化指令,本质上是在把家属的业务判断翻译成 skill 能理解的评估信号。"第6行第3列没有值"是一条评估规则,"核对一下别漏了"是一条完整性校验。这些信号被编码之后,它们就成了产品的一部分,不再依赖我或家属每次手动提供。翻译一次,成本摊薄一次。
反过来想,如果评估判断不能被显性化和固化,每次都要靠人重新判断,那规模越大成本越高、错误越多。库存助手之所以能从 60% 迭代到 90%,正是因为每次评估信号都被沉淀下来了。如果每次都从零开始,它永远停在 60%。
人的价值不在训练 AI,在判断 AI 哪里不对
做完库存助手之后,我给家属的建议是:她的价值要从"能完成库存的汇总和分析",转变为"能训练一个小龙虾去完成库存的汇总和分析"。
现在我觉得这个建议可以再推一步。训练的有效性取决于评估能力的质量。她真正的价值不在于"能训练小龙虾完成库存汇总",而在于"能准确判断小龙虾的输出哪里不对",并且把每一次判断编码进系统,让翻译成本递减。前者是操作技能,后者才是 AI 时代真正持久的竞争优势。
评估能力越精准,AI 的迭代效率越高,翻译成本下降越快。而评估能力如果不能被显性化和固化,就无法规模化。人的位置应该站在评估侧,而不是生成侧。
