 夜雨聆风
夜雨聆风黄仁勋这次拿出的,不只是一颗芯片
RTX Spark 背后,是个人电脑从“工具箱”变成“AI同事”的开始

黄仁勋每次站上发布会,大家都会盯着那几个词:算力、GPU、数据中心、AI工厂。
但这一次,真正让我觉得有意思的,不是英伟达又把性能往上推了一截,而是它把一件以前只属于服务器和云端的事情,往普通人的电脑里推。
这件事叫 RTX Spark。
如果只看名字,它像是一颗新芯片。
但如果顺着英伟达的发布逻辑往下看,它更像是一个信号:AI 不打算只待在云端了。它要进电脑,进文件夹,进创作软件,进你的日常工作流。
过去我们说“用 AI”,大多数时候其实是在浏览器里打开一个网页,或者在手机里打开一个 App。真正思考和计算的地方,在远处的数据中心。你的电脑只是一个入口。
RTX Spark 想改的,就是这个关系。
它想让电脑自己拥有更强的 AI 能力,让一部分原来必须交给云端的工作,回到本地完成。
这篇文章的核心判断 RTX Spark 的关键,不是简单让电脑更快,而是让电脑开始具备本地 AI Agent 能力。未来的电脑不只是你打开软件干活的工具,而可能变成一个能理解任务、调用应用、整理文件、协助创作的 AI 同事。 |
先别急着看参数,先看这件事的方向。
四十年来,个人电脑的基本逻辑几乎没变。
你要写文章,就打开文档。
你要修图,就打开图片软件。
你要剪视频,就打开剪辑软件。
你要查资料,就打开浏览器。
所有事情都是人来拆,人来找软件,人来复制粘贴,人来判断下一步。
AI 出现以后,我们多了一个聊天窗口,但底层流程还是老样子:人继续在不同软件之间来回搬运。
RTX Spark 真正想做的,是让电脑从“被动工具”变成“主动执行者”。
你给它一个目标,它理解你的文件、调用软件、组织流程,先替你做出一版结果,然后你再判断和修改。
这听上去像科幻,但英伟达和微软这次讲的“Windows 原生个人 Agent”,本质上就是这个方向。
所以我说,这次发布不能只当芯片新闻看。它其实是在给下一代 PC 定义一个新身份。

参数当然也重要,但别把文章写成参数清单。
英伟达官方公布的信息里,有几个数字必须记住。
RTX Spark 最高提供 1 Petaflop AI 性能,最高 128GB 统一内存,采用 Blackwell RTX GPU,拥有 6144 个 CUDA 核心和第五代 Tensor Core,并通过 NVLink-C2C 连接到 20 核 NVIDIA Grace CPU。
它还被官方描述为可以在本地运行 120B 参数级大模型,支持高达 100 万 Token 上下文。
这些数字听起来很硬。换成人话,就是它不是为了让 Word 打开更快,也不是为了让网页滚动更顺滑。它真正服务的是本地 AI 任务。
比如本地跑 Agent。
比如本地读你的文件。
比如本地生成视频、处理 3D 场景、跑代码助手、做图片生成。
再比如,在不把大量私人资料上传到云端的情况下,让 AI 帮你完成更复杂的工作。
这才是 128GB 统一内存、1 Petaflop AI 性能这些参数背后的真正意义。
你可以把它理解成一个变化:以前电脑的价值主要看 CPU、显卡、屏幕、续航;以后高端电脑的价值,还要看它能不能成为你的本地 AI 工作台。
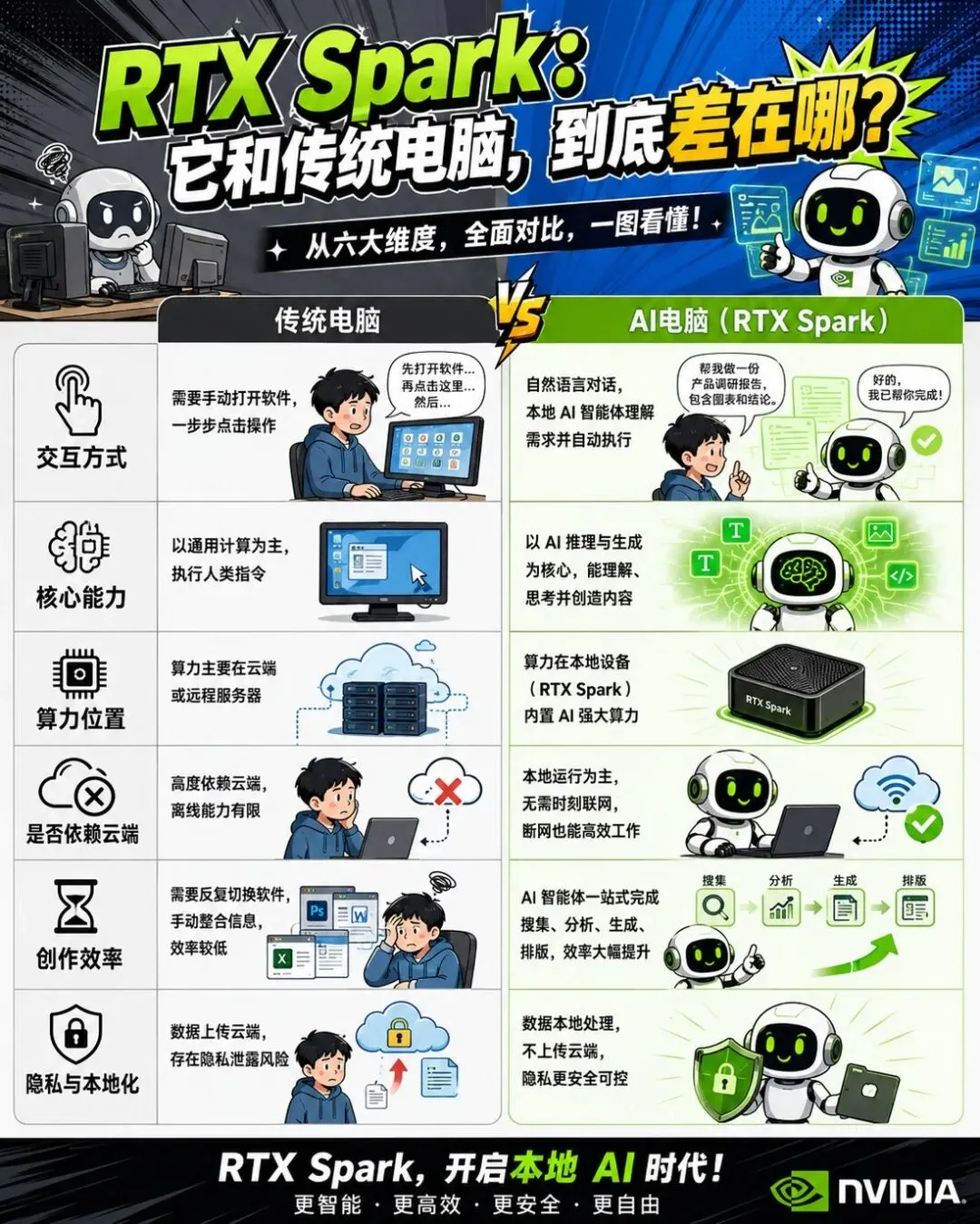
传统电脑和 AI 电脑,差别到底在哪里?
最简单的说法是:传统电脑等你操作,AI 电脑开始理解任务。
传统电脑里,软件是一个个孤岛。你在这个软件里生成一点东西,再复制到另一个软件里改,再导出,再上传,再让另一个工具继续处理。
AI 电脑的理想状态,是把这些孤岛串起来。
你不是告诉它“打开哪个软件”,而是告诉它“我要完成什么结果”。
这背后会带来几个变化。
• 交互方式会变:从点击菜单,变成用自然语言描述目标。
• 软件边界会变:软件不只是给人点按钮,也要能被 Agent 调用。
• 隐私逻辑会变:一部分敏感资料可以留在本地处理。
• 创作流程会变:图片、视频、代码、文档、3D 资产会更容易被串成一条线。
• 电脑竞争会变:不再只是跑分、轻薄和续航,还要比谁的 AI 工作流更顺。
这就是为什么我说 RTX Spark 的意义,不是让 PC 多一个卖点,而是让 PC 重新变得重要。
过去几年,很多人觉得手机和云服务才是主角。
但如果 AI Agent 要理解你的文件、操作你的软件、处理你的私有资料,电脑很可能重新成为个人 AI 的核心入口。

把它放到整张 AI 地图里看,位置就更清楚了。
未来的 AI 计算,大概率不是一个答案。
不是全部上云,也不是全部本地。
更可能是三条路线并存。
路线 | 优势 | 短板 | 适合谁 |
本地 AI 电脑 | 隐私更强、延迟更低、可深度连接本地文件和软件 | 硬件成本高,生态还在早期 | 创作者、开发者、企业专业用户 |
云端大模型 | 模型强、更新快、开箱即用 | 依赖网络,数据上传,长期成本不低 | 普通用户、研究者、轻量使用者 |
普通电脑 | 价格低、生态成熟、日常办公够用 | 本地 AI 能力弱,复杂工作流效率低 | 预算有限、轻度办公学习用户 |
所以 RTX Spark 并不是要马上取代云端大模型。
它更像是把 AI 的一部分能力从云端拉回桌面。
以后真正成熟的体验,很可能是云端负责最强模型和大规模推理,本地负责隐私任务、个人文件、实时交互和跨应用执行。
这叫云边协同。
也是我认为未来三年最值得看的方向。

但别把它吹成马上改变所有人的神器。
这一点必须讲清楚。
第一代 AI 电脑,一定会有不少现实问题。
价格不会低。
软件适配不会一步到位。
续航、发热、噪音、稳定性,都要等真实产品出来以后验证。
更重要的是,普通用户还没有真正形成“用 Agent 操作电脑”的习惯。
很多人现在连提示词都不会写,更别说让 Agent 安全地调用本地文件和应用。
所以短期内,RTX Spark 最先打动的,不是普通家庭用户,而是三类人。
• 做 AI 应用和本地模型的开发者。
• 做视频、3D、设计、图片生成的重度创作者。
• 重视隐私和内部资料处理的企业用户。
普通用户现在不一定要买,但一定要看懂。
因为今天高端用户先用上的能力,往往几年后会下沉到普通设备里。
当年独立显卡、SSD、高刷屏、AI降噪、视频剪辑加速,都是这么来的。
更大的棋,不在 RTX Spark 一颗芯片。
如果把 Vera Rubin 一起看进去,英伟达的野心就更明显了。
Vera Rubin 是面向 AI 工厂的系统。官方说它包含七颗新芯片、五种机架系统,用来支撑预训练、后训练、测试时扩展,以及实时 Agent 推理。
这和 RTX Spark 是两条线。
一条线在云端,建更大的 AI 工厂。
一条线在桌面,把个人 AI 电脑做起来。
这才是英伟达真正厉害的地方。
它不只是卖 GPU。
它在做一整套 AI 基础设施:数据中心有 Rubin,个人电脑有 RTX Spark,中间还有网络、存储、软件栈、CUDA、RTX、Agent 运行环境。
你看懂这一点,就会明白为什么英伟达现在不只是芯片公司。
它更像是在定义 AI 时代的计算底座。
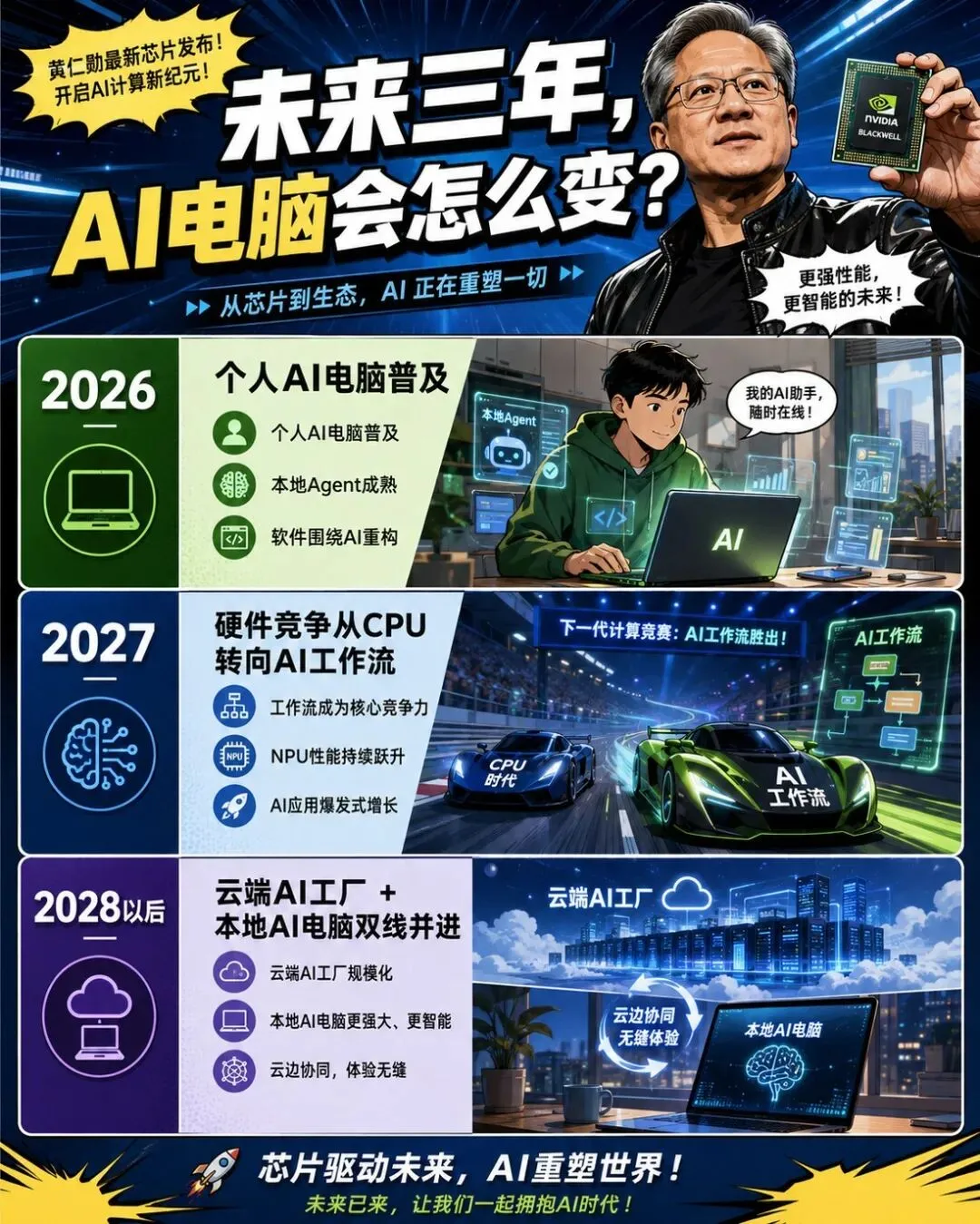
未来三年,我给的判断是
2026 年,更像是 AI 电脑的落地年。
首批产品出来,开发者、创作者和高端用户会先试水。市场真正要看的,不是发布会参数,而是真机体验:能不能稳、能不能省电、软件能不能跟上、Agent 到底有没有用。
2027 年,AI 电脑会开始影响 PC 选购逻辑。
到时候消费者不只问 CPU、显卡、内存,还会问:这台电脑能不能跑本地模型?能不能处理我的私有资料?能不能加速视频生成?能不能支持更强的 Agent?
2028 年以后,云端 AI 和本地 AI 的分工会越来越清楚。
云端继续负责最强模型、大规模训练、海量推理。
本地负责个人数据、实时响应、跨应用任务和隐私场景。
真正成熟的 AI 体验,不会是非云即本地,而是云端和本地一起工作。
芯片只是入口。
更重要的是,电脑正在从“人操作机器”,走向“人管理 AI 帮手”。
以前我们买电脑,是买一个工具箱。
以后我们买电脑,可能是在买一个能长期协作的个人 AI 工作台。
你可以不急着买第一代产品。
但你不能看不懂这个趋势。
因为一旦电脑开始理解任务、组织流程、调用软件,很多行业的工作方式都会被改写。
内容创作者会变。
程序员会变。
设计师会变。
企业办公也会变。
这才是黄仁勋这次发布真正值得关注的地方。
不是一颗芯片有多强。
而是个人 AI 电脑时代,真的开始往现实里走了。
