 夜雨聆风
夜雨聆风
📱 7 Parts
👉 向右滑动
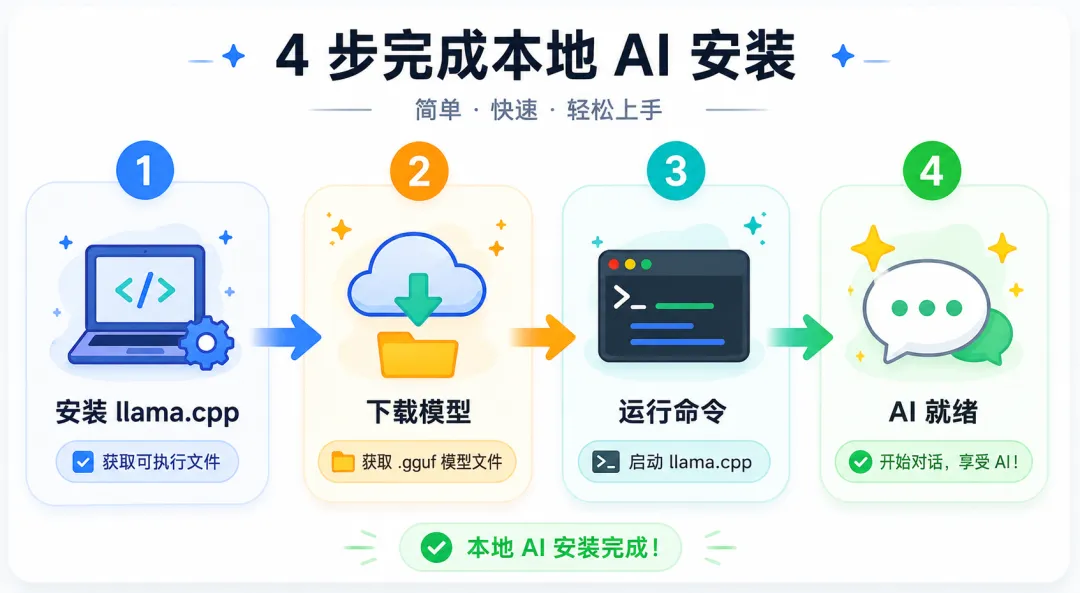
开始之前
"你需要准备什么"
准备macOS 安装
"最简单的方式"
安装Windows 安装
"两种方法任选"
安装Linux 安装
"开发者首选"
安装下载模型
"去哪里找模型"
配置第一次运行
"跑起来了!"
实战常见问题
"遇到报错怎么办"
排错开始之前:你需要准备什么
- ✅ 一台电脑 — macOS / Windows / Linux 都行
- ✅ 8GB+ 内存 — 16GB 更舒适
- ✅ 5GB 硬盘空间 — 装软件 + 下载模型
- ✅ 能访问 GitHub — 或者用国内镜像
- ✅ 20 分钟耐心 — 第一次装可能慢一点
不需要:编程基础、GPU、付费账号、复杂配置。只要会复制粘贴命令就行。
macOS 安装:最简单的方式
macOS 是最省心的平台,Apple Silicon(M1/M2/M3/M4)还有 Metal 加速加成。
方法一:Homebrew 一键安装(推荐)
打开终端(Terminal),复制粘贴:
brew install llama.cpp 等它跑完,就装好了。真的就这么简单。
没装 Homebrew? 先装这个:`/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"`
方法二:从源码编译(想要最新版)
# 1. 克隆仓库 git clone https://github.com/ggerganov/llama.cpp cd llama.cpp # 2. 编译(Apple Silicon 自动启用 Metal 加速) make # 3. 验证安装 ./main --version Homebrew 方式适合 99% 的人,省事 源码编译适合想用最新功能的开发者 Apple Silicon 会自动启用 Metal GPU 加速,不用额外配置 编译完成后可执行文件在当前目录,直接 ./main运行
Windows 安装:两种方法任选
Windows 用户有两条路:下载预编译版本(小白友好),或者自己编译(开发者路线)。
方法一:下载预编译版本(推荐)
- 1打开 llama.cpp 的 GitHub Releases 页面:
https://github.com/ggerganov/llama.cpp/releases
- 1找到最新版本,下载
llama-xxx-bin-win-xxx.zip
【截图:GitHub Releases 页面下载链接】
- 1解压到任意文件夹(比如
C:\llama.cpp)
- 1打开 PowerShell 或 CMD,进入解压目录:
cd C:\llama.cpp main.exe --version 看到版本号就说明成功了。
方法二:用 CMake 编译(有 Visual Studio)
# 1. 克隆仓库 git clone https://github.com/ggerganov/llama.cpp cd llama.cpp # 2. 创建构建目录 mkdir build cd build # 3. 配置和编译 cmake .. cmake --build . --config Release # 4. 可执行文件在 build\bin\Release\ 目录下 cd bin\Release main.exe --version NVIDIA 显卡用户:想用 CUDA 加速,编译时改成 `cmake .. -DLLAMA_CUBLAS=ON`,前提是装了 CUDA Toolkit 11.7+。速度能提升 5-10 倍。

Linux 安装:开发者首选
Linux 用户基本都是从源码编译,灵活性最高。
基础安装
# 1. 安装依赖(Ubuntu/Debian) sudo apt-get update sudo apt-get install build-essential git # CentOS/RHEL 用这个 # sudo yum groupinstall "Development Tools" # 2. 克隆仓库 git clone https://github.com/ggerganov/llama.cpp cd llama.cpp # 3. 编译 make # 4. 验证 ./main --version 【截图:Linux 终端编译成功】
GPU 加速配置
- ✅ NVIDIA GPU(CUDA) — `make LLAMA_CUDA=1`,速度提升 10 倍+
- ✅ AMD GPU(ROCm) — `make LLAMA_HIPBLAS=1`
- ✅ Intel GPU — `make LLAMA_SYCL=1`(实验性支持)
CUDA 加速示例:
# 确保已安装 CUDA Toolkit nvcc --version # 编译时启用 CUDA make LLAMA_CUDA=1 # 运行时指定 GPU 层数(-ngl 参数) ./main -m model.gguf -ngl 32 -p "Hello" Linux 编译最灵活,可以精确控制编译选项 NVIDIA 用户记得加 LLAMA_CUDA=1,性能提升明显AMD 用户用 LLAMA_HIPBLAS=1没有 GPU 也能跑,CPU 推理速度也不慢
下载模型:去哪里找?
llama.cpp 本身只是个"引擎",还需要下载模型才能用。就像你装了播放器,还得下载电影才能看。
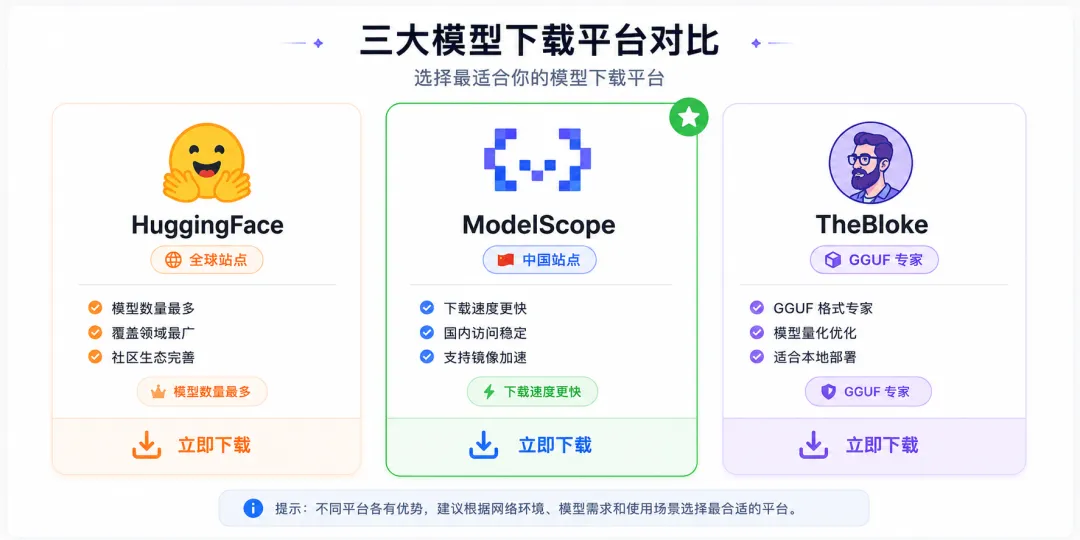
推荐下载源
- ✅ HuggingFace — 国外主流,模型最全(需要科学上网)
- ✅ ModelScope — 国内镜像,速度快,推荐国内用户
- ✅ TheBloke — HuggingFace 上的大神,专门转换 GGUF 格式模型
新手推荐模型(按需选择)
重要:一定要下载 GGUF 格式的模型,文件名通常是 `.gguf` 结尾。量化版本选 `Q4_K_M` 或 `Q5_K_M`,性价比最高。Q4 更省内存,Q5 质量更好。
下载方式
方法一:浏览器直接下载(最简单)
- 1打开 HuggingFace 或 ModelScope
- 2搜索模型名(比如
Qwen2.5-7B-Instruct GGUF) - 3找到
.gguf文件,点击下载 - 4保存到一个固定目录(比如
~/models/或C:\models\)
【截图:HuggingFace 模型下载页面】
方法二:命令行下载(推荐,支持断点续传)
# 安装 huggingface-cli pip install huggingface-hub # 下载模型(自动断点续传) huggingface-cli download TheBloke/Qwen2.5-7B-Instruct-GGUF \ qwen2.5-7b-instruct.Q4_K_M.gguf \ --local-dir ./models 方法三:国内用户用 ModelScope(速度快)
# 直接在 modelscope.cn 搜索模型 # 页面上有详细的下载命令,复制粘贴就行 第一次运行:跑起来了!
模型下载好了,现在让它说第一句话。
最简单的命令
# macOS / Linux ./main -m models/qwen2.5-7b-instruct.Q4_K_M.gguf -p "你好,请介绍一下自己" -n 128 # Windows main.exe -m models\qwen2.5-7b-instruct.Q4_K_M.gguf -p "你好,请介绍一下自己" -n 128 参数说明:
-m:模型文件路径 -p:你的提示词(prompt) -n:生成最多多少个 token(128 大概是 100 个汉字)
回车,等几秒,你会看到 AI 开始一个字一个字蹦出来回答。
【截图:终端运行 llama.cpp 输出对话】
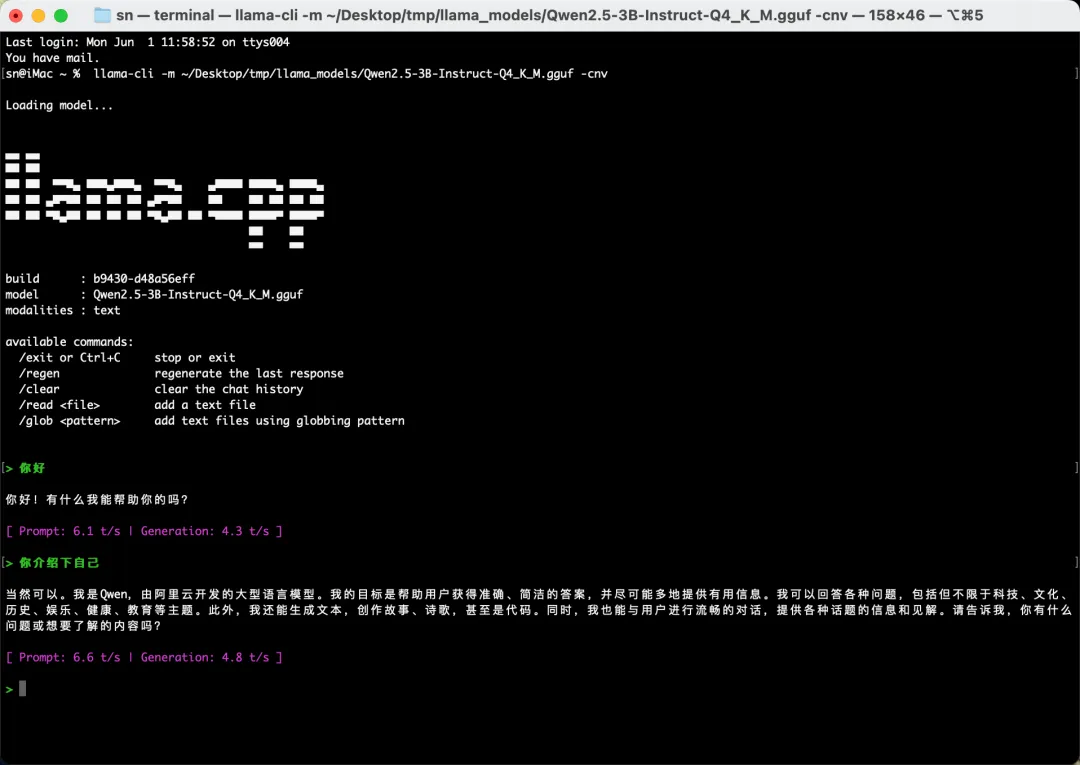
交互式对话模式(更好用)
单次问答太麻烦?试试交互模式,可以一直聊下去:
./main -m models/qwen2.5-7b-instruct.Q4_K_M.gguf \ -n 256 \ -c 2048 \ --color \ -i \ -ins 参数说明:
-n 256:每次生成最多 256 tokens -c 2048:上下文长度 2048(记忆更长的对话) --color:彩色输出,好看 -i:交互模式 -ins:指令模式(适合聊天模型)
现在你可以一直和 AI 对话了,输入问题按回车,它就会回答。想退出按 Ctrl+C。
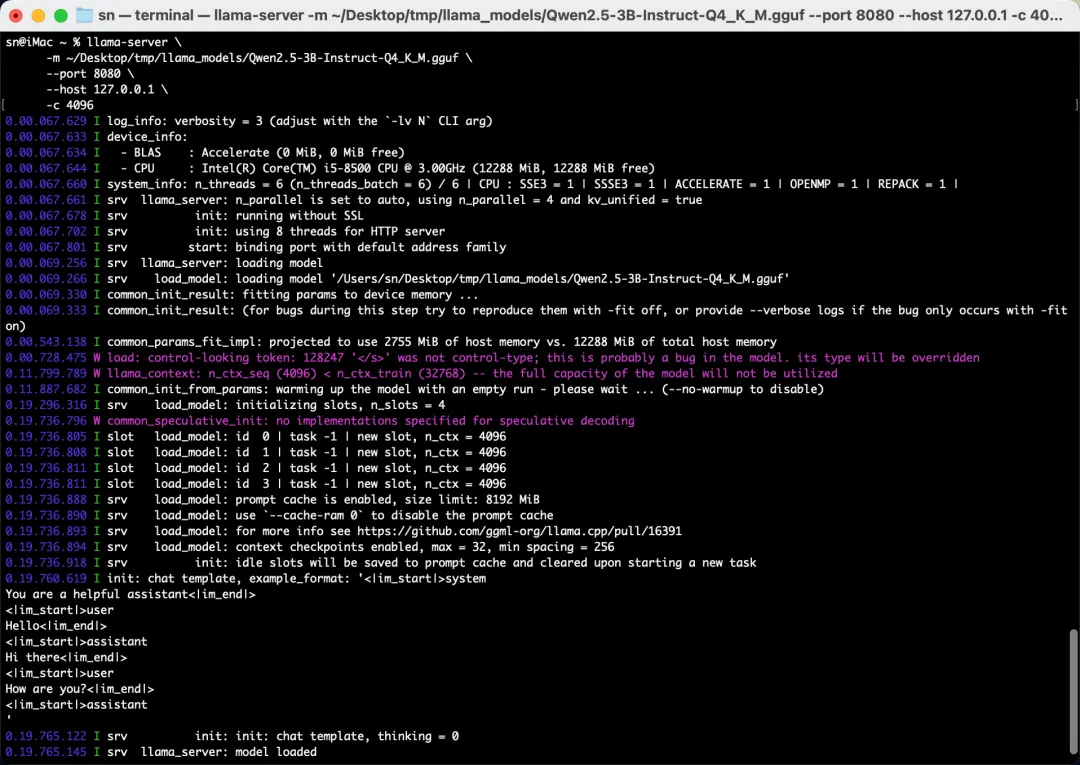
启动 HTTP 服务器(进阶玩法)
想让其他程序调用?启动服务器模式,就有了一个本地 AI API:
./server -m models/qwen2.5-7b-instruct.Q4_K_M.gguf \ --host 0.0.0.0 \ --port 8080 \ -c 4096 然后用 curl 测试:
curl http://localhost:8080/completion \ -H "Content-Type: application/json" \ -d '{"prompt": "你好", "n_predict": 128}' 兼容 OpenAI API:服务器模式提供 `/v1/chat/completions` 接口,可以直接替换 OpenAI API 的地址,很多工具都能无缝对接。
常见问题:遇到报错怎么办
❌ 问题1:error loading model: invalid model file
原因:模型格式不对,可能下载的是旧版 GGML 格式,或者文件损坏。
解决:
- ✅ 确保下载的是 `.gguf` 文件(不是 `.bin` 或 `.ggml`)
- ✅ 重新从 HuggingFace 或 ModelScope 下载
- ✅ 检查文件大小是否正确(7B Q4 模型应该是 4GB 左右)
- ✅ 用 `ls -lh` 或 `dir` 确认文件完整下载
❌ 问题2:failed to allocate memory
原因:内存不够,模型太大了。
解决:
- ✅ 换更小的模型(3B 代替 7B)
- ✅ 用更激进的量化版本(Q4 代替 Q5,Q3 代替 Q4)
- ✅ 减少上下文长度 `-c 1024`(默认是 2048)
- ✅ 关闭其他占内存的程序(浏览器、IDE)
❌ 问题3:速度太慢,一秒只出几个字
原因:没启用 GPU 加速,或者 CPU 线程数不够。
解决:
# macOS(Apple Silicon)— 启用 Metal 加速 ./main -m model.gguf -ngl 32 -p "test" # Windows/Linux(NVIDIA)— 启用 CUDA 加速 ./main -m model.gguf -ngl 32 -t 8 -p "test" # 纯 CPU 优化 — 增加线程数 ./main -m model.gguf -t 8 -p "test" 参数说明:
-ngl 32:把 32 层卸载到 GPU(Metal/CUDA),数字越大用 GPU 越多 -t 8:使用 8 个 CPU 线程(根据你的 CPU 核心数调整)
速度参考:Apple M1 跑 7B Q4 模型,启用 Metal 后能达到 30-50 token/s。Intel i7 纯 CPU 大概 10-15 token/s。
❌ 问题4:macOS 编译报错 xcrun: error
原因:没装 Xcode Command Line Tools。
解决:
xcode-select --install 等它装完(大概 5 分钟)再编译。
❌ 问题5:Windows 找不到 main.exe
原因:编译后文件在 build\bin\Release\ 目录下,不在根目录。
解决:
cd build\bin\Release main.exe --version 或者把这个目录加到系统 PATH,以后就能直接用 main.exe 了。
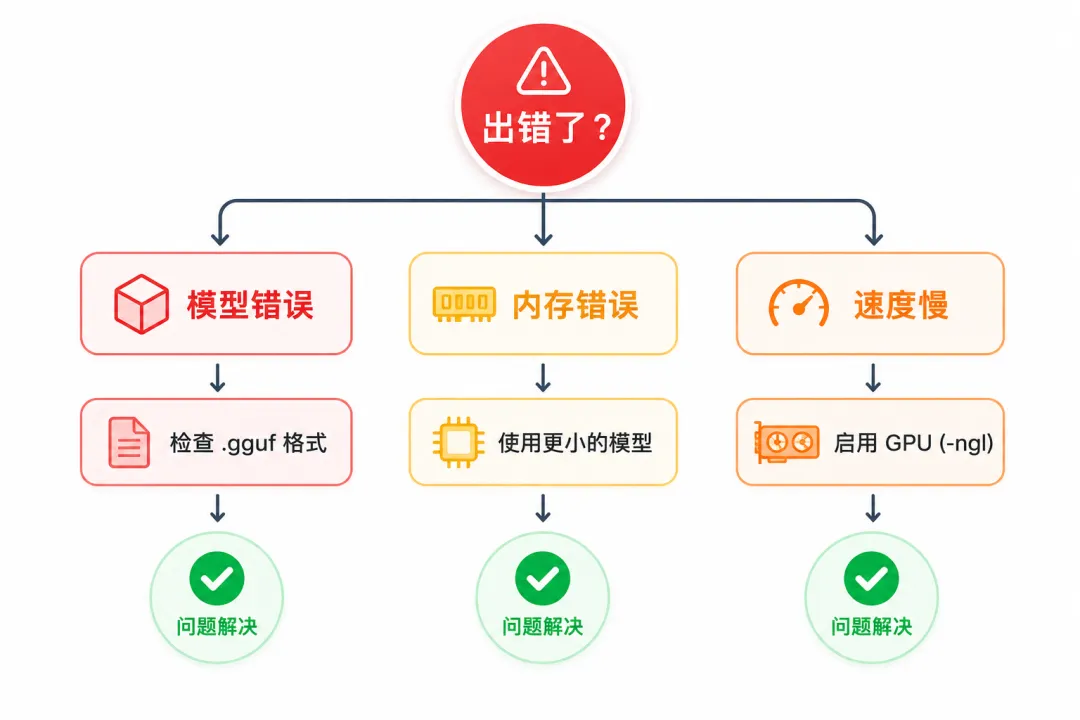
90% 的问题是模型格式不对或内存不够 速度慢先检查是否启用了 GPU 加速(-ngl 参数) 遇到编译错误先确认依赖装全了 实在不行,macOS 用 Homebrew,Windows 下载预编译版本 记住: .gguf格式 +Q4_K_M量化 = 最佳选择
下一步:让它更好用
现在你已经跑起来了,但这只是开始。下一篇我会讲:
- ✅ 如何调参数 — 温度、top-p、重复惩罚,让回答更符合你的需求
- ✅ 接入聊天界面 — 不想用命令行?装个 Web UI,像用 ChatGPT 一样
- ✅ 本地 RAG — 让 AI 读你的文档、PDF、代码库,变成你的私人知识库
- ✅ 性能优化 — 怎么让它跑得更快、更省内存,榨干硬件性能
恭喜你,现在你有了一个完全属于自己的 AI,不花钱、不联网、不审查。
*跑起来了吗?点个在看让更多人看到 👇*
— 完 —
