 夜雨聆风
夜雨聆风一、 什么是知识库与RAG?
当前主流大模型所掌握的知识,主要来源于公开互联网的通用数据,对于企业内部文档、专属产品手册或个人隐私信息,它们完全无法访问,因而难以提供精准响应。知识库正是为突破这一限制而设计——它如同一个专属的“数字档案馆”,用于集中存储和管理非公开的、领域特定的结构化与非结构化资料,如PDF、Word文档、网页内容、数据库记录等。
当知识库建立后,如何让 AI 有效调用其中内容?这就依赖 RAG(检索增强生成) 技术,可形象地理解为一场“开卷考试”:
检索:当用户提出问题(例如:“我们的 A 产品保修期是多久?”),RAG 系统会即时从知识库中精准定位与问题最匹配的文本片段。
增强:将这些检索到的上下文片段作为“参考资料”,动态注入大模型的输入上下文。
生成:大模型融合其固有的通用语义能力与新增的专属知识,输出更准确、有据可依、贴合实际的答案。
过去构建此类系统需深度依赖LangChain等底层框架,配合Python编写前后端服务,开发周期长、技术门槛高,熟练开发者通常需耗时1–2周。如今,Dify已将整个流程封装为一站式平台,仅需几分钟即可完成部署,且全栈开源、免费可用。
在Dify平台上,用户可通过直观的图形界面,直接上传文档构建知识库,并通过拖拽组件配置完整的RAG流程。无需编写一行代码,即可快速搭建出能“读懂”你私有数据的智能问答助手或客服机器人,真正实现AI为专属业务赋能。
二、创建知识库
进入Dify首页,点击左侧导航栏中的 “知识库” 菜单,即可跳转至专属的知识库配置中心,开启你的私有知识管理之旅。
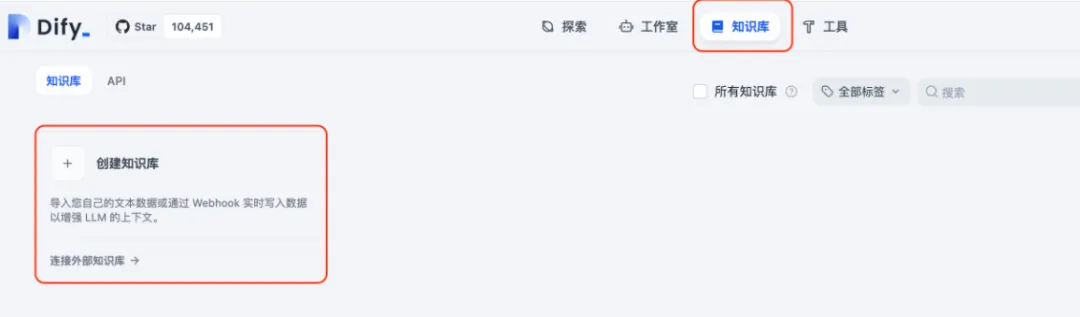
创建知识库时,需手动上传专属文档,Dify全面支持多种文件格式,仅需三步即可完成配置:首先选定数据来源,接着进行文本切分与清洗,最后系统自动完成处理。
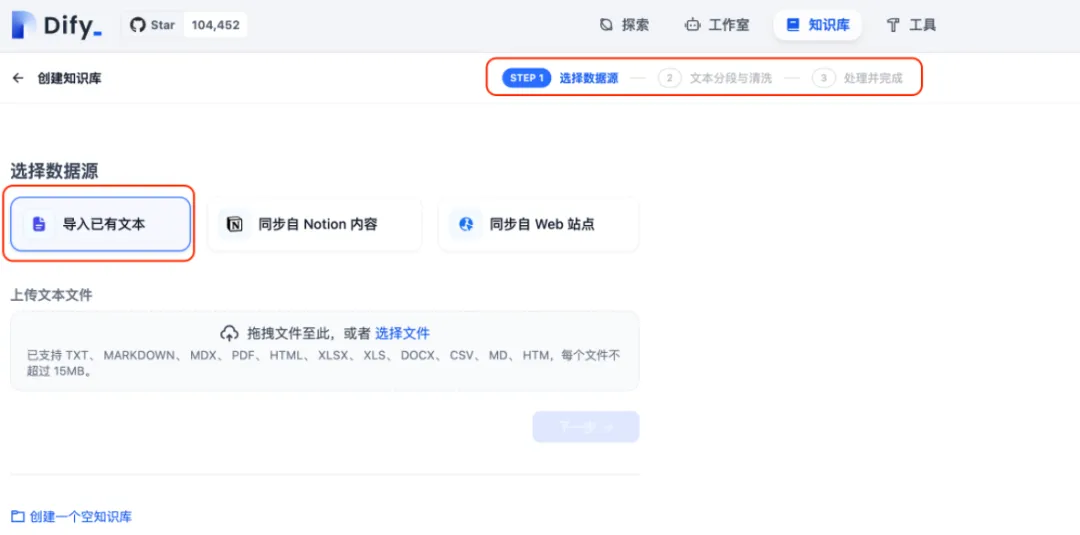
当前Dify支持多种常见文件格式,包括PDF、TXT、MD、Word、CSV、HTML等,上传方式灵活便捷——只需将文件拖拽至中央区域,或点击按钮手动选择即可。例如,我们选取一份记录成龙电影作品的Word文档进行上传。
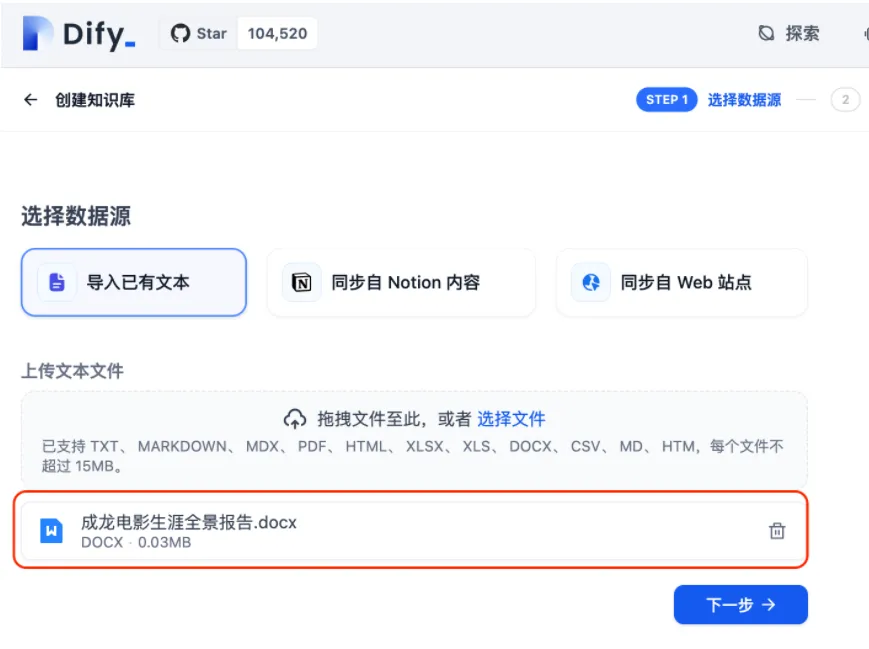
直接点击“下一步”后,将进入数据清洗界面,构建知识库的核心在于对内容进行分段切分,随后完成向量化处理,接着执行检索操作,最终对检索结果进行排序,如下图所示:
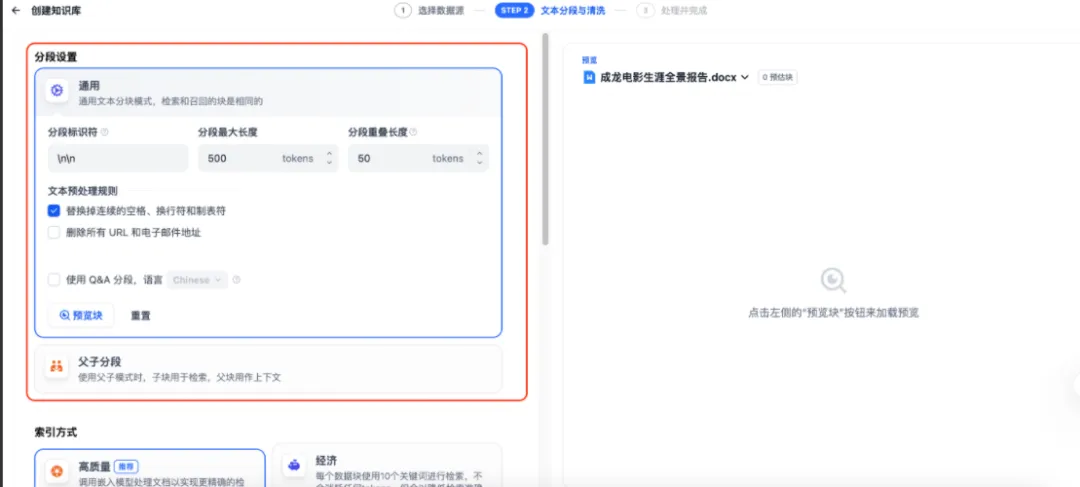
到这里,无需调整设置,直接使用默认选项即可,除非文档篇幅过长,或你有精细化清洗的需求,常规场景下默认配置完全够用。(若文档中包含明确的问答对形式内容,可启用Q&A分段模式。)
点击“预览块”,即可查看Dify自动完成的文档分段效果,索引策略建议选择“高质量”模式。随后,系统将自动执行Embedding模型的向量化处理与索引检索流程。
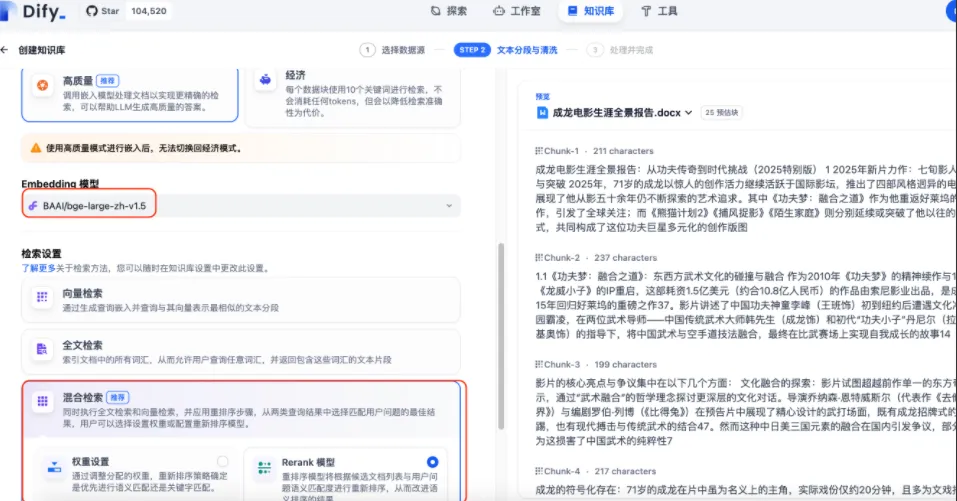
这里选择age-large-zh-v1.5作为Embedding模型,因当前语料均为中文文档,需匹配 zh 语言版本;检索策略上采用混合检索,其综合召回率与精准度表现更优;其余检索参数暂保留默认配置,若后续问答效果未达预期,再针对性优化调整即可。
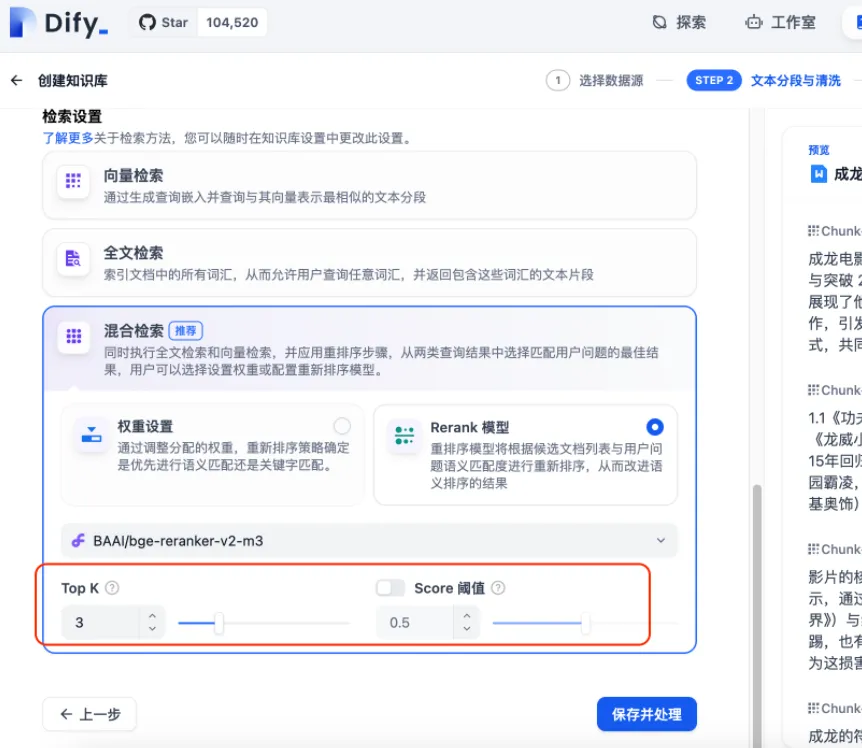
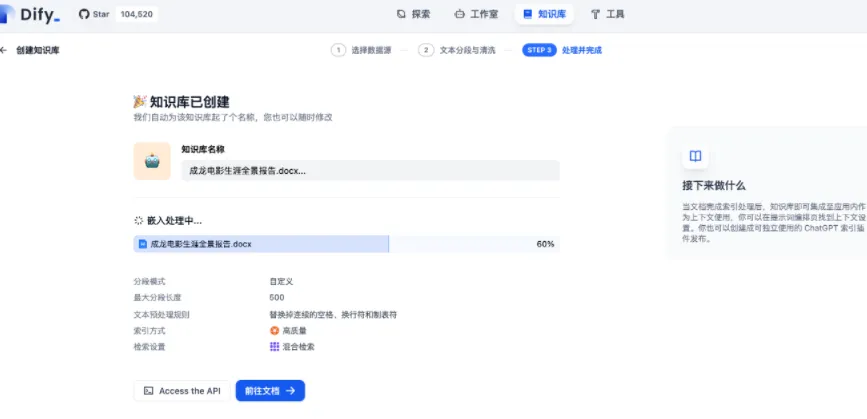
点击“保存并处理”后,系统将自动完成知识库的构建流程,至此,你的专属知识库即已准备就绪。
点击文档链接,即可查看已上传至知识库的专属内容。
三、创建应用
接下来,将智能体的大模型与已构建的知识库进行关联,正式创建新应用。
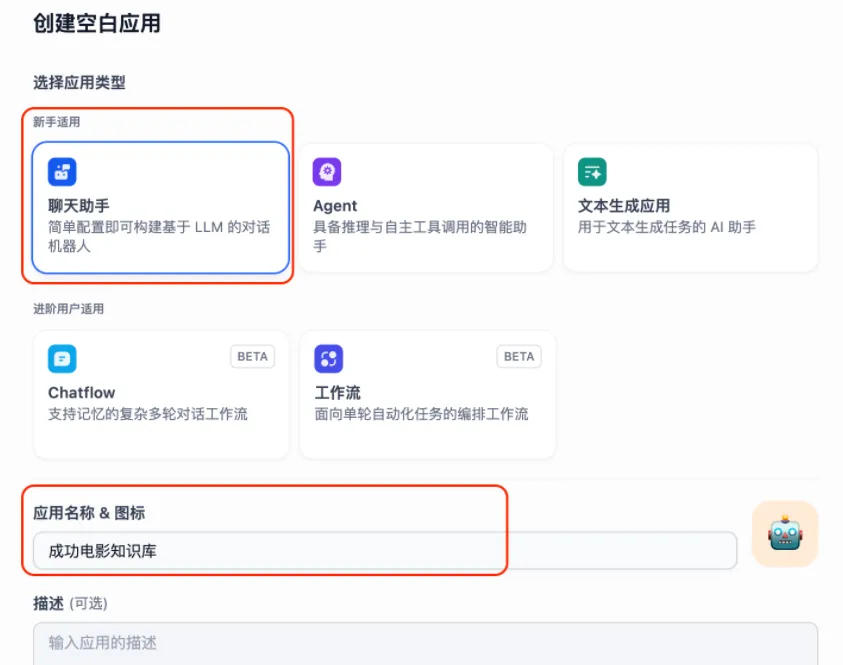
点击创建后,在知识库选项中选择“添加”,并从列表中选取我们已构建的知识库——“成龙电影生涯全景报告”。
点击“添加”后,当前应用即可成功绑定此前创建的知识库。由于本项目旨在构建一个基于知识库的问答型聊天机器人,需对大模型的提示词进行针对性配置(提示词的设置方法已在前文详述,具体可参见下方图示)。
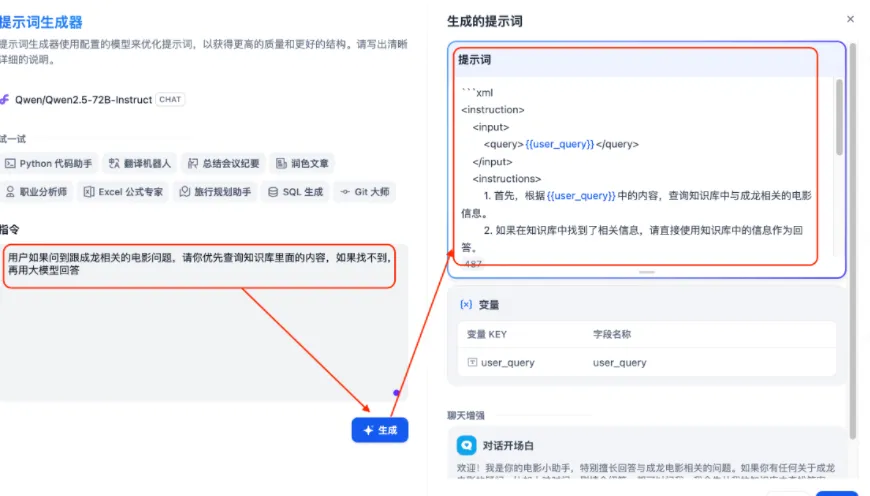
点击应用后,可移除 {{user_query}} 这一变量,当前无需使用。
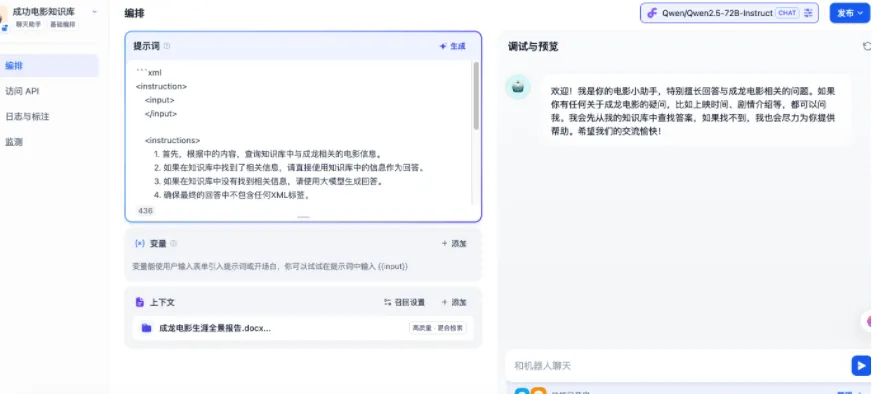
进入调试与预览界面后,可直接输入问题进行测试,例如从已上传文档中摘取一句原话,验证系统能否准确召回并生成对应答案。

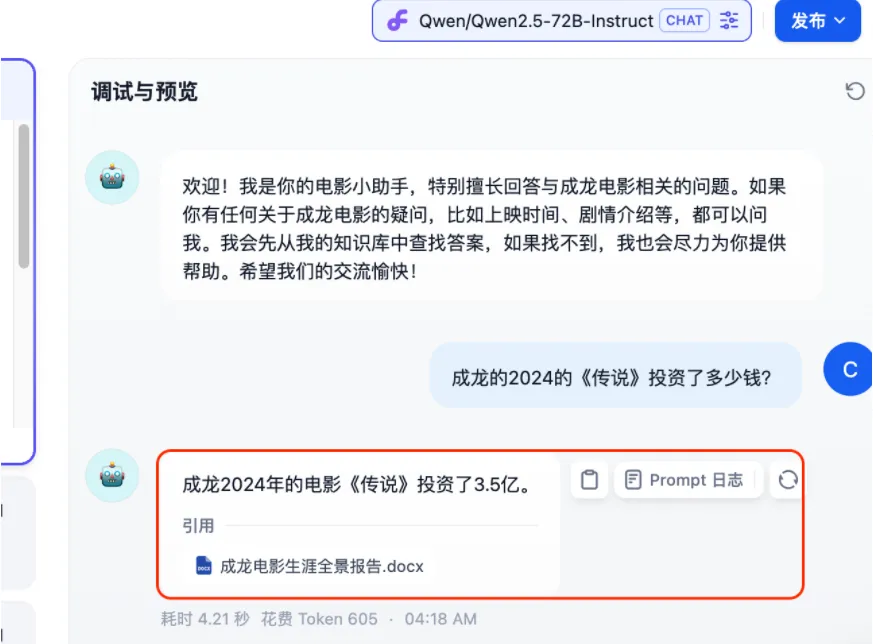
是的回答准确,效果令人满意,不妨再尝试其他问题,例如:

针对这个问题,我的提问结果非常准确,点击发布即可。
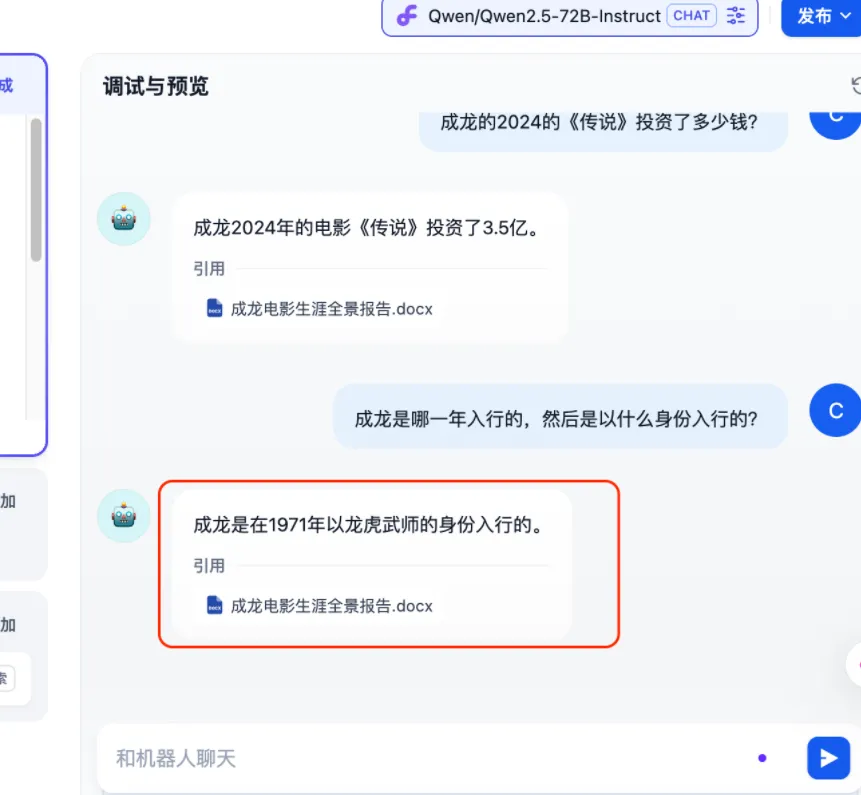
效果确实不错,这个知识库的应用场景极其广泛,既能用于个人场景,也能支撑企业级需求,toB 和 toC 通通适用,值得我深入学习并动手实操。
