 夜雨聆风
夜雨聆风
昨天我发了一篇PDF技能的基础用法,讲了合并、拆分、转Word。这些是基础玩法。
说到PDF,其实最绕不开的坑是PDF扫描件识别不了。
现实中,尤其是工作中,会遇到很多扫描件——合同是扫描件、发票是扫描件、客户发来的资料是扫描件、政府公文也是扫描件。
而扫描件常常无法被提取文字,也无法转成word文档。是PDF操作中的老大难!
有办法解决吗?
答案是肯定的。
WorkBuddy中的PDF技能+OCR技能就能完美解决这个问题,是PDF操作中的最有价值的部分。
今天就用这篇文章讲讲WorkBuddy的PDF技能+OCR节能在实际生活中的应用。
一、扫描件为什么烦人
扫描件说白了就是一张图片,包在PDF壳子里。
你看到的文字,机器看到的只是一堆像素点。不能复制、不能搜索。
想改合同里一个日期,你得重新打印盖章扫描。
我有个朋友做商务,每天收一堆扫描合同,每次核对条款都要对照纸质件手打。用他的话说:"我就想让它变成能复制的文字,这要求不过分吧?"
不过分。OCR就是干这个的。
二、OCR要单独装一个技能
PDF技能负责合并、拆分、转Word——但识别文字这事它干不了,得靠OCR。
在动手之前,先装好OCR技能:
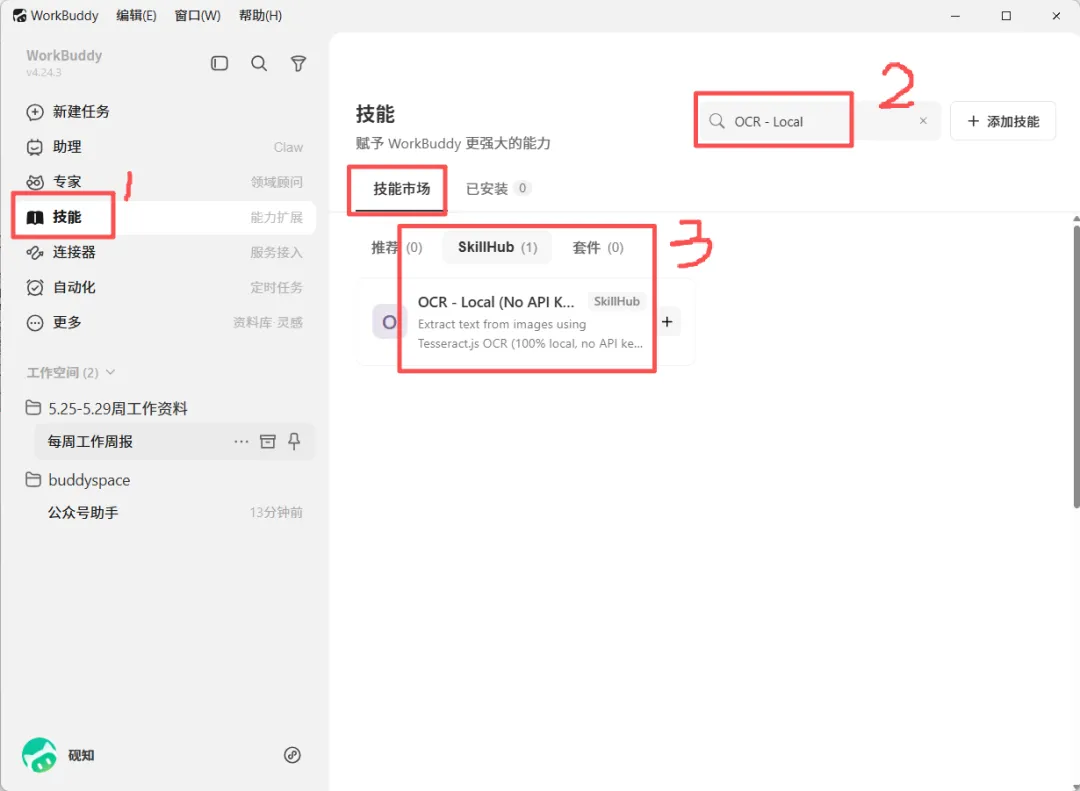
安装步骤:点WorkBuddy左侧的技能,在搜索框中搜“OCR - Local”,然后点“SkillHub”标签,下面就会出现这个技能。点击技能左侧的“+”进行安装。
上一篇已经安装好了PDF,再加上今天的OCR,两个技能齐活,下面所有的指令都能用。
场景1:扫描件变成可搜索的PDF
别人发给你扫描件,你想搜个关键词都搜不了。直接对WorkBuddy说:
"帮我把这份合同扫描件做OCR,输出成可搜索的PDF"
它会自动识别图片上的文字,生成一份文字层和原图保留的新PDF。你Ctrl+F就能搜,别人也能直接复制文字。
场景2:提取文字到记事本
只想把文字拿出来用,不要PDF格式?
"把这份会议纪要扫描件的文字提取出来,存成TXT"
识别完直接给纯文本,粘贴到邮件、文档、周报都行。每页扫描件大概2-5秒完成,十几页的合同一两分钟出结果。
场景3:中英文混合识别
发票上经常中英文混排,报销单上又有数字又有汉字。WorkBuddy默认中英文一起识别,不用额外设置。你直接说需求就行。
三、批量处理——一次搞定一堆文件
办公室最常见的场景就是月初报销,桌面上十几份发票扫描件等着处理。单份搞定太慢,WorkBuddy能一次处理一批。
批量OCR
"把桌面上所有PDF扫描件全部做OCR,输出到报销文件夹"
十几份发票,一句话全部识别完,不需要一份一份说。
先合并再识别
"把这5份合同扫描件先合并,再做OCR,最后提取文字"
三步合一,从扫描件到可复制的完整文本,一口气搞定。
批量加水印+加密
识别完有点产出了,还要防泄露?
"对识别后的文件批量加上'机密'水印,再设置打开密码123456"
处理完自动加保护,不用二次操作。
四、PDF技能完整能力表
合并拆分转Word那篇打基础,这篇补上OCR和批量,PDF技能完整的能力长这样:
以上功能,装好PDF技能+OCR - Local技能就能全覆盖了。
五、怎么装
如果你还没装PDF skill,在WorkBuddy对话框里输入 :帮我安装PDF。简单到一句话就行。
搭配OCR - Local,上面所有功能全都能实现,能帮你解决解决工作中很多难题。
基础篇讲合并拆分转Word,这篇讲OCR和批量处理,两篇加起来基本覆盖了日常PDF会遇到的所有问题。
不管你是收合同的、做报销的、整理资料的,装这一个PDF技能就够了。
