 夜雨聆风
夜雨聆风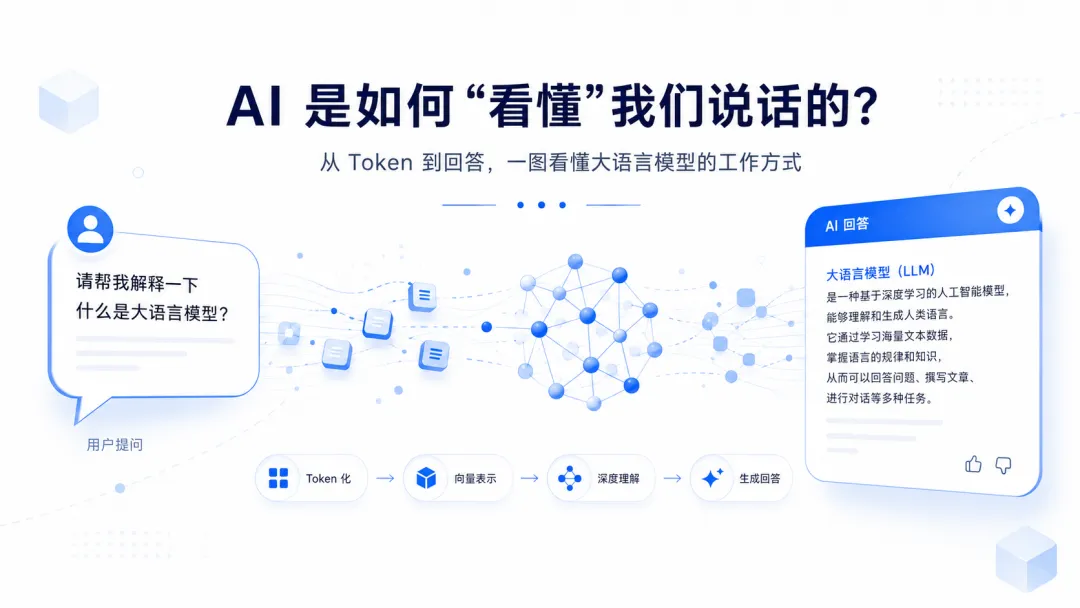
我刚开始学AI的时候,最好奇一个问题就是:
AI是如何看懂我们说话的?
因为我觉得很神奇。
无论我们问什么,它似乎都能看懂,并且给出非常自然、合理的回答。
但后来我慢慢学得深入了才明白:
现在大语言模型(LLM)并不是真的像人一样“看懂”了我们问题。
他本质上,是一台极其复杂的“概率运算机器”。
之所以它显得像是在思考,是因为它的运算能力太强了,强到让我们产生了一种错觉:
它好像真的在思考,真的很懂我。
但如果把 AI 的工作方式拆开来看,他的核心逻辑其实可以用一句话概括:
根据前面的内容,预测下一个最可能出现的 Token。
01|大模型的本质:预测下一个 Token
大语言你模型的数学本质,可以简单理解成下面这个公式:
P(wt∣w1,w2,…,wt−1)
翻译成人话就是:
给定前面已经出现的所有内容,计算下一个 Token 出现的概率。
所以说,大模型不是一次性输出整个回答。
踏实在不停地做一件事:
猜下一个 Token 是什么。
但问题来了:
既然模型只会计算概率,它到底是怎么处理我们输入的文字的?
首先要知道:
模型是看不懂中文,也不懂英文。
模型真正理解的,只有“数字”。
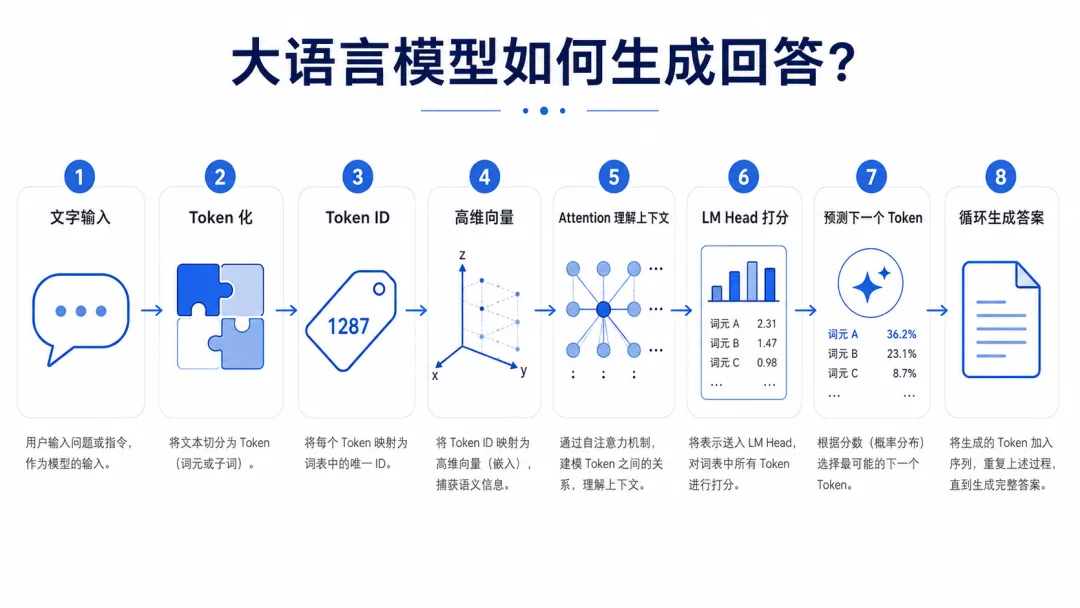
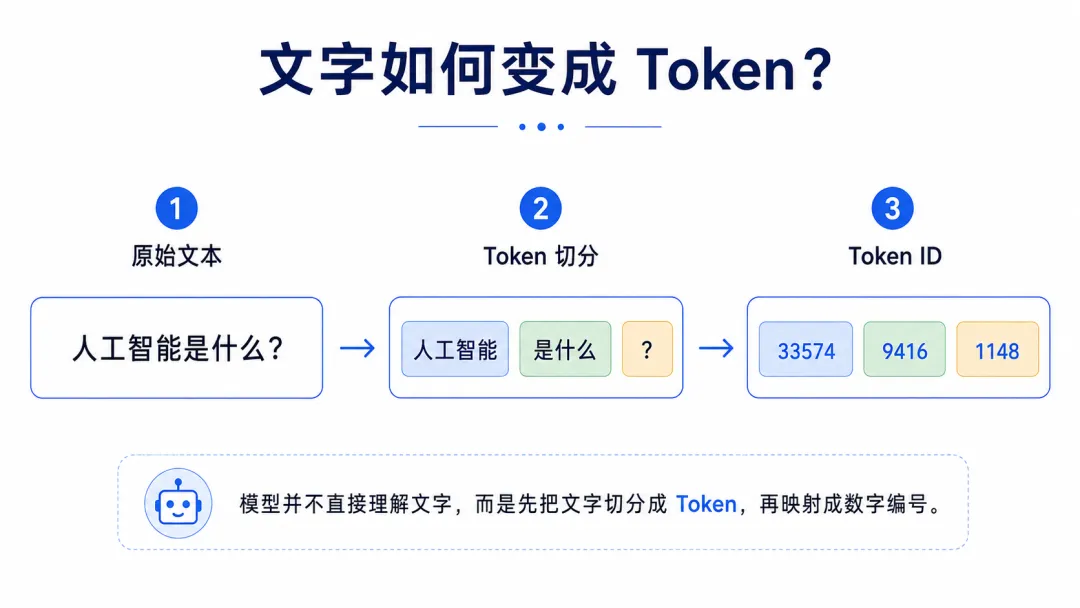
所以,当我们输入一段话之后,这段话会被先被切分成一个个 Token。
Token 可以理解成模型处理语言是的基本单位。
它可能是一个字,也可能是一个词,也可能是一个子词、空格或者标点符号。
不过要注意,
不同的模型的 Token 切分方式可能不一样,
这和他们使用的词表、训练语料、分词算法等等有关系。
例如,“人工智能是什么?”这句话,
在 DeepSeek R1 的词表中,
会被划分成 3 个 Token,
“人工智能/是什么/?”。
而在 GPT-4o 中,
会被划分成 4 个 Token,
“人工/智能/是什么 ?”
每个 Token 都会对应一个固定的 Token ID,
你可以把 Token ID 理解为这个词在模型词表里的“身份证号”。
例如,“人工智能是什么?”在 DeepSeek-R1 中对应的 Token ID:
人工智能:33574
是什么:9416
?:1148
也就是说,模型看到的不是:
人工智能是什么?
而更接近于:
33574,9416,1148
03|Token ID 本身没有意义,向量才有语义
不过,光有 Token ID 还不够,
因为 Token ID 本质只是一个编号。
就像一个人的身份证号,只能告诉你这个人有一个唯一的编号,但它不会告诉你:
这个人是什么性格?他喜欢什么?他和谁关系更近?他属于什么群体?
Token ID 也是一样的,
这一串数字本身并不包含真正的语义。
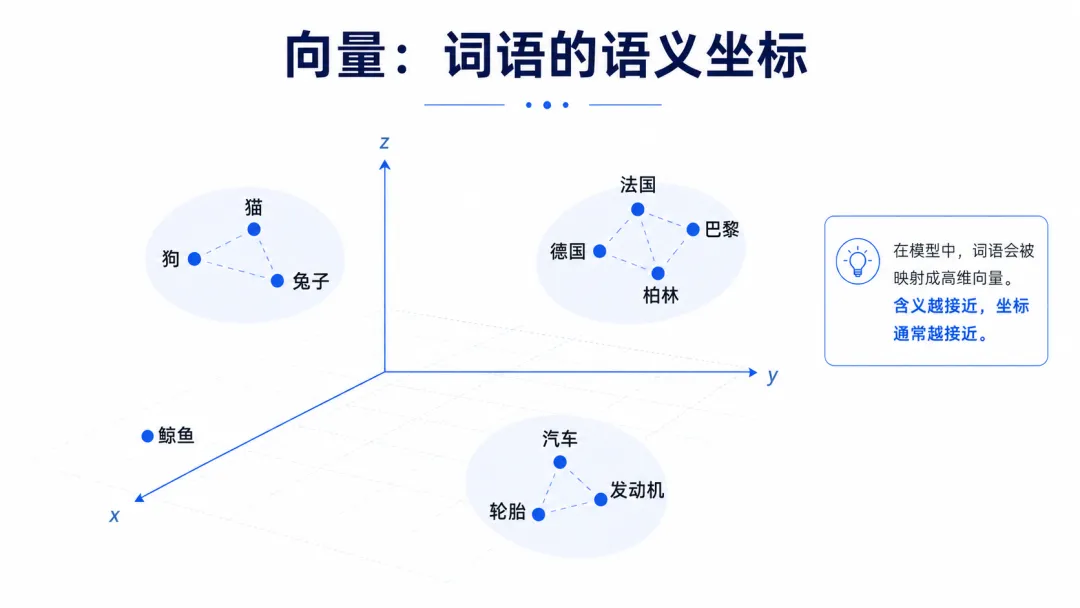
所以,模型还需要把 Token ID 映射成一个高维向量。
你可以把这个高维向量理解成:
这个词在“语义地图”中的一个坐标。
比如,在高维空间里,
"猫"和"狗"的坐标靠得很近,因为他们的含义很相近,都是动物;
"法国"和"巴黎"之间有特定的方向关系,因为法国与巴黎之间的联系很密切;
然而“汽车”与“鲸鱼”的坐标就会相离很远,因为他俩的含义联系的并不密切,几乎不太可能同时出现。
所以,大模型并不是直接理解文字,
它先把文字变成 Token,再把 Token ID 变成高维向量,然后在这个巨大的语义空间里进行计算。
不过要注意:
这个高维向量的映射关系不是人为固定的,
而是模型在海量数据中自学出来的。
至今人类也无法准确解释,
每一个Token 的高维向量具体代表什么含义。
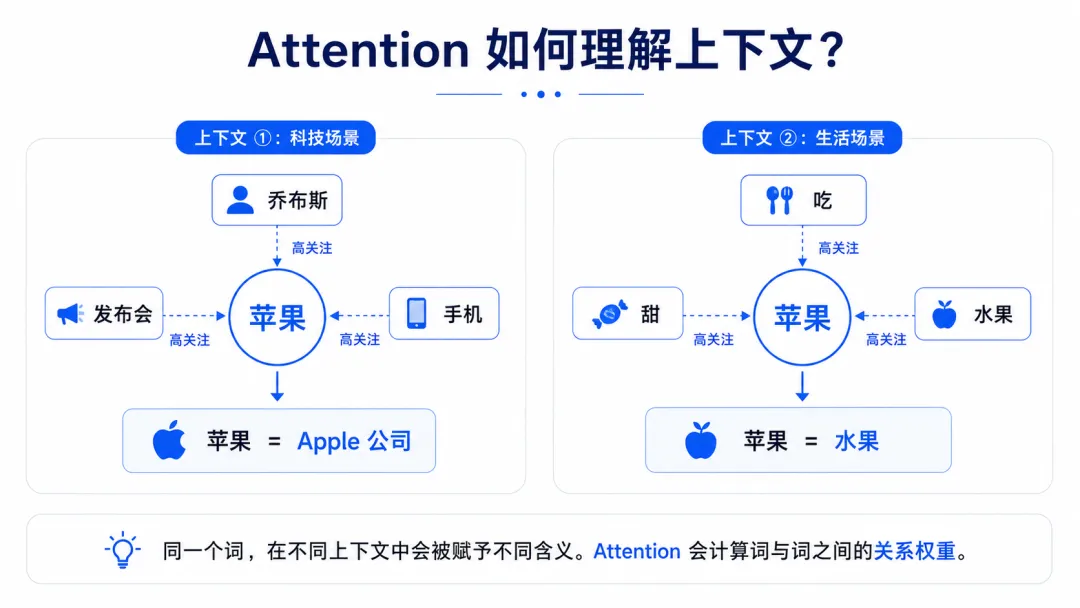
04|同一个词,在不同的上下文里意思不同
但仅仅把 Token 变成向量还不够。
因为同一个词,在不同的语境中,可能有完全不同的意思。
比如“苹果”。
当它刚进入模型时,它的初始向量是固定的。
模型并不知道你说的“苹果”指的是手机还是水果。
这时候,Transformer 架构中最重要的注意力机制(Attention)就开始发挥作用了。
模型会计算“苹果”这个词语上下文所有词的关系权重:
如果上下文中有“乔布斯”、“发布会”、“手机”,
模型就会把“苹果”的含义向“科技公司”拉近;
如果上下文里有“吃”、“甜”、“水果”,
模型就会把它向“水果”拉近。
这就是为什么模型能够根据上下文,判断同一个词在不同句子中的不同含义。
所以,大模型所谓的“理解”,并不是像人一样真的懂了这个词。
而是它通过大量计算,重新调整了这个词在当前上下文中的语义表示。
05|模型不是直接写答案,而是在给词库打分
当模型通过 Transformer 计算完上下文之后,它就得到了一个新的语义表示。
这个语义表示里,包含了当前上下文的信息。
接下来,模型要做的事情就是:
预测下一个 Token。
这时候,它会把当前的上下文向量送到一个输出层。
这个输出层通常叫:
LM Head。
你可以把 LM Head 理解成一张巨大的“打分表”。
它会给词表里的每一个 Token 都打一个分。
分数越高,代表这个 Token 越适合作为下一个输出。
比如在这句话后面:
中国的首都是
模型会给词表里的每一个 Token 打分。
可能结果大概是:
北京:分数很高上海:有一点分数广州:分数较低苹果:分数很低鲸鱼:几乎不可能
然后模型会把这些分数转换成概率分布。
也就是说,它会计算:
北京作为下一个 Token 的概率是多少?上海作为下一个 Token 的概率是多少?苹果作为下一个 Token 的概率是多少?
最后,模型会根据这个概率分布,选择一个 Token 输出。
这里要注意:
模型并不一定永远选概率最高的词。
因为模型会使用不同的采样策略。
有时候它会更保守,选择最可能的词。有时候它会更发散,选择一些概率没那么高、但更有创造性的词。
这也是为什么同一个问题,你问模型两次,它可能会给出不完全一样的回答。
06|答案是一个 Token 一个 Token 生成的
模型输出第一个 Token 之后,
他会把刚刚生成的 Token,重新加到原来的上下文后面,
然后继续预测下一个 Token。
比如用户输入:
中国的首都是
模型预测出:
北京
这时候,新的上下文就变成了:
中国的首都是北京
然后模型继续预测下一个 Token。
它可能预测出:
。
于是上下文变成:
中国的首都是北京。
接着,如果模型还需要继续回答,它就会继续预测后面的 Token。
比如:
北京是中国的政治、文化中心之一。
这句话也是一个 Token 一个 Token 生成出来的。
所以,模型的回答不是一次性写出来的。
它更像是一个不断循环的过程:
读取上下文计算语义给 Token 打分选择下一个 Token追加到上下文继续预测
如此循环,最后才生成了我们看到的一整段回答。
07|所以,AI 真的“看懂”我们的话了吗?
讲到这里,我们就可以回到最开始的问题:
AI 到底有没有真的看懂我们说的话?
如果从人类理解的角度来说,它并没有真的“看懂”。
它不知道“疼”是什么感觉;
它不知道“爱”是什么滋味;
它也没有真正生过在这个世界里。
它并不像人类一样,通过身体、情绪、经验和现实生活去理解语言。
但是如果从数学计算的角度来说,它确实学到了一个非常强的的语言规律。
他知道:
哪些词经常在一起出现;
哪些表达更符合上下文;
哪些回答在人类语境中更合理;
哪些概念之间存在更强的关联。
所以,大模型的“理解”,并不是人类意义上的理解。
它更像是:
通过海量文本训练出来的统计规律和语义映射。
也正是这种能力,让它可以回答问题、总结文章、写代码、翻译文本,甚至进行复杂推理。
08|结语:大模型没有灵魂,只有概率
看完这个过程,你应该就能明白一句话:
大模型没有灵魂,只有概率。
它所做的事情,本质上是在计算:
在这个特定的上下文里,下一个 Token 是什么?
但不得不承认的是:
这种基于概率的“模仿游戏”,在海量数据和巨大算力的加持下,已经变得极其强大。
强大到可以写文章;
强大到可以写代码;
强大到可以帮助我们学习知识;
强大到正在改变很多行业的工作方式。
所以,理解大模型的第一步,不是把它看成一个真的有意识的大脑。
而是把它看成一台极其强大的:
语言预测机器。
它未必像人一样思考。
但它已经足够改变这个世界。
