 夜雨聆风
夜雨聆风PyMuPDF 页面标注:PDF 布局分析指南
一、什么是 PyMuPDF 页面标注
PyMuPDF 可以分析每个文本块(block)的字体大小、字体名称、是否加粗等属性,自动推断段落类别,并直接用 draw_rect() 在 PDF 页面上绘制半透明矩形标注,最终输出一份带标注的 PDF 文件。
本文实现的效果:
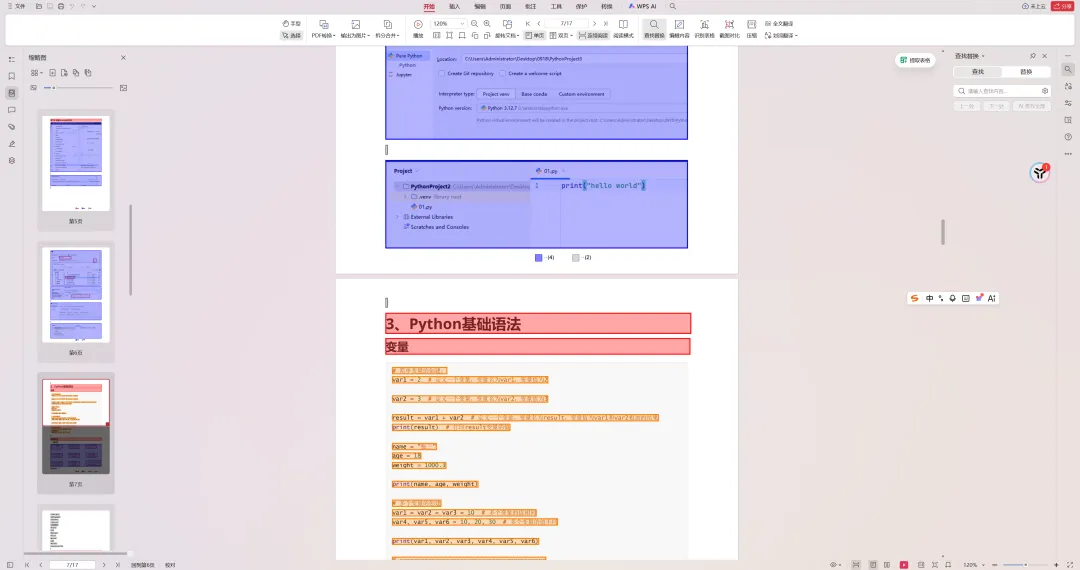
• 红色框 → 标题(Title) • 蓝色框 → 图片(Image) • 绿色框 → 表格(Table) • 橙色框 → 代码块(Code) • 灰色框 → 正文(Body)
二、与 Marker 的对比
三、核心原理
3.1 PyMuPDF 的 Block 结构
PyMuPDF 通过 page.get_text("dict") 获取页面结构,每个 block 包含:
block = { "type": 0, # 0=文本, 1=图片 "bbox": (x0,y0,x1,y1), # 边界框 "lines": [ # 文本行列表 { "spans": [ # 文本片段列表 { "text": "标题文字", "size": 21.9, # 字号 "font": "MicrosoftYaHei-Bold", # 字体名 "color": 0x000000, # 颜色 "flags": 4, # 样式标志 } ] } ]}3.2 分类规则
通过分析 block 的文本属性,推断段落类别:
block["type"] == 1 | Image |
Console/Mono/Courier/Lucida | Code |
| 或 │ 分隔符 | Table |
| Title | |
| Title | |
| Title | |
| Body |
3.3 颜色映射
使用 PyMuPDF draw_rect() 的 RGB 元组格式(值 0~1),配合 fill_opacity 控制透明度:
COLOR_MAP = {"Title": ((1.0, 0.0, 0.0), 0.35), # 红色,35% 透明度"Image": ((0.0, 0.0, 1.0), 0.30), # 蓝色,30% 透明度"Table": ((0.0, 0.7, 0.0), 0.30), # 绿色,30% 透明度"Code": ((1.0, 0.5, 0.0), 0.25), # 橙色,25% 透明度"Body": ((0.5, 0.5, 0.5), 0.12), # 灰色,12% 透明度}四、完整脚本
"""PyMuPDF 读取 PDF,在页面上直接绘制标注矩形框,输出带标注的 PDF 文件。用法: python parse_pdf_annotate.py [pdf文件路径] [--pages 0,1,2] [--preview]"""import sysfrom pathlib import Pathimport fitz # PyMuPDFdef classify_block(block: dict) -> str:"""根据文本属性分类段落类型。"""if block["type"] == 1:return "Image" lines = block.get("lines", [])if not lines:return"Body" all_text = "" max_size = 0 is_bold = False is_mono = Falsefor line in lines:for span in line.get("spans", []): all_text += span["text"] max_size = max(max_size, span["size"]) font_lower = span["font"].lower()if "bold" in font_lower: is_bold = Trueif any(m in font_lower for m in ["console", "mono", "courier", "code", "lucida"]): is_mono = True text = all_text.strip()if not text:return "Body"# 代码块:等宽字体if is_mono:return "Code"# 表格检测:文本中含管道分隔符 lines_text = []for line in lines: line_text = "".join(s["text"] for s in line["spans"]).strip()if line_text: lines_text.append(line_text)if len(lines_text) >= 2: pipe_count = sum(1 for lt in lines_text if "|" in lt or "│" in lt)if pipe_count >= 1:return "Table" sep_count = sum(1 for lt in lines_text if lt.startswith("---") or lt.startswith("==="))if sep_count >= 1:return "Table"# 标题:字号大且加粗if max_size >= 17and is_bold:return"Title"if max_size >= 14and is_bold:return"Title"if max_size >= 20:return"Title"return"Body"COLOR_MAP = {"Title": ((1.0, 0.0, 0.0), 0.35), # 红色"Image": ((0.0, 0.0, 1.0), 0.30), # 蓝色"Table": ((0.0, 0.7, 0.0), 0.30), # 绿色"Code": ((1.0, 0.5, 0.0), 0.25), # 橙色"Body": ((0.5, 0.5, 0.5), 0.12), # 灰色}def main():if sys.platform == "win32": sys.stdout.reconfigure(encoding="utf-8", errors="replace") file_path = sys.argv[1] if len(sys.argv) > 1 else "day01.pdf"# ... 参数解析省略,参见实际脚本 ... doc = fitz.open(str(pdf_path))# ===== 一、打印 metadata =====# ...# ===== 二、逐页分析并标注 =====for page_num in range(doc.page_count): page = doc[page_num] blocks = page.get_text("dict")["blocks"]# 对每个 block 分类for b in blocks: category = classify_block(b) bbox = b["bbox"] rect = fitz.Rect(bbox) rgb, alpha = COLOR_MAP.get(category)# 核心:直接在 PDF 页面上绘制半透明矩形 page.draw_rect( rect, color=rgb, fill=rgb, fill_opacity=alpha, width=1.5, )# 页面底部绘制图例# ...# ===== 三、保存为 PDF ===== doc.save("pdf_output/day01_annotated.pdf", garbage=4, deflate=True) doc.close()if __name__ == "__main__": main()关键 API:
page.draw_rect( fitz.Rect(x0, y0, x1, y1), # 矩形区域(原始坐标,无需缩放) color=(1.0, 0.0, 0.0), # 边框颜色 RGB 0~1 fill=(1.0, 0.0, 0.0), # 填充颜色 RGB 0~1 fill_opacity=0.35, # 透明度 0~1 width=1.5, # 边框线宽)与 matplotlib 方案的区别:
| PDF 文件 | ||
| 原始坐标直接使用 | ||
| 原文本保持可复制可搜索 | ||
| 单 PDF 约 740KB | ||
| 即时绘制 |
执行命令:
# 完整标注,输出 pdf_output/day01_annotated.pdfpython parse_pdf_annotate.py day01.pdf# 仅标注前 3 页python parse_pdf_annotate.py day01.pdf --pages 0,1,2# 额外弹出 matplotlib 预览窗口python parse_pdf_annotate.py day01.pdf --preview五、day01.pdf 实测结果
解析前:
以 17 页 Python 学习笔记 PDF 为例:
解析文件: day01.pdf文件大小: 629.4 KB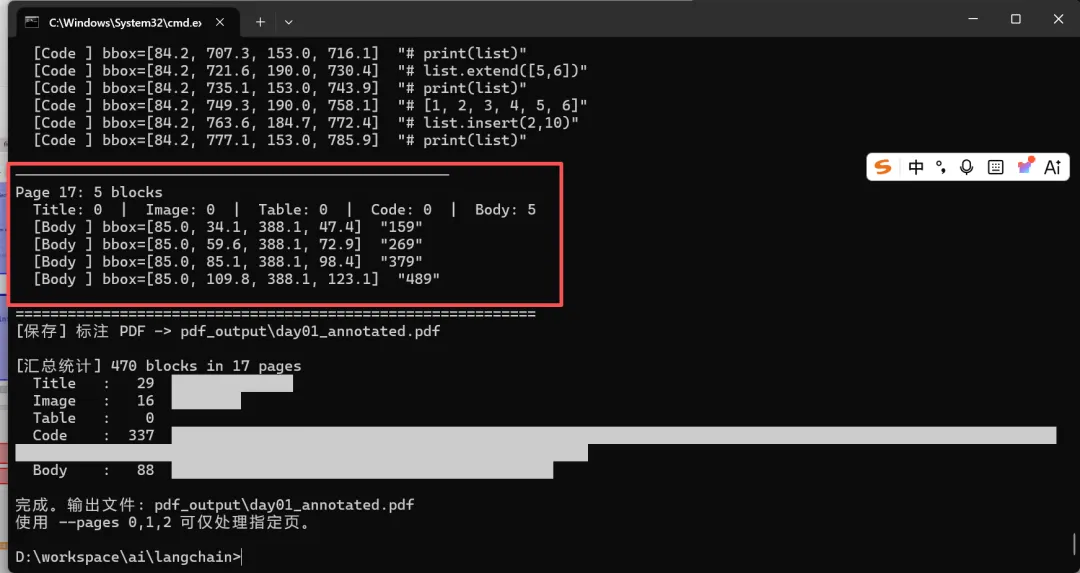
输出文件:pdf_output/day01_annotated.pdf(738 KB)
分析:
示例输出(Page 1):
Page 1: 27 blocks Title:6 Image:1 Code:6 Body:14 [Title] bbox=[74.5, 36.8, 526.5, 66.7] "任务(截止11.16:23:59)" [Body ] bbox=[97.0, 76.9, 331.0, 89.8] "把听书项目核心模块流程背下来..." [Body ] bbox=[97.0, 97.2, 282.2, 110.1] "把核心模块技术栈和细节问题..." [Title] bbox=[74.5, 142.6, 526.5, 172.4] "1、Python概述" [Title] bbox=[74.5, 180.0, 525.2, 203.2] "概述" [Body ] bbox=[97.0, 214.1, 226.7, 227.4] "python是面向对象的编程语言" ... [Title] bbox=[74.5, 370.9, 524.6, 390.8] "缩进: 表示范围" [Code ] bbox=[84.2, 437.3, 137.1, 446.1] "def add():" [Code ] bbox=[84.2, 450.8, 137.2, 459.6] "x = 10" [Code ] bbox=[84.2, 465.1, 142.5, 473.9] "if x>0:" ... [Image] bbox=[76.8, 691.8, 519.2, 767.5]可视化效果:
• 红色框标注了 "任务(截止11.16:23:59)"、"1、Python概述" 等标题 • 橙色框标注了所有代码行( def add():、x = 10等)• 蓝色框标注了嵌入的截图 • 灰色框标注了正文说明文字
六、分类规则调优指南
不同 PDF 的排版风格不同,分类规则需要根据实际情况调整。以下是一个调试方法:
# 先打印所有 block 的字体信息,找到规律import fitzdoc = fitz.open("your_file.pdf")page = doc[0]blocks = page.get_text("dict")["blocks"]for i, b in enumerate(blocks):if b["type"] == 1:print(f"[{i}] IMAGE bbox={b['bbox']}")continuefor line in b.get("lines", []):for span in line.get("spans", []): text = span["text"].strip()if text:print(f"[{i}] size={span['size']:.1f} "f"font=\"{span['font']}\" "f"text=\"{text[:60]}\"")常见字体名规律:
Bold | |
Console/Mono/Lucida | |
YaHei/Songti/Heiti | |
扩展:检测更多类别
defclassify_block_advanced(block):"""支持更多类别:表格(空间对齐)、公式、页眉页脚。"""# ... 前面代码同上 ...# 表格检测:多行文本在同一 x 区域内对齐if len(lines) >= 3: x_starts = [min(s["bbox"][0] for s in line["spans"])for line in lines if line["spans"]]if len(set(round(x, -1) for x in x_starts)) >= 3:return "Table"# 多列对齐 → 可能是表格# 页眉页脚检测:位于页面顶部/底部 y_pos = block["bbox"][1]if y_pos < 50 or y_pos > page_height - 50:return "Header/Footer"return"Body"七、常见踩坑
坑1:中文字符显示乱码
现象:打印时出现 UnicodeEncodeError 或 \xa0 乱码。
解决:脚本开头添加编码重配置:
if sys.platform == "win32": sys.stdout.reconfigure(encoding="utf-8", errors="replace")坑2:字体名大小写不一致
现象:"bold" in span["font"] 检测不到加粗。
原因:字体名可能是 MicrosoftYaHei-Bold(首字母大写)。
解决:统一转小写再搜索:span["font"].lower()
坑3:表格检测依赖于文本格式
现象:Table 检测数量为 0。
原因:PDF 中的表格可能以独立文本块存储,不含 | 分隔符。Typora 导出的 PDF 将表格每个单元格渲染为独立 block,没有明确的表格标记。
解决:使用空间对齐分析(多列 x 坐标聚类)来推测表格结构。
坑4:图片块无文本内容
现象:Image 类型的 block 没有 lines 字段。
原因:PyMuPDF 将图片标记为 type=1,只有 bbox 信息,无文本。
解决:在分类函数中优先判断 block["type"] == 1。
八、总结
PyMuPDF draw_rect() 的页面标注方案是一个轻量级的 PDF 布局分析工具:
1. 零额外依赖:不需要 matplotlib、不需要深度学习模型(区别于 Marker) 2. 极快速度:< 0.1 秒/页,适合批量处理 3. 原生 PDF 输出:标注直接绘制在 PDF 页面上,文本保持可选中可搜索 4. 文件紧凑:17 页标注 PDF 仅 738 KB(原文件 629 KB) 5. 可定制:分类规则完全可控,根据不同 PDF 风格灵活调整 6. 每页自带图例:底部自动生成颜色-类别对应图例,无需对照文档查看
局限性是标题推断依赖字体规则(不如 Marker 的视觉模型准确),以及表格检测对特定 PDF 格式效果有限。如需完整结构化转换(保留标题层次+表格+图片到 Markdown),推荐使用 Marker。
