 夜雨聆风
夜雨聆风导语: 在上篇文章中,我们探讨了 Harness Engineering的定义,并借由 OpenAI 和 Anthropic 两大 AI 巨头的实战案例证明了Harness 绝非噱头,而是真正让 AI 从“玩具”走向“生产力工具”的必经之路。
抛开概念,真正的硬核问题是:如何在生产环境中 Deploy 一套行之有效的 Harness 系统?经过对头部 AI 团队案例拆解分析,我总结四大核心方法论。
0x01. 📂 代码库即真相源
在搭建harness系统时需要明确一点:Agent所需要的所有知识都来源于代码库本身而非外部。通过在项目根目录中放置结构化的配置文件(如CLAUDE.md、AGENTS.md)让Agent每次启动自动读取,获取项目的技术栈、常用命令、编码规范和行为禁区等信息。 搭建Agent时不能指望 AI 能凭空猜出项目规范,Agent 所需要的所有知识,都应来源于代码库本身,而非外部零散的文档或口头约定。
[WARNING] 这相当于给 AI 写了一份项目说明书,但需注意:它是一份精炼的行军指南,而不是百科全书。
以 AGENTS.md 为例,通常保持在 100 行左右即可。它不是面面俱到的百科,而是地图和目录,指引 Agent 前往 docs/ 目录中寻找更深层次的真相源。一个典型的结构化知识库目录如下:
AGENTS.md
ARCHITECTURE.md
docs/
├── design-docs/
│ ├── index.md
│ ├── core-beliefs.md
│ └── ...
├── exec-plans/
│ ├── active/
│ ├── completed/
│ └── tech-debt-tracker.md
├── generated/
│ └── db-schema.md
├── product-specs/
│ ├── index.md
│ ├── new-user-onboarding.md
│ └── ...
├── references/
│ ├── design-system-reference-llms.txt
│ ├── nixpacks-llms.txt
│ ├── uv-llms.txt
│ └── ...
├── DESIGN.md
├── FRONTEND.md
├── PLANS.md
├── PRODUCT_SENSE.md
├── QUALITY_SCORE.md
├── RELIABILITY.md
└── SECURITY.md
0x02. 🛡️ 机械化架构约束
不要考验 Agent 的“自觉性”,用自动化工具把约束刻进执行流程。
写在 CLAUDE.md 里的提示词(Prompt)本质上只是建议但在Agent运行过程中可能因为AI自幻觉或者“偷懒”被忽略掉,而少了一些强制约束的规矩,在Agent长时间、多轮次运行中任何未按照流程正确触发的动作都会对最终的结果产生翻天覆地的改变;而通过自动化工具把约束写死到代码中的 Hooks(钩子)就被称为法律这是一种硬约束)。建议可以被AI忽略,但法律不行。 例如在codex给出的实战案例项目中设计了6层分级约束体系,用自动化工具在每一层强制执行架构规则。一旦发现了跨层级的调用会直接对代码报错并反馈修改。
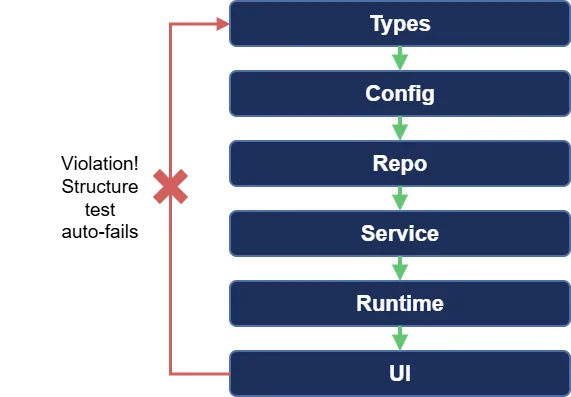
熟悉 Git的小伙伴一定知道在 git commit 时会自动触发 Git Hooks。AI Agent 的 Hooks 机制同理:在 Agent 执行操作前后,自动触发检查程序。
这种“机械化约束”是如何拦截危险操作的?在底层框架中,这通常通过中间件(Middleware)或拦截器模式实现。我们以 AI 执行一条 Bash 命令为例:
意图生成: AI 决定调用工具,生成参数 {"command": "rm -rf /"}。触发 Pre-Hook(前置钩子): 命令尚未发往终端。框架接管控制权,正则匹配发现危险命令 rm -rf。无情拦截: 系统拒绝执行,并将错误信息作为结果塞回给 AI。 触发 Post-Hook(后置钩子): 如果是一条合法命令(如 ls -l)执行完毕后,后置脚本会检查输出。比如日志超过 1000 行,Hook 会自动进行截断或摘要再喂给 AI,防止上下文窗口撑爆(Token 溢出)。
**[INFO] ** 这就如同现实中的交通规则,提示词只是“红灯停”的标牌,但这种约束不能完全杜绝闯红灯事件,而 Hooks 是红灯时自动升起的物理防撞柱,想闯也闯不过去。
0x03. 🔄 全覆盖的反馈循环
没有反馈的 Agent 就像在黑暗中射箭,可能偶尔命中,但大多时候结果是偏离靶心的。
Anthropic 在其长时运行 Agent 的实践中提出了一个精准的类比:Agent 的每个新会话“开始时都没有之前的记忆”——就像轮班的工程师没有交接记录。上午做了一半,下午换人,如果没有反馈和交接,下午的 AI 根本不知道该往哪走。
为了让 Agent 在每一步都能获知“做得对不对”,需要构建四层分级反馈体系。它们不是单选题,而是互相补充的安全网:
| 即时反馈 | ||||
| 构建反馈 | ||||
| 运行时反馈 | ||||
| 评审反馈 |
🛠️ 实战演练:让 Agent 写一个“用户注册 API”
写代码时: Agent 企图明文存储密码。即时反馈 (Post-Hook) 立刻警告:“存在安全风险,需加密”。 准备提交时: Agent 执行 Git 提交。即时反馈 (Pre-Hook) 发现缺少类型提示,拦截提交。 创建 PR 时: 代码推送到仓库。构建反馈 (CI/CD) 跑单元测试发现:重复注册未返回正确的 409 状态码。 部署上线后: 运行时反馈显示该 API 延迟达到 3 秒(发现数据库没建索引)。 功能完成后: 评审反馈 (Reviewer Agent) 指出:缺少邮箱验证步骤,容易被恶意批量注册。
此外,为了解决“重启后不知道做到哪”的问题,必须为 Agent 设定严格的会话启动协议:pwd 确认位置 -> 读 git log 确认进度 -> 跑端到端测试确认基线正常 -> 开始写代码。
0x04. 🧹 持续的熵管理
传统软件开发害怕的是 Bug(程序崩溃、漏洞等),但 AI 生成代码带来了一种全新的质量危机:渐进式的系统退化(熵增)。如果不加干预,Agent 产出的代码库会陷入“生成得越快、烂得越快”的恶性循环。这不是一种爆炸式的突发现象,而是会随着实现的迁移逐渐腐化,但这种熵增对代码库的影响会随着事件呈指数级的增长,最终可能会导致代码完全不能用,需要投入大量人工成本进行重构。
| 文档漂移 | ||
| 架构侵蚀 | ||
| 风格不一致 | ||
| 代码重复 |
面对代码熵增,头部团队给出的解法是:
将“品味”固化为 Linter 规则: 不靠祈祷 Agent 遵守文档,而是用自动化工具扫描。例如:如果要求 API 用 snake_case,发现userName时直接报错,并在错误信息里内置修复指南,让 Agent 顺藤摸瓜自己改。部署后台“保洁 Agent”定期扫描: 每天凌晨自动运行,检查文档漂移、架构越权(比如 Controller 违规直连数据库),并生成“代码健康度日报”。 持续重构,拒绝技术债: 发现重复代码立刻提取公共函数。不要对 AI 说“以后再说”,因为在 AI 的字典里,“以后”永远不会来。
[EOF]总结
梳理完 Harness Engineering 的四大方法论,我最大的感触是:我们正在经历从“Prompt Engineering”到“System Engineering”的范式转变。
过去一年,大家都在沉迷于怎么写出“花言巧语”的 Prompt 让大模型更聪明。但实战证明,面对复杂的业务和安全要求,单纯依靠 LLM 的“高智商”是极其脆弱的。
大模型本质上是一个概率生成引擎,它有着惊人的马力,但没有方向盘和刹车。Harness Engineering 其实就是为 AI 打造的底盘和轨道——用代码库作为导航,用 Hooks 充当刹车,用四层反馈当雷达,用定期清理维持保养。
[Process Terminated]AI 不会取代懂得构建系统的工程师,因为建设和维护这套 Harness 护栏,本身就是未来软件开发中最具技术含量、也是最具安全价值的核心工作。
