 夜雨聆风
夜雨聆风在正式开启本文之前,我想说明的是同 SpecKit 一样,OpenSpec 也只是规范驱动开发的一个具体实例,我们需要将重点放在理解 OpenSpec 针对规范驱动开发进行轻量化的“渐进式增强规范”这一核心思想上,而不仅仅只是关注于其使用。
AI Agent 工具层出不穷,对于我们使用者来说应当更多地关注这些优质工具的核心思想,在使用这些工具的过程中,逐步形成自己的 AI 应用方法论。通俗来讲就是“铁打的 AI 应用思想方法论,流水的 AI 工具”。
OpenSpec的核心要点:
• 规范驱动开发的轻量化 -> 渐进式增强规范(Progressive Rigor) • 增量需求开发(Delta Specs)-> 已有 specs 与增量需求 specs 隔离管理
本文概览
1. spec kit 与 open spec 对比 2. OpenSpec轻量化的关键——规范的“渐进式增强”2.1. Lite spec(轻量级规范)—— 默认选项2.2. Full spec(完整规范)—— 用于高风险变更2.3. Lite spec 与 Full spec 对比 3. OpenSpec 对规范 specs 的管理 4. OpenSpec工作流4.1. 默认工作流4.2. 扩展版本的工作流4.3. sync 与 archive 5. 针对中间产出内容(artifact)的修改5.1. 中间产出内容(artifact)5.2. 修改原则5.3. 一些问题Q1:依赖链 proposal → specs → design → tasks → apply(代码)改上游时要不要改下游?Q2:各命令对修改已有 artifact 的行为是怎样的? 6. Delivery与Workflows 7. 相关参考
spec kit 与 open spec 对比
在这里首先需要强调的是,一般我们将 spec kit 与 open spec 搭配使用,二者不是互斥的:
• spec kit:greenfield,0->1,从零开发(scratch) • open spec:brownfield,1->n,增量开发(delta)
spec kit 感觉有些“一板一眼,僵化”,open spec 相对“宽松,灵活”些。
open spec 用“快速迭代+人工审查”替代“强制问答”:
• spec kit 的做法:假设规范必须尽可能完美才能进入技术设计,因此需要主动、系统性地挖掘模糊点并强制澄清。 • open spec 的做法:承认规范在编写时不可能完全清晰。它的 propose 命令直接生成一个包含规范差异(deltas)的初步提案。如果某个变更需求存在不清晰的地方,开发者和 AI 会直接修改提案文件(比如编辑 specs/ 下的 delta 文件),或者通过一次简单的自然语言对话进行调整。整个“澄清对齐”的过程是非强制、嵌入式的,你可以随时反复修改提案,直到达成共识。
此外,虽然这些指令不是 spec kit 必须执行的,但个人感觉 spec kit 在使用过程中,比较繁琐(耗费精力和时间相对比较多,需要反复确认)的流程节点主要在:
• 需求澄清 clarify • 需求质量检查 checklist • 在最终执行实现前的交叉规范一致性校验 analyze
本质:open spec 流程节点间的转移要求降低(相对 spec kit 没那么严格),并简化了澄清确认核对的步骤。
OpenSpec is built around four principles:
fluid not rigid — no phase gates, work on what makes senseiterative not waterfall — learn as you build, refine as you goeasy not complex — lightweight setup, minimal ceremonybrownfield-first — works with existing codebases, not just greenfield
open spec 与 spec kit 流程对比:
| 对比维度 | OpenSpec:变更驱动的轻量规范 | Spec Kit:规范即流程的完整框架 |
| 核心理念 | 把规范当作变更的“管理工具”。它专注在既有项目上做增量更新,强调“活文档”。 | 把规范当作生成代码的蓝图。它强调规范的“可执行性”,更像一个标准的工业化生产线。 |
| 工作流 | 精简灵活:核心三步骤 | 既定与完整:固定的七阶段流程 |
| 规范格式 | 简洁的差异: | 复杂的模板化: |
| 依赖与设置 | 几乎没有:无需API密钥,无需复杂配置。 | 较高:工具包本身较轻量,但其流程决定了更多的前置环节和人工决策点。 |
| 适用场景 | 优于演进中的“棕色地带”项目(即1→n的已有项目),尤其适合增量迭代。 | 擅长0→1的新项目,能帮助团队从零开始建立一套完整的规范体系。 |
OpenSpec轻量化的关键——规范的“渐进式增强”
渐进式增强(Progressive Rigor):可以从一个极简的规范开始,随着风险信号的出现,逐步增加规范的正式程度,而不是一开始就预设一个全量模板。
与 Skill 的渐进式披露(Progressive disclosure)的本质类似,这里 OpenSpec 的渐进式增强(Progressive Rigor)对于规范的要求也是“按需添加,懒加载”:
• 避免官僚主义:OpenSpec 认为,并非所有变更都需要同等程度的正式规范。如果为每个小修改都撰写长篇大论的正式文档,会拖慢开发节奏。 • 选择最轻的可用层级:要求开发者/用户主动判断:“为了能验证这个变更是否正确,我至少需要写多少规范?” 只写必要的,不多写一个字。 • “可验证”(verifiable) 是底线:无论选择多轻量的规范,最终都必须能够清晰判断一个实现是否满足需求(例如通过验收检查项)。
Keep It Lightweight: Progressive Rigor
OpenSpec aims to avoid bureaucracy. Use the lightest level that still makes the change verifiable.
为了实现针对规范的“渐进式增强”,OpenSpec 定义了两种预设的规范层级:Lite(轻量级,默认) 和 Full(完整级,用于高风险)。
Lite spec(轻量级规范)—— 默认选项
这是绝大多数日常开发应当使用的级别。它包含三个核心要素:
• 简短、以行为优先的需求(Short behavior-first requirements)用一两句话描述“系统应该做什么”,而不是“怎么实现”。例如:“当用户点击‘退出登录’按钮时,系统应清除本地会话并重定向到登录页。” • 明确的范围与非目标(Clear scope and non-goals)用极简的方式说明“这个变更包含什么、不包含什么”,防止范围蔓延。例如:“本次变更不涉及修改密码流程,也不改变用户头像存储逻辑。” • 几个具体的验收检查项(A few concrete acceptance checks)列出可执行的、客观的验证条件,通常以列表形式呈现,每个条目都是可以通过自动化或人工测试验证的。例如: • [ ]点击退出登录后,本地 localStorage 中的 token 被清除。 • [ ]重定向到/login页面。 • [ ]未调用任何后端接口(因为使用了本地清除逻辑)。
适用场景:绝大多数日常功能开发、bug修复、UI微调、性能优化等,只要变更后果可控、不涉及跨团队协调,都使用 Lite 模式。
Full spec(完整规范)—— 用于高风险变更
当变更的风险显著增加时,OpenSpec 鼓励升级到 Full 级别,此时规范需要更详尽、更正式。典型的高风险信号包括:
• 跨团队或跨仓库变更(Cross-team or cross-repo changes)需要多个团队协商接口、数据格式、发布顺序等,规范必须足够清晰以避免误解。 • API/契约变更、数据库迁移、安全/隐私相关问题这些变更一旦出错,代价极高(破坏兼容性、数据丢失、安全漏洞),因此需要更严谨的规范,包括错误处理、回滚方案、权限模型等。 • 歧义可能导致昂贵返工的变更(Changes where ambiguity is likely to cause expensive rework)如果需求不清晰会导致后期大量推翻重做,那么前期花时间写完整规范是非常值得的投资。
Lite spec 与 Full spec 对比
Full spec 相比 Lite 会通常增加包括更详细的背景动机、技术约束、数据流图、时序图、详细的错误场景、非功能性需求(性能、安全、可观测性)等。OpenSpec 并不强制规定 Full spec 的固定模板,而是交给团队根据自身风险判断来扩展。
如何选择 Lite spec 与 Full spec?绝大多数变更应当保持在 Lite 模式。
Most changes should stay in Lite mode.
OpenSpec 认为,过度规范化和规范化不足一样有害。因此它提供了一个简单的决策树:
• 这个变更是否涉及跨团队协调? → 是 → Full • 是否涉及API 或数据库 schema 的破坏性变更? → 是 → Full • 是否可能导致安全或隐私事故? → 是 → Full • 如果需求写得不清楚,返工成本是否极高(例如影响核心交易链路)? → 是 → Full • 以上都不是 → Lite(默认)
OpenSpec 对规范 specs 的管理
OpenSpec 对于 specs 的管理分成两个部分:
• /specs:这个目录下存放的是项目当前对应的规范(类似 git 分支中的 main 分支)specs structure 例如:
openspec/specs/├── auth/│ └── spec.md # Authentication behavior├── payments/│ └── spec.md # Payment processing├── notifications/│ └── spec.md # Notification system└── ui/ └── spec.md # UI behavior and themes• /changes:这个目录下则存放的是正在进行开发的新需求的规范(类似 git 分支中的 feature 分支)注:一个需求一个目录(/changes/需求名),最终归档时会被转移,归档至 /changes/archive 目录,用于日后的履历审计changes structure 例如:
openspec/changes/add-dark-mode/├── proposal.md # Why and what├── design.md # How (technical approach)├── tasks.md # Implementation checklist├── .openspec.yaml # Change metadata (optional)└── specs/ # Delta specs └── ui/ └── spec.md # What's changing in ui/spec.md与 git 合并分支代码类似,OpenSpec 合并 spec 的过程就像将新开发功能的 feature 分支合并到 main 分支一样。
这种增量需求 specs 与已有 specs 的隔离,也有类似 git 分支开发的这种好处,便于并行地协作开发。
┌────────────────────────────────────────────────────────────────────┐│ openspec/ ││ ││ ┌─────────────────────┐ ┌───────────────────────────────┐ ││ │ specs/ │ │ changes/ │ ││ │ │ │ │ ││ │ Source of truth │◄─────│ Proposed modifications │ ││ │ How your system │ merge│ Each change = one folder │ ││ │ currently works │ │ Contains artifacts + deltas │ ││ │ │ │ │ ││ └─────────────────────┘ └───────────────────────────────┘ ││ │└────────────────────────────────────────────────────────────────────┘OpenSpec organizes your work into two main areas:
Specs are the source of truth — they describe how your system currently behaves.
Changes are proposed modifications — they live in separate folders until you're ready to merge them.
This separation is key. You can work on multiple changes in parallel without conflicts. You can review a change before it affects the main specs. And when you archive a change, its deltas merge cleanly into the source of truth.
OpenSpec工作流
默认工作流
Default quick path (core profile):
/opsx:explore(可选) ──► /opsx:propose ──► /opsx:apply ──► /opsx:sync(可选) ──► /opsx:archive注:在正式开始实现之前(/opsx:apply 之前),我们最好人工地确认下 propose 阶段输出的 artifacts(proposal.md,/specs,design.md,tasks.md)是否符合要求,如果不符合则需要进行修改。
| Command | Purpose |
/opsx:explore | |
/opsx:propose | |
/opsx:apply | |
/opsx:sync | |
/opsx:archive |
需求还不清楚? → /opsx:explore(可选)需求清楚了 → /opsx:propose <变更名或描述> ← 自动生成规划文档(自动挡) → 你看一下 proposal/design/tasks 是否 OK开始写代码 → /opsx:apply <变更名> ← 按 tasks 实现(必须单独触发)做完了 → /opsx:archive <变更名> ← 归档到 openspec/specs/扩展版本的工作流
Expanded path (custom workflow selection):
/opsx:explore(可选) ──► /opsx:new ──► /opsx:ff or /opsx:continue*N ──► /opsx:apply ──► /opsx:verify ──► /opsx:sync(可选)──► /opsx:archive| Command | Purpose |
/opsx:new | |
/opsx:continue | |
/opsx:ff | |
/opsx:verify | |
/opsx:bulk-archive | |
/opsx:onboard |
核心指令(Core)与扩展指令(Expanded):
| 步骤 | Core | Expanded(精细) | Expanded(快进) |
/opsx:explore | |||
/opsx:propose | newcontinue | newff | |
/opsx:apply | |||
/opsx:verify | |||
/opsx:sync | |||
/opsx:archive | |||
/opsx:propose = 把 /opsx:new 和多次 /opsx:continue 打包成一条命令,自动跑完规划阶段,中间不等你确认。
sync 与 archive
sync 负责“提前同步”,而 archive 则同时完成“最终合并”与“文件归档”这两个终结操作。
sync:Optional command. Merge delta specs from a change into main specs. Archive will prompt to sync if needed, so you typically don't need to run this manually.
archive:Archive a completed change. Finalizes the change and moves it to the archive folder.
archive 是规范合并的必经之路:无论你中间是否执行过 sync,执行 archive 命令时,OpenSpec 都会执行一次最终的、完整的规范合并。不执行 sync 不会影响最终结果。
那这个sync有什么意义呢?反正archive早晚都会将变更内容合并到主spec,既然 archive 最终也会合并,那 sync 看起来确实像是多此一举。
实际上,sync 的核心价值在于引入了一个可选的、在开发周期中间就同步规范的“检查点”,它解决了三个 archive 无法直接处理的问题:
1. 长周期变更中的“规范漂移”与冲突预防:如果一个大变更持续几周甚至一个月,不执行 sync,所有规范修改都只存在于 changes/ 目录下。其他人(或另一个分支)基于旧的 specs/ 开发时,很可能做出与你的变更冲突的修改。最终 archive 时,OpenSpec 需要处理大量合并冲突,有时甚至需要人工介入。sync 的作用:在开发进行到某个里程碑(比如完成了 30% 的功能)时,执行 sync 把已确定的规范提前合并到主 specs/。这样,其他人就能看到最新的规范,避免后期大规模冲突。同时,你的变更分支依然活跃,可以继续添加、修改规范。 2. 团队协作中的“可见性”需求:archive 只在所有任务都完成后才能合并规范。但在团队协作中,设计师、测试人员、其他开发人员往往需要尽早了解当前变更的规范细节,以便并行工作(如编写测试用例、准备文档)。sync 的作用:你可以在 apply 中途、部分规范已经稳定但功能未完全实现时,执行 sync,让团队的规范库立即反映最新设计。而 archive 要等到代码全部完成、测试通过之后,这显然太晚了。 3. 分阶段合并与部分发布:有时一个变更包含多个独立但相关的规范更新。你可能希望先合并其中一部分规范到主库,另一部分继续修改。archive 只能一次性合并全部。sync 的作用:你可以先 sync 确定的部分,让它们生效;然后从变更中删除已 sync 的规范 delta,只保留未稳定的部分继续开发。这样实现了对主规范的“部分发布”,而 archive 无法做到。
针对中间产出内容(artifact)的修改
中间产出内容(artifact)
首先我们需要明确下这里的中间产出内容(artifact)是指什么?
在 /opsx:propose,/opsx:continue,/opsx:ff 阶段,产出的是 artifact 文档:
| Artifact | 文件 | 内容 |
proposal.md | ||
specs/**/*.md | ||
design.md | ||
tasks.md |
修改原则
在开发过程中,大部分情况下,我们的输出内容并非一次就能令我们满意,这时我们就要对输出内容进行修改,那么我们要如何对 openspec 的产出结果进行修改呢?
核心原则:三种改法
• 方式1:直接改文件(最常用) • 方式2:对话里让 AI 改(不用特殊命令) • 方式3:改上游后,同步改下游(避免文档不一致)
注:/opsx:continue 只会创建 下一个尚未完成的 artifact;不会自动重写已标记为 done 的文件。已生成的文档要改,主要靠“编辑文件”或“让 AI 编辑”,而不是再跑一遍 continue。
一些问题
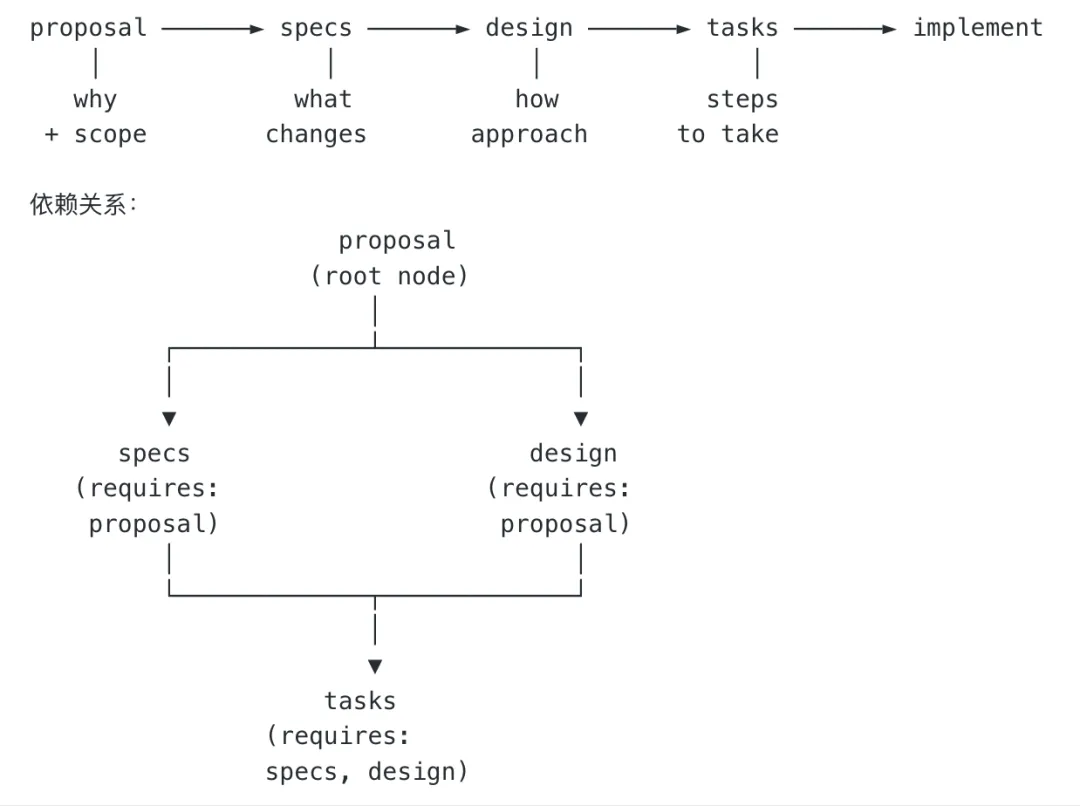
Q1:依赖链 proposal → specs → design → tasks → apply(代码)改上游时要不要改下游?
越改上游,越要主动要求同步下游,OpenSpec 不会自动级联重写。
| 改动部分 | 建议 |
proposal.md | |
specs/ | |
design.md | |
tasks.md |
Q2:各命令对修改已有 artifact 的行为是怎样的?
如下表所示
| 命令 | 能否用来修改已生成的 artifact? |
/opsx:continue | |
/opsx:ff | |
/opsx:propose | |
/opsx:apply |
Delivery与Workflows
openspec config profile 指令用来对 openspec 可使用的功能进行配置
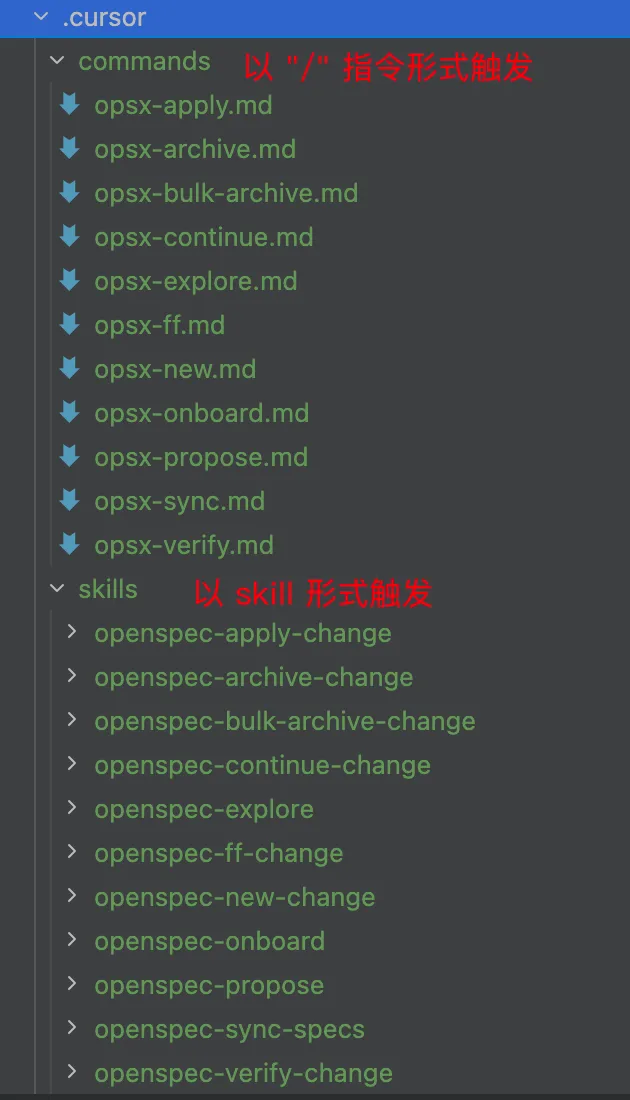
Delivery 管“怎么装”,Workflows 管“装哪些命令”:
• workflows 是指令集合,表示要安装哪些指令(propose, new, continue, ff, apply ……) • delivery 则是 workflows 中指令的安装方式(以skill的形式,还是以"/"指令的形式,还是both两者都要)
Delivery = where workflows are installed (skills, commands, or both)
Workflows = which actions are available (propose, explore, apply, etc.)
我们以 App 商店进行类比:
openspec update |
• 选 Workflows:决定装微信、地图还是相机(装哪些) • 选 Delivery:决定每个 App 是只放桌面、只加 Siri,还是两种都有(怎么装)
没选“地图” Workflow,Delivery 选什么都不会出现这个功能。选了“地图”,Delivery 只决定它是斜杠命令形式还是 Skill 形式,不会决定有没有这个功能。
The default global profile is core. To enable expanded workflow commands, run openspec config profile, select workflows, then run openspec update in your project.
相关参考
open spec 快速开始:https://github.com/Fission-AI/OpenSpec/blob/main/docs/getting-started.md
open spec 工作流:https://github.com/Fission-AI/OpenSpec/blob/main/docs/workflows.md
open spec 命令说明:https://github.com/Fission-AI/OpenSpec/blob/main/docs/commands.md
open spec 设计理念:https://github.com/Fission-AI/OpenSpec/blob/main/docs/concepts.md
