 夜雨聆风
夜雨聆风要了解AI在企业中的边界和能力,记住华为的数据分类会事半功倍
AI的“无所不能”与企业数据的“严苛秩序”之间,横亘着一道鸿沟。
当人们被AI的宏大叙事所吸引,期待它能“理解一切、处理一切、优化一切”时,现实往往带来清醒的认知。AI模型在处理一份文采斐然的报告时表现出色,却可能在一张看似简单的财务报表上“栽跟头”,给出自相矛盾的数字逻辑。
这种矛盾并非技术失灵,而是源于对AI能力本质的不了解。要清晰地界定AI在企业中能做什么、不能做什么,以及它以何种“形态”在企业中运作,一个认知框架至关重要——那就是华为的数据分类图。这个分类也基本是各个行业组织比如DAMA推荐的分类方式,这个分类是理解当代AI在企业中真实效能和边界,以及当下最热的“本体论”的关键。
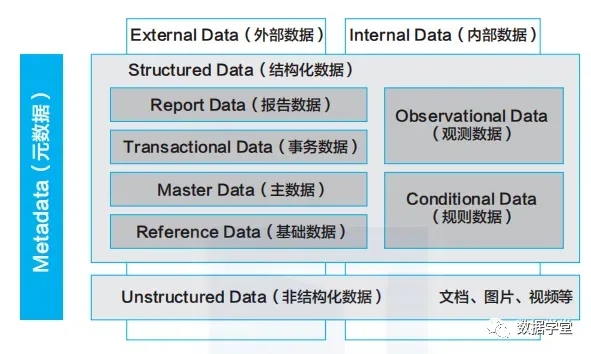
一、 秩序与富矿:企业数据世界的二元结构
结构化数据和非结构化数据的分类,清晰地展现了企业数据世界的“两部分”,这不仅是存储方式的差异,更是当下AI属性的分野:
结构化数据:秩序的王国
这是企业IT系统的基石,是高度标准化、可被数据库直接理解和处理的确定性信息。它们通常存在于ERP、CRM、财务等核心业务系统中。在华为的分类中,它主要包括:
基础数据:如国家代码、币种、会计科目,是企业运作的“字母表”。
主数据:如客户、产品、供应商、员工,是业务运作的“核心名词”,必须保证唯一、准确、权威。
事务数据:如销售订单、采购发票、银行交易,记录了业务发生的“动词”,是主数据之间互动的记录。
结构化数据的世界,遵循着精确、一致、唯一、可追溯的铁律。这是一个依靠严谨逻辑和强制约束运行的“刚性系统”,其价值在于绝对的准确性。
非结构化数据:富饶的沃土
这是企业数据的“富矿”,包括文档、合同、设计图纸、会议纪要、音视频文件、邮件等。它们没有预设的格式,信息以自然语言、图像、声音等形式存在,高度依赖人类的语义理解。
非结构化数据的世界,遵循着丰富、多元、隐含、关联的逻辑。其价值在于所承载的语义、意图、知识和语境。这是一个依赖人类认知进行解读的“柔性系统”。

二、 大语言模型的“先天基因”与“后天局限”
当前AI浪潮的核心驱动力是大语言模型。理解LLM的本质,是判断其企业应用边界的起点。
1. LLM的本质:一部“非结构化世界的统计模型”
大语言模型是通过对海量、公开、非结构化的文本、代码、图像数据进行学习而训练出来的。本质上,它是一台“统计语义预测机”。它通过学习海量语料中符号之间的概率关联,构建了一个对非结构化世界的庞大、复杂的“压缩模型”。
因此,在它的“舒适区”——处理语义、逻辑、修辞、创意、风格、关联等任务时,表现出强大能力:
总结一份行业报告:擅长提炼、归纳语义。
撰写商务邮件:掌握语言风格和社交规范。
检查合同格式和明显矛盾:学习了海量的法律文本模式。
解释复杂技术原理:能关联不同领域的知识片段。
LLM的强大,根植于它对人类“自然语言”这个最复杂的非结构化信息载体的掌握。

2. LLM的天生短板:面对“结构化秩序”的无力感
然而,当LLM从开放、多样的互联网世界,踏入企业严谨、精确的结构化数据领域时,其“概率”本质构成了根本性障碍。
概率性 vs. 精确性:LLM生成答案基于概率,倾向于给出“最合理”的答案。但企业结构化数据要求100%精确。在财务报表中,“99.9%正确”意味着“完全错误”。
关联性 vs. 因果性:LLM能发现“A和B经常一起出现”的强关联,但它无法理解企业内部“为什么A会导致B”的刚性业务规则和系统逻辑。例如,它无法理解“成本中心A的费用不能计入项目B”这条铁律背后的财务合规要求。
语义理解 vs. 数据治理:LLM能理解“客户”这个概念,但它无法确保,也无法操作系统核心的、由主外键关联、约束关系和严格变更流程构成的治理体系。
生成性幻觉 vs. 数据真实性:LLM的“幻觉”特性,是其在处理创造性任务时的副产品,但却是企业数据管理中的“灾难”。它可能“创造”一个不存在的客户,或“推理”出一笔从未发生的交易。
简而言之,LLM是在“非结构化富矿”中生长出的、具备强大“联想”和“表达”能力的“语言大脑”,但它缺少处理“结构化秩序”所必需的、基于严谨业务规则的“逻辑小脑”。
三、 在企业中,正确应用AI
基于以上理解,我们可以用数据分类框架,为企业AI的应用绘制一张清晰的地图。AI在企业中的“本体”——即其核心存在形态和运作方式——并非一个全能的“超级大脑”,而更应该是一个精准的 “翻译官”和“连接界面” 。
1. 在“非结构化数据”沃土上,作为“挖掘者”和“提炼者”
这是当前LLM发挥核心价值的主战场。企业应积极引入AI,作为处理这部分数据的“超级员工”,其本体是知识的挖掘与提炼引擎:
文档智能:自动阅读、理解、分类、抽取海量合同、报告、邮件中的关键信息,将其转化为可供系统处理的、初步结构化的数据。这是从“富矿”中提炼“矿石” 的关键一步。
知识库问答:基于企业内部文档构建智能问答系统,让员工能像与专家对话一样,快速获取知识。
内容生成与润色:辅助撰写市场文案、技术文档、会议纪要等。
2. 在“结构化数据”王国边,作为“连接者”和“解释者”
在结构化数据领域,要发挥AI的价值,就必须定义、规划和设计好“本体”。
有本体的AI可以作为核心“禁区”的辅助者:在基础数据、主数据的管理中,AI的角色必须是受控的辅助,只能进行查重校验、异常侦测、信息关联展示,绝不能参与核心的生成、定义和审批。其存在是为了增强人类对确定性的控制,而非替代。
有本体的AI可以是连接两个世界的“界面”:AI的价值之一,在于连接结构化与非结构化世界。
有本体的AI甚至可以是行动的“解释器”与“触发器”:一个具备“本体”能力的AI,不仅能查询,还能在理解业务规则(如“当库存低于安全库存时,应触发补货申请”)后,将自然语言指令(“为畅销品SKU123创建补货单”)转化为在ERP中创建一张准确工单的具体操作。其本体,此时是一个理解语义、遵循规则、触发确定动作的“智能体”。
这里的“企业本体”,指的是由人类明确定义的、关于企业核心概念(客户、订单、产品)、它们之间的关系以及业务规则的清晰图谱。 AI依赖这张图谱来“理解”企业,并安全地行动。没有这个由人类定义的本体,AI就无法可靠地连接两个世界。
结论:理性锚定,让AI扎根于正确的土壤
对AI的盲目崇拜或恐惧,都源于对其能力边界认知的模糊。数据分类框架,为我们提供了这份客观的“能力与存在地图”。
理解这张分类图,就是理解了AI在企业中能力范围的“第一性原理”,也定义了其存在和创造价值的正确形态。
