 夜雨聆风
夜雨聆风项目地址:chopratejas/headroom
官方文档:headroom-docs.vercel.app
PyPI 最新版本:0.22.4,发布于 2026-05-26
Headroom GitHub
AI Agent 消耗的 token,很多来自工具返回的内容。
查一次代码,工具可能返回几百条搜索结果。跑一次测试,日志会继续占用上下文。接上 RAG 后,应用还会把一批文档片段送进模型。Agent 开始回答前,输入窗口可能已经塞进了大量工具输出。
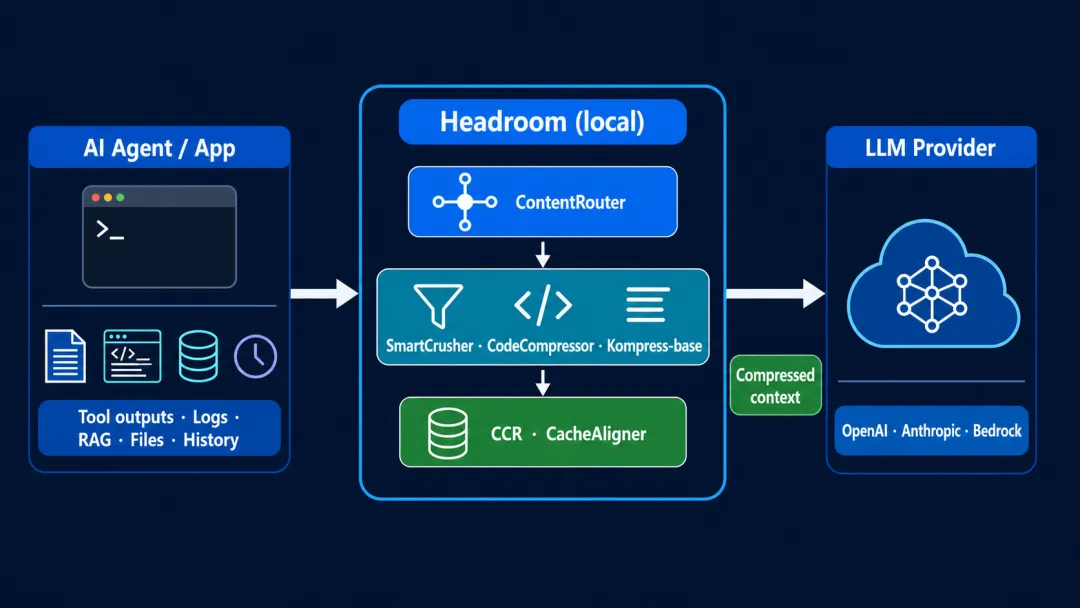
Headroom 在这些内容到达大模型前,先在本地压缩一遍。
仓库把它称为 AI Agent 的“上下文压缩层”。README 列出的处理对象包括工具输出、日志、RAG 结果、文件内容和会话历史。Headroom 压缩这些内容后,再把结果交给 OpenAI、Anthropic、Bedrock 等模型服务。
当前限制文档说明,默认配置下的 RAG 文档上下文可能直接透传。准备压缩 RAG 内容时,先用自己的数据确认行为。
Headroom 用来做什么
Headroom 是放在 Agent 和大模型之间的中间层:
Headroom 上下文压缩流程图
你可以按现有技术栈选择接入方式。
from headroom import compress | ||
headroom proxy --port 8787 | ||
headroom wrap ... | ||
headroom mcp install | ||
SharedContext | ||
headroom learn |
README 列出的包装器包括 Claude Code、Codex、Cursor、Aider 和 Copilot CLI。兼容 OpenAI API 的客户端可以走代理模式。
压缩流程
直接截断日志可能删掉末尾的错误信息。Headroom 会先判断内容类型,再选择压缩器:
SmartCrusher | |
CodeCompressor | |
LogCompressor | |
SearchCompressor | |
Kompress-base |
它还提供以下能力:
CacheAligner稳定提示词前缀,提高模型服务商的 KV Cache 命中率。 ContentRouter识别 JSON、代码、日志、文本等内容。 IntelligentContext根据相关性、新旧程度和错误信号安排上下文预算。 CCR保存原始内容,模型需要细节时可以按需取回。
模型第一次看到的是压缩结果。即使 CCR 保存了原文,精确审计、完整数据核对等任务仍要测试压缩策略。
适用场景
以下 Agent 场景有较大的压缩空间:
一次搜索返回几十到几百条结果 数据库查询或 API 返回大段 JSON 测试、构建、部署日志重复内容很多 长时间运行的多工具 Agent,持续累积历史上下文 多个 Agent 之间需要共享记忆
官方 README 展示的部分工作负载减少了 60% 到 95% 的 tokens。限制文档指出,短对话、单轮请求和纯代码会话的收益可能很小。
代码压缩带有保护规则。Headroom 默认会保留最近读取的代码,以及用户要求分析或修复的代码,避免压掉正在使用的函数体。
安装前先确认环境
Python 版本要求是 3.10+。
bash python --version
先创建虚拟环境,避免影响其他 Python 项目。
Windows PowerShell:
powershell python -m venv .venv
.\.venv\Scripts\Activate.ps1
macOS 或 Linux:
bash python3 -m venv .venv
source .venv/bin/activate
安装 Headroom
只在 Python 代码里调用
bash pip install headroom-ai
基础包包含 compress()、SmartCrusher、CacheAligner 和 IntelligentContext。在 Python 应用里压缩上下文,可以安装基础包。
验证安装:
bash python -c "import headroom; print(headroom.__version__)"
想用代理、包装器、MCP 或完整功能
安装完整功能:
bash pip install "headroom-ai[all]"
按需安装:
bash pip install "headroom-ai[proxy]"
pip install "headroom-ai[mcp]"
pip install "headroom-ai[code]"
pip install "headroom-ai[ml]"
pip install "headroom-ai[langchain]"
[ml] 会加入文本压缩所需的模型依赖,安装体积更大。只处理 JSON、日志或结构化工具输出时,可以先跳过它。
使用 headroom proxy、headroom wrap 或其他 CLI 功能时,安装 [proxy] 或 [all]。
[proxy] 会带上 FastAPI、ONNX Runtime、Transformers 等依赖,第一次安装需要多等一会儿。
我在 Windows + Python 3.10 环境安装 0.22.4 时,PyPI 下载了源码包并现场构建 wheel。安装日志出现 Building wheel for headroom-ai 属于正常过程。构建失败时,可以先升级 pip,或改用官方安装文档建议的解释器。
Node.js / TypeScript
bash npm install headroom-ai
Node SDK 需要一个正在运行的 Python Headroom 代理:
bash pip install "headroom-ai[proxy]"
headroom proxy --port 8787
TypeScript SDK 会通过 HTTP 请求本地代理。
Docker
bash docker pull ghcr.io/chopratejas/headroom:latest
docker run -p 8787:8787 ghcr.io/chopratejas/headroom:latest
跑一个无需 API Key 的本地 demo
仓库提供了一个无需 API Key 的 SmartCrusher 演示:
bash python -m examples.langchain_demo.show_compression
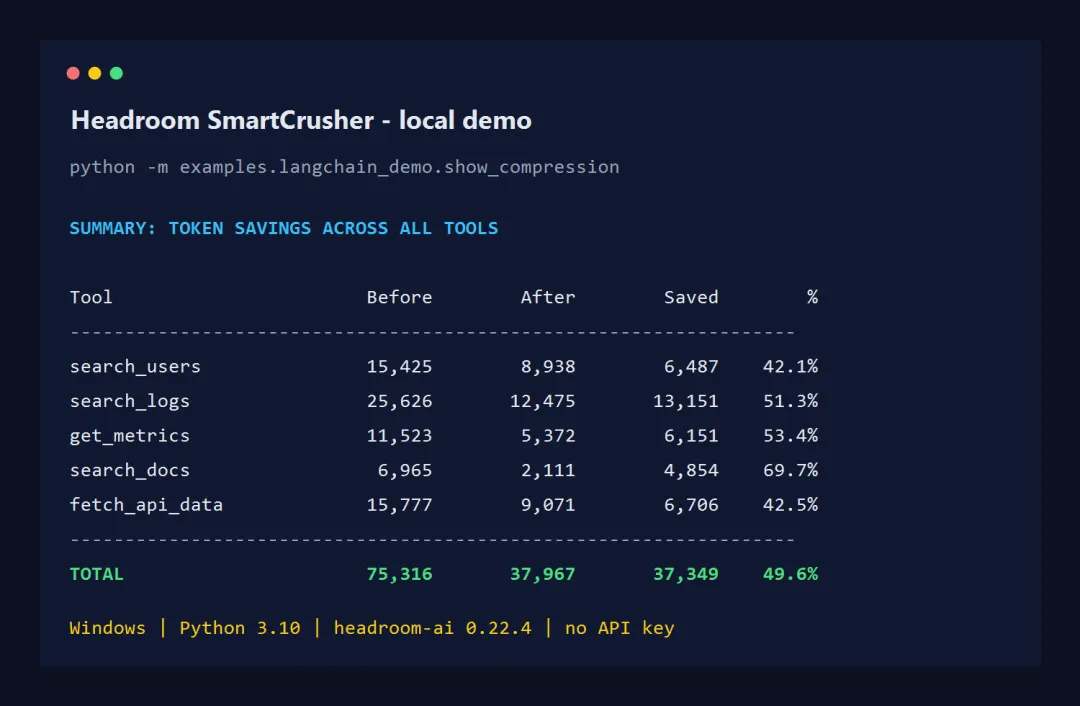
我在本机使用 headroom-ai 0.22.4 跑了一次。五组工具输出从 75,316 tokens 压到 37,967,节省 49.6%。
Headroom 本机 demo 实跑结果
本机结果低于 README 展示的高压缩率案例。结构化、重复较多的内容有更大的压缩空间;短内容和独特内容的收益会少一些。
新建 demo_headroom.py,可以运行一个更小的 demo:
python import json
import tiktoken
from headroom.config import SmartCrusherConfig
from headroom.providers import OpenAIProvider
from headroom.transforms import SmartCrusher
def count_tokens(text: str) -> int:
encoder = tiktoken.get_encoding("cl100k_base")
return len(encoder.encode(text))
results = []
for index in range(200):
status = "ERROR"if index in {17, 133} else"ok"
results.append(
{
"id": index,
"service": "payment-service",
"status": status,
"message": (
"Database connection timeout after retry. "if status == "ERROR"else"Request completed successfully. "
)
* 8,
"trace_id": f"trace_{index:04d}",
}
)
raw_output = json.dumps({"results": results})
messages = [
{"role": "user", "content": "Find ERROR entries in the payment-service results."},
{"role": "tool", "tool_call_id": "call_1", "content": raw_output},
]
tokenizer = OpenAIProvider().get_token_counter("gpt-4o")
crusher = SmartCrusher(
config=SmartCrusherConfig(
enabled=True,
min_tokens_to_crush=200,
max_items_after_crush=15,
)
)
result = crusher.apply(messages, tokenizer=tokenizer)
compressed_output = result.messages[-1]["content"]
before = count_tokens(raw_output)
after = count_tokens(compressed_output)
print(f"Tokens before: {before:,}")
print(f"Tokens after: {after:,}")
print(f"Tokens saved: {before - after:,} ({(before - after) / before:.1%})")
print(f"ERROR preserved: {'ERROR' in compressed_output}")
运行:
bash python demo_headroom.py
脚本只在本地压缩一段模拟的工具输出,不会调用 OpenAI 或 Anthropic。
三种常用接入方式
方式一:在 Python 应用里调用 compress()
python from headroom import compress
result = compress(messages, model="gpt-4o")
print(result.tokens_before)
print(result.tokens_after)
print(result.tokens_saved)
compressed_messages = result.messages
接着将 result.messages 发送给模型。
方式二:启动本地代理
bash headroom proxy --port 8787
OpenAI 兼容客户端可以把 Base URL 指向:
text http://localhost:8787/v1
代理模式适合已有应用。Headroom 接收请求,压缩上下文,再转发给模型服务商。业务代码只需修改 Base URL。
方式三:给编码 Agent 加包装器或 MCP
bash headroom wrap claude
headroom wrap codex
MCP 模式提供三个核心工具:
headroom_compress:压缩内容 headroom_retrieve:按哈希取回原文 headroom_stats:查看节省的 tokens 和费用估算
Claude Code 可以注册 MCP Server:
bash headroom mcp install
其他 MCP 客户端可以连接 headroom mcp serve,或连接代理暴露的 /mcp 地址。
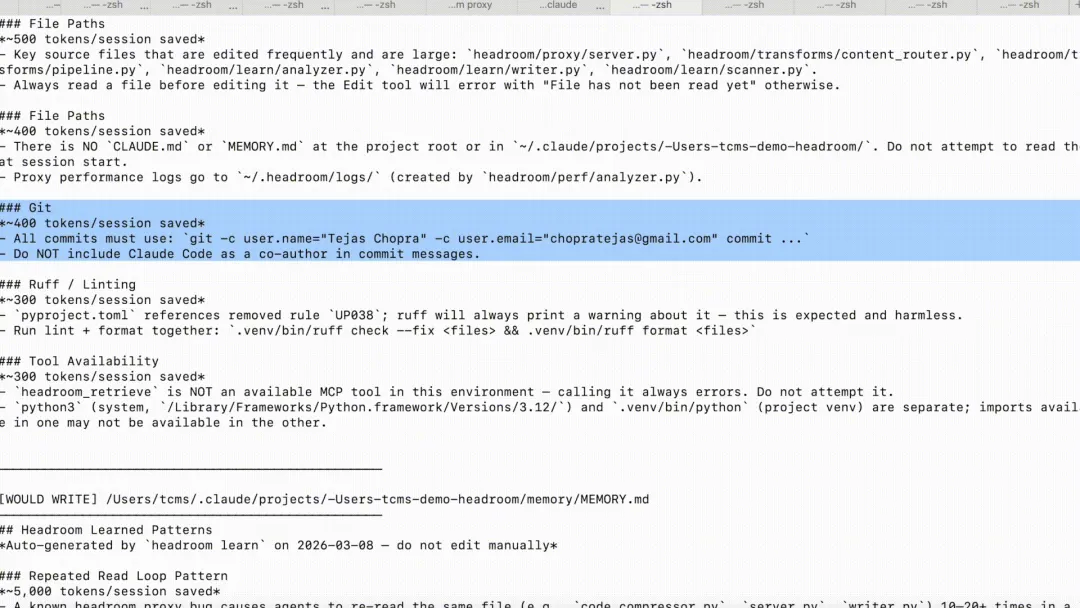
headroom learn:从失败会话提取项目规则
headroom learn 会从失败会话里找出重复出现的问题,再把修正建议写进 CLAUDE.md、AGENTS.md 或 GEMINI.md。
Headroom learn 官方演示
如果 Agent 反复在同一个路径、命令或项目约定上犯错,更大的上下文未必能解决问题。将修正写进项目规则,可以减少下一次会话里的重复错误。
使用边界
1. 模型请求仍会离开本机
Headroom 可以在本机完成压缩和原文存储。压缩后的请求仍会发送给你使用的模型服务商。需要隐私隔离时,仍要使用符合要求的模型部署方式。
2. 压缩率取决于内容
JSON 数组、重复日志和批量搜索结果更好压。短消息、单轮请求和紧凑内容可能几乎没有收益。
3. 精确任务要做 A/B 测试
逐行核对、完整审计等任务要先用真实数据验证答案质量。CCR 可以取回原文,模型是否会取回原文取决于接入方式和任务过程。
4. 从源码目录运行示例时,注意 Python 导入路径
我在 Windows 上测试时,从仓库根目录运行示例会优先导入源码目录,Python 因此找不到 wheel 中已编译的 headroom._core。
按照贡献文档安装开发版依赖:
bash git clone https://github.com/chopratejas/headroom.git
cd headroom
pip install -e ".[dev]"
只体验功能时,可以安装 PyPI 包并运行自己的 demo。
接入前的判断
工具输出多、日志重复、JSON 响应大的 Agent 有较大的压缩空间。
压缩会改变模型第一次看到的内容,也会增加本地依赖和调试成本。决定是否接入前,拿真实工作负载比较 token 消耗和答案质量。
项目地址:
GitHub:https://github.com/chopratejas/headroom 官方文档:https://headroom-docs.vercel.app/docs 安装文档:https://headroom-docs.vercel.app/docs/installation 限制说明:https://headroom-docs.vercel.app/docs/limitations
