 夜雨聆风
夜雨聆风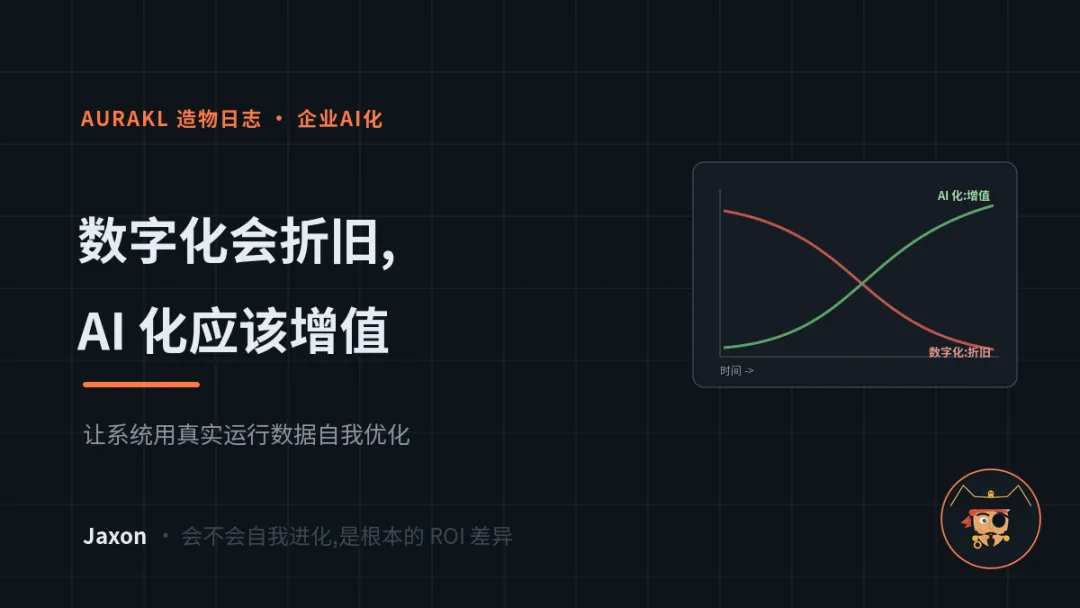
封面:数字化系统建好即折旧,AI 化系统应该越跑越值钱
系列:01 数字化 vs AI化 → 02 模型无关底座 → 03 SOP 起点 → 04 关键步骤 → 05 治理 → 06 组织记忆 → 07 多 Agent → 08 自我进化(你在这里) → 09 组织重构 → 10 路线图
「企业AI化转型」系列地图——你在第 8 站:自我进化
上一篇我们把团队搭起来了——多 Agent 各管一摊,协作协议模型无关。这一篇答下一个问题:团队跑起来了——可怎么让它越跑越值钱,而不是像数字化系统那样建好就开始折旧?
TL;DR
· 数字化系统建好那天就开始折旧;AI 化系统应该相反——交付即起点,用运行数据自我优化、越跑越值钱。
· 适合 CTO / CIO / 数字化负责人评估 AI 投资回报,以及给"看起来在跑但没在变好"的 AI 应用补上自进化闭环。
· 看完你能拿到三步落地法(评估闭环 / 在模型外那层改 / 可控可回滚)+ 数字化 vs AI 化对比 + 一份"AI 写报告"系统的样板。
▸ 自我进化 = 用真实运行数据持续评估自己、自动改流程/提示/技能(模型外那层),且每一步可控可回滚。
会自我进化的 AI 系统,是一种"用真实运行数据持续评估自己、自动改进流程/提示/技能(都在模型之外那一层)、且每一步可控可回滚"的系统。 它在 AI 能力栈里的位置是把"评估"从"上线时验收一次"变成"系统每天都在做的事";改进对象是模型外那层,所以换更强模型时自优化能力还在,而且更强。
两个容易混的词:监控只是看见问题(仪表盘);自我进化是看见之后系统能自己把流程/提示/技能改好,而不是攒一堆报表等人来改。前者会折旧,后者才会增值。
▸ 数字化系统建好即折旧;AI 化系统每天产生运行数据,理应反过来让自己越跑越好——这才是 AI 化 vs 数字化的根本 ROI 差异。
数字化系统有个谁都默认却很少说破的特性:建好那天起,它就开始折旧——需求变了它跟不上,流程改了要排期改造,几年后变成谁都不敢碰的"祖传系统"。AI 化系统的曲线应该是反过来的:每天产生真实运行数据,这些数据反过来自动评估并优化它自己。
但市面上多数所谓的"AI 落地",仍然在按数字化的节奏交付——上线时验收一次,然后等出问题再人工改。这本质上是把 AI 当一次性项目,不是当能升值的资产。
反直觉的判断:评估一个 AI 投资,加一条硬尺子——"它会用运行数据让自己越来越好吗?" 答"会"的才是资产;答"不会"的,无论模型多强、上线表现多炫,都只是会说话的数字化系统,几个月后开始折旧。
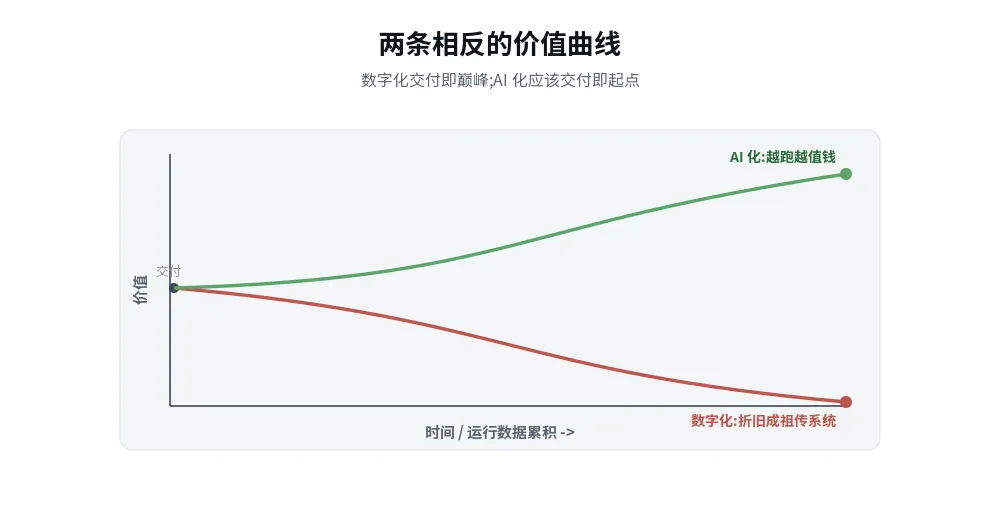
两条相反的价值曲线:数字化折旧 vs AI 化增值
▸ 三步:评估是系统每天自己做的事 / 自优化在模型外那层 / 可控可回滚。
▸ 直答:每跑一遍系统就用真实结果回头看——成功率/反复出错点/耗时漂移,自动算、自动汇总、自动告警。
评估不是季度抽查、不是上线验收,是系统每跑一遍就用真实结果回头看的内建动作——成功率、反复出错点、耗时漂移,自动计算、自动汇总。
怎么落:
· 每个步骤的执行结果带"标准答案 / 客观判定 / 用户反馈"中至少一种信号
· 系统自动算每个步骤的成功率、误差率、耗时趋势——按日聚合,按周看趋势
· 异常(成功率掉了 X%、误差率升了 Y%)自动告警到 SOP Owner,不等人巡检
常见踩坑:把"评估"做成季度报表——拿到时数据已经是上季度的,改也来不及。
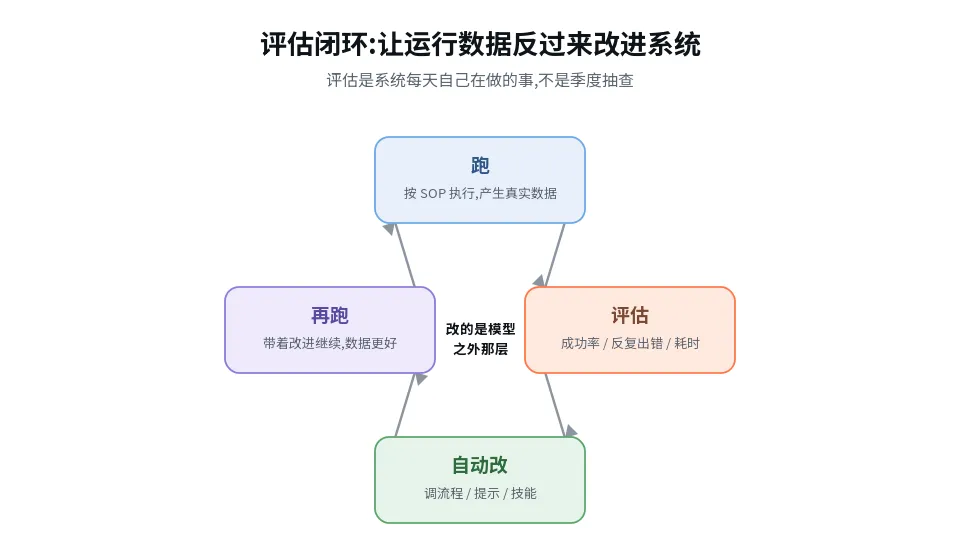
评估闭环:跑 → 评估 → 改流程/提示/技能 → 再跑
▸ 直答:闭环改的是 SOP / 提示 / 技能配置——模型外那层;换模型时自优化能力一行不重建。
闭环改的是 SOP、提示、技能配置——模型之外那层。这样有个复利效应:换一代更强的模型进来,这套"会自优化"的能力还在,而且因为模型更强,它优化得更准、更快。
怎么落:
· 自优化对象明确:工作流 spec、prompt 模板、技能配置、调度规则——这四类
· 模型本身不动(也别去 fine-tune):换基础模型时,自优化能力一行不重建
· 每次自动改动留版本号 / 改动原因 / 改前改后对比数据
常见踩坑:把"自优化"做成"自动 fine-tune 模型"——绑死当下模型,还把可解释性丢光。
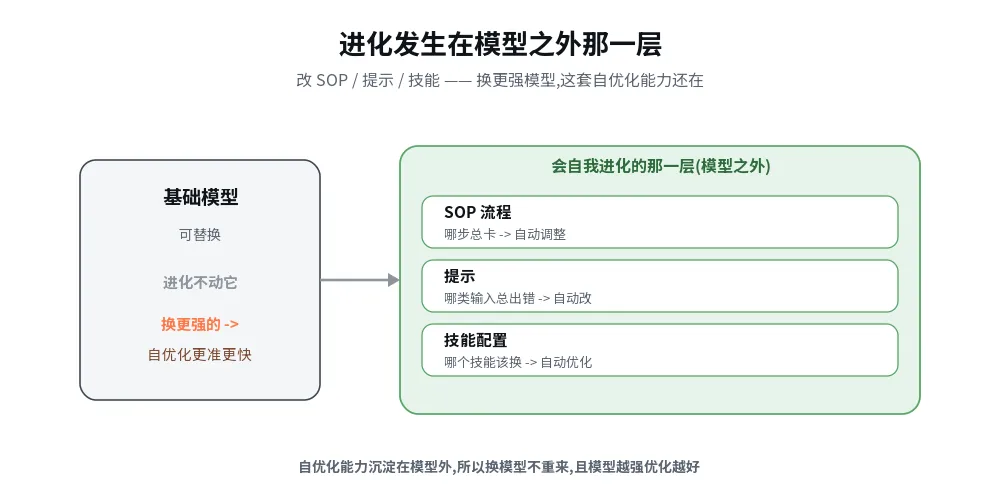
进化发生在模型之外那层:换模型,自优化能力还在
▸ 直答:分级改动 + 灰度 + 一键回滚;让系统全量自动改自己是给自己埋坑。
系统自己改自己,听着很美,但前提是每一步可审计、可回退。不能让它在没人盯的情况下把自己悄悄改坏了还没人知道。进化的自由,必须装在治理的笼子里。
怎么落:
· 每次自动改动,变更类型分级:小改自动上线(改提示阈值)/ 中改要 Skill Reviewer 批 / 大改(改关键 SOP)必须 HITL
· 灰度发布:新改动先跑 5%–10% 流量,跟旧版本对比指标,达标再全量
· 一键回滚:任何改动有回退按钮,出问题立刻回上一版
常见踩坑:让系统全量自动改自己——出过一次事就再也没人敢信"自动进化"了;一开始就该分级 + 灰度 + 回滚。
· [ ] 系统每跑一遍都能自动产出评估数据(成功率/误差率/耗时)
· [ ] 自优化对象明确是模型外那层(SOP/prompt/skill/调度)
· [ ] 模型本身不动,可独立升级,不重建自优化能力
· [ ] 每次自动改动有版本号、原因、改前改后数据
· [ ] 改动分级:小自动 / 中要 Skill Reviewer / 大必须 HITL
· [ ] 灰度发布 + 一键回滚的机制都已内建
· [ ] 我会用"一年后是不是比现在好"作为 ROI 评估口径,不止看上线时表现
▸ AI 写财报摘要/市场周报/客户回访总结,上线时光鲜——三个月后开始悄悄变差,没人知道哪环开始下滑。
Before · 三个卡点
▸ AI 报告应用上线惊艳;三个月后投诉变多;团队第一反应"换更贵的模型"。
· 公司上线了一个"AI 写报告"应用(财报摘要 / 市场周报 / 客户回访总结)——上线时效果惊艳,业务部门很满意;
· 但三个月后开始有投诉——某些报告"结论不对、引用不全、格式飘"——产品负责人也不知道哪环开始下滑;
· 内部讨论是"模型不够强吧 / 换个更贵的模型试试" → 换完成本翻倍效果只略好,而且 prompt 全部要重调。
落地这套打法 · 三件事
▸ 加双信号评估 + 模型外那层自动改 + 改动分级 + 灰度。
· 给每种报告类型加上"客观规则校验 + 业务方反馈"双信号,系统每天自动算成功率;按日按周看趋势,异常自动报到产品负责人 + SOP Owner;
· 自优化对象明确为模型外那层——发现某类报告引用不全 → 系统自动改对应的工作流分支或 prompt 模板(不动模型);Skill Reviewer 周度审查改动批量;
· 改动分级:微调阈值/措辞 = 灰度自动上线;改逻辑分支 = Reviewer 批;改"评估口径"本身 = 必须 HITL + 留版本号。
After · 三个变化
▸ 三个月自动修复 N 处局部退化;升级模型时已沉淀的自优化历史不重建;立项口径从"换更贵模型"变成"自优化曲线还在不在涨"。
· 三个月运营下来,系统自己识别并修复了 40+ 处局部退化;产品负责人每周只需看几条"非常规改动"的审批清单;
· 换基础模型时,自优化历史(已沉淀的 SOP/prompt/skill 改动)一行不重建,新模型上来立刻吃到这些累积优化的红利;
· 内部对"AI 投资该不该追加"的讨论,从"模型选型 vs 不选"换成了"自优化曲线还在不在涨";口径变了,决策快了。
两个关键决策点:
1. 自优化范围放多大? 保守:只让它改提示词阈值;激进:让它改整条工作流分支。我建议按"出错代价"分级——低代价区(提示阈值、措辞)自动改 + 灰度;中代价区(分支逻辑)Reviewer 批;高代价区(评估口径、关键 SOP)必须 HITL——这条线和治理那篇是一脉相承的。
2. 评估信号怎么拿? 有客观规则最理想(财报摘要类:数字对得上对不上);没客观规则的(开放生成类)用"用户反馈 + LLM-as-judge 双信号叉验",单一信号容易被操纵或漂移。
▸ 评估闭环 / 自优化引擎 / 改动治理三件事内建,自优化对象限定在模型外那一层。
我把"用运行数据自我进化"做成系统里一层独立的能力——评估闭环、自优化引擎、改动治理三件事内建。自优化对象限定在模型外那一层(工作流 / 提示 / 技能),模型自身不动。设计动机就是那条最高判据——模型升一代,这套自优化能力不重建,而且因为模型更强,自己改得更准更快。
▸ 加监控只让你看见问题;内建闭环让系统自己把流程/提示/技能改好,前者是折旧的仪表盘,后者才是增值的系统。
用模型给输出打分(LLM-as-judge)、反馈闭环、持续改进 / CI——这些机制本身不新。关键差别在:不是"能不能加监控和反馈",是"把'用运行数据自动改自己'做成系统内建的闭环,而且改的是模型外那一层,可控可回滚"。加监控只是看见问题;真正的差别是看见之后,系统能不能自己把流程/提示/技能改好,而不是攒一堆报表等人来改。前者是会折旧的仪表盘,后者才是会增值的系统。
▸ 决策者最常问的六个问题。
Q1:这跟普通的"持续优化"有什么不同? 持续优化是"人定期改",自我进化是"系统按规则自动改 + 人审 / 兜底"。后者改动频率高一两个数量级,而且只要治理设计对了,质量不下降。
Q2:让系统自动改自己,风险不大吗? 风险来自"不分级一刀切让它改"。分级 + 灰度 + 回滚装进去之后,自动改的实际风险比"季度批量人工大改"还低——因为每次改得小、灰度看得准、出问题立刻退。
Q3:这跟"在线学习/模型自训练"是一回事吗? 不是。在线学习/自训练是改模型本身——绑死当前模型,可解释性差,也很难回滚。本文讲的"自进化"明确不动模型,只改模型外那层(SOP/提示/技能),好处是可控、可换模型、可回滚。
Q4:自动改的"改动来源"是什么? 三个来源:运行数据上的异常告警(掉成功率/升误差率)、用户反馈聚类(同类投诉)、Skill Reviewer 周度复盘(主动发现)。三路汇总后,系统按规则提出"建议改动",分级走治理流程。
Q5:小公司也要做这一套吗? 看 AI 是不是核心。如果 AI 只是边缘工具,人工偶尔改一下够用;一旦 AI 跑核心流程,自进化闭环就必须做,否则三个月后开始悄悄折旧,你还不知道。
Q6:怎么衡量这套"在变好"? 看三个指标:自动改动次数 / 周(过低说明闭环没跑起来)、改动通过率(自动改动经治理审核被回滚的比例,过高说明分级或灰度有问题)、核心业务指标月度趋势(成功率、客户满意度、转化等——这是终极判据)。
数字化系统交付即巅峰,之后一路折旧;AI 化系统应该交付即起点,越跑越值钱。差别就在于它会不会用真实运行数据自我评估、自我优化——而且改的是模型之外那层,可控可回滚。这把 AI 化的"价值曲线"扳到了向上——可技术上的"会进化"还不够,你公司里得有人对它负责:谁定 SOP、谁审技能、谁兜底、谁治理。下一篇我们答这件事:为什么 AI 化真正难的不是技术,是组织能力重构。
我在用 Rust 从零做 aurakl,把"用运行数据自我进化"当核心闭环来设计,这类取舍会持续写。你们现在的 AI 系统,价值曲线是在往上走,还是已经开始折旧了?欢迎在简介里找到社区聊聊。
Jaxon · 从零做 aurakl(Rust 自我进化框架);写企业从数字化走到 AI 化的设计取舍。
