 夜雨聆风
夜雨聆风用AI搭了一个"会自己长"的知识库
想让AI能智能挂载你的专属上下文进行工作并不断丰富内容,你可能需要搭建一套知识库。今天不聊具体内容,只聊方法。
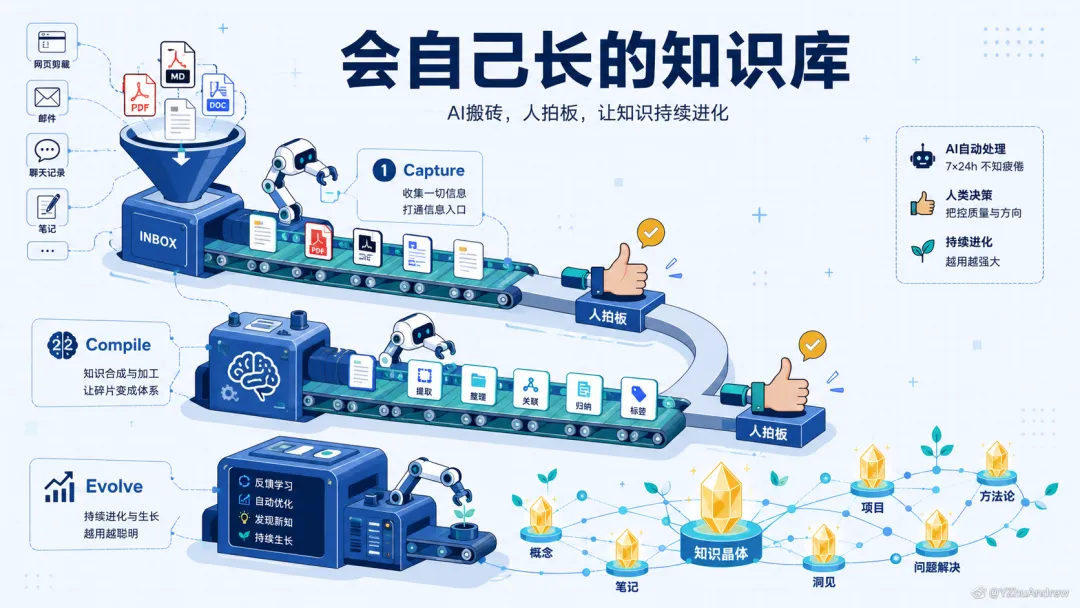
核心就一句话:AI 搬砖,人拍板。
(关注公众号,回复:obsidian获取知识库仓库模板)
知识库 ≠ 仓库
大多数人的知识管理止步于"收藏"。
收藏 ≠ 拥有。
知识库应该是加工厂,不是仓库。原料进来,加工成成品,随时能用。
骨架:数字编号分类法
首位数字 = 大类,第二位 = 子类。简单、稳定、AI 友好。
三个设计要点:
关键设计:文件夹给人看,属性给 AI 看
文件夹分类解决的是"人怎么找文件"。但 AI 不翻文件夹——它靠的是每篇笔记的属性元数据。
举个具体例子,一篇笔记的属性长这样:
---origin: collected # 谁写的?collected = 别人的created: 2026-05-31 # 什么时候创建的类型: 经验交流 # 内容性质tags: [风险管理, 纪检] # 主题标签---AI 看到这些属性,就知道怎么分类、能不能和其他文件一起编译、该归到哪个知识主题下。属性设计得越规范,AI 处理得越准。
这也是为什么我的知识库能实现自动编译——每篇笔记都自带"身份证",AI 按属性筛选同主题文件,比靠文件名猜测靠谱得多。
核心引擎:三级管线
第一级的关键设计:AI 只建议,人不点头不算数。所有 AI 处理结果先进"待阅区",确认后才正式归档。
第二级是精华:把散落各处的同主题材料综合提炼成一份知识页面,附带来源追溯和置信度。信息不被关联就是零价值。
第三级让系统自进化:标签用多了自动入库,没人用的自动建议淘汰。越用越贴合你的需要。
编译前后对比
实战案例:写进工作计划两年的事,AI 几小时搞定
我写过一篇公众号文章,讲的是建案例库这件事——两年写进工作计划都没落地,最后用 AI 几个小时搞定。整个过程就是三级管线跑了一遍:
关键经验:模板设计是人的活,AI 帮不了——但一旦模板定好了,后面全是 AI 的活。改了三版才定下来,说明这个环节值得投入时间。Agent督办我工作计划里“吹的牛”,然后她帮我几个小时搞定
关于这条案例,我之前专门写过一篇详细文章,感兴趣的可以翻看历史推送。
19 个定制技能(skill)
不是"问一句答一句",而是把常用操作封装成固定流程。
一条原则:每个Skill只做一件事,做透。不搞万能技能。
技能怎么长出来的:先用,发现重复操作就抽象成技能,不是预先规划的。
首页即控制台
打开知识库第一眼:
全部从文件元数据自动生成,零手动维护。
理念:好的系统不需要你去"管理"它,它自己会告诉你该关注什么。
我的工具组合
知识库本体:Obsidian + 3 个插件
| Templater | |
| Dataview | |
| Git |
Obsidian 的关键优势:纯本地 Markdown 文件,AI 能直接读写。 换成 Notion 之类的在线工具,AI 操作文件的门槛会高很多。
AI 引擎:终端 Agent
让 AI 直接操作知识库,需要的是终端 Agent——在命令行里跑,能读写文件、执行脚本:
| Claude Code | |
| Codex CLI | |
| opencode | |
| Hermes |
选哪个不重要,关键能力是:能直接读写你的本地文件。 能读能写,AI 才能参与收集、分类、编译的全流程。
同步方案
安全绳:Git 版本控制
知识库还有一个看不见但离不了的基础设施——Git 版本控制。
为什么要给笔记加版本控制?
git diff | ||
git revert |
特别是让 AI 批量处理几十个文件时,版本控制就是安全绳——出了问题一键回到操作前的状态,心里有底才敢放手让 AI 干活。
运营数据
97.5% 活跃率说明一件事:搭对了体系,知识库不会变成数字垃圾场。
三个建议
| 先跑起来再优化 | ||
| AI搬砖,人拍板 | ||
| 定期回头看看 |
工具是次要的,方法才是核心。三级管线、数字编号、知识编译,换个工具一样适用。
AI 的加入让"加工厂"模式成为可能——以前靠人力做不到每篇都加工、编译、审视。现在有了AI一切都可以了。(关注公众号,回复:obsidian获取知识库仓库模板)
本文由「溳与云」原创,整理自个人思考笔记。转载请注明出处。
