 夜雨聆风
夜雨聆风导读: 当你轻点"上传"按钮,一份平平无奇的药品说明书便开启了它的"数字化变形记"。从人类可读的 PDF 文档,到 AI 能"读懂"的向量数据,这背后藏着一整套精密的技术逻辑。本文将用最通俗的语言,拆解这份说明书如何一步步被拆解、转化,最终成为 AI 问答的"知识基石"。
一、引言:一次上传,一场"知识拆解工程"
想象一下:你手里有一份 10 页的《奥美拉唑肠溶胶囊说明书》,对人来说,这是一份完整的用药指南;但对 AI 而言,它只是一串无意义的字符,必须被"拆解开、标上签、存进库",才能在你问"这个药怎么吃"时,精准找到"用法用量"那一段。
这个过程,就像把一本厚书拆成单页、给每页贴分类标签、再放进智能书架——而我们今天,就要钻进这个"智能书架"的后台,看看它到底是怎么工作的。
二、第一关:文件校验与去重——给文件做"门卫安检"
上传的第一步,不是解析内容,而是先"拦着"不合格的文件,杜绝重复的文件,就像图书馆入口的安检员,只放"合规且全新"的书籍进门。
2.1 先查"身份":类型和大小要合规

系统会先检查文件是不是"自己人"(支持的格式),有没有"超重"(大小超限):
# 代码片段 1:严格的入场安检(第319-327行)if suffix notin SUPPORTED_UPLOAD_EXTENSIONS:raise HTTPException(status_code=415, detail="暂不支持该文件类型")iflen(content) > MAX_UPLOAD_BYTES:raise HTTPException(status_code=413, detail="文件超过10MB限制")💡 通俗理解: 只允许 PDF/TXT/MD/DOCX 格式的文件进门,且文件大小不能超过 10MB(差不多相当于 5000 页纯文本),太大的"行李"一律不收。
2.2 再查"指纹":避免重复入库

同一篇说明书可能被命名为"奥美拉唑.pdf""奥美拉唑肠溶胶囊.pdf",但内容完全一样——总不能存十份一样的吧?系统会给文件生成唯一"指纹"(MD5 哈希值),查一查是不是已经存过了:
# 代码片段 2:给文件生成唯一"指纹"(第329行)incoming_doc_id = _content_md5(content)# 检查是否已存在相同指纹(第335-353行)duplicate_chunks = [chunk for chunk in existing_chunks if chunk.doc_id == incoming_doc_id]if duplicate_chunks:return UploadResponse(action="skipped", message="相同文件内容已入库,本次上传已跳过")💡 通俗理解: 就像给每个文件办一张"身份证",身份证号(MD5 值)一样,就说明是同一个人,直接"免登记",省空间、省时间。
三、第二关:文档解析与切割——给说明书做"外科手术"
通过安检的文件,接下来要被"拆解开"—不是乱拆,而是按 "章节分大块,大块分小块" 的策略,既保证结构清晰,又保证 AI 能"啃得动"。
3.1 第一刀:按章节拆(先分"大骨架")

系统会先识别说明书里的【药品名称】【成份】【适应症】等章节标记,把文档按章节拆成一个个"大模块":
# 代码片段 3:识别【章节名】标记(第572-588行)def_extract_upload_sections(text: str): matches = list(re.finditer(r"【([^】]{1,40})】", text))# 提取每个【】之间的内容作为章节名# 将两个章节之间的文本归为该章节的内容举个例子:
("药品名称", "奥美拉唑肠溶胶囊") | |
("成份", "本品主要成份为奥美拉唑") | |
("适应症", "用于胃溃疡、十二指肠溃疡") | |
("用法用量", "口服,成人一次1-2片") |
💡 通俗理解: 就像把一本书按"前言、目录、正文、附录"拆成几大部分,先分清"哪部分是讲什么的"。
3.2 第二刀:按窗口切片(再分"小肉块")

每个章节的内容可能很长,AI 一次"看不完",所以要切成更小的片段,还得留"重叠区",避免关键信息在"切口处"丢失:
# 代码片段 4:按900字符窗口切片,重叠120字符(第551-569行)def_split_upload_text(text: str, chunk_size=900, chunk_overlap=120):while start < len(text): end = min(len(text), start + chunk_size)# 尝试在句号、分号处截断,保持语义完整 cut = max(window.rfind("。"), window.rfind(";")) start = max(0, end - chunk_overlap) # 设置重叠💡 通俗理解: 就像切香肠,每段切 900 字符长,但两段之间重叠 120 字符——比如第一段最后 120 字符是"也可用于十二指肠溃疡",第二段开头也包含这 120 字符,避免"切到一半,语义断了"。
实际效果:
Chunk 1: "...用于治疗胃溃疡。也可用于十二指肠溃疡..." ↑___________900字符___________↑ ↑__重叠120字符__↑Chunk 2: "...也可用于十二指肠溃疡。不良反应包括..."3.3 给每个小块发"身份证":层级化 ID
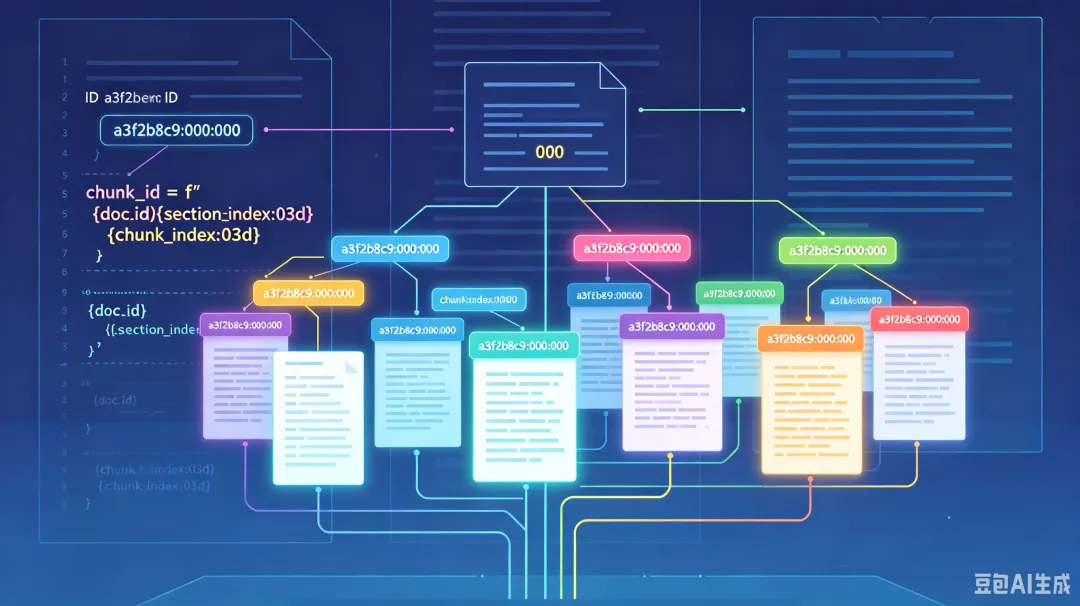
拆好的每个小片段,都会得到一个唯一的 ID,从 ID 就能看出它"属于哪个文档、哪个章节、第几块":
# 代码片段 5:每个chunk获得唯一身份证(第499行)chunk_id = f"{doc_id}:{section_index:03d}:{chunk_index:03d}"# 示例:a3f2b8c9:000:000 表示文档a3f2b8c9的第0章第0块💡 通俗理解: 就像快递单号——"SF123456:01:02",一看就知道是顺丰 123456 这个包裹里,第 1 个箱子的第 2 件物品,管理起来一目了然。
四、第三关:三重持久化——把拆解后的内容"存好"
拆完的片段不能丢,系统会把数据存到三个地方,各司其职,既保证"能溯源",又保证"能复用"。
4.1 存原始文件:留"底档"

先把上传的 PDF 原文件存起来,作为"原始凭证",未来想重新解析、人工核查都能用:
# 代码片段 6:保存PDF原文件(第361行)saved_path = _save_upload_bytes(original_name, content)# 路径:data/uploads/奥美拉唑肠溶胶囊.pdf💡 通俗理解: 就像你把纸质文件扫描后,既存了电子版,也留着纸质版,不怕电子版出问题。
4.2 存独立 JSONL:给单文档建"个人档案"

每个文档的所有小片段,会单独存成一个 JSONL 文件,方便后续给这个文档单独建索引、删改:
# 代码片段 7:每个文档有自己的JSONL文件(第379-381行)upload_jsonl = UPLOAD_JSONL_DIR / f"{document.doc_id}.jsonl"write_jsonl(chunks, upload_jsonl)# 路径:data/processed/uploads/a3f2b8c9.jsonl文件内容示例:
{"chunk_id":"a3f2b8c9:000:000","text":"【药品名称】奥美拉唑...","section":"药品名称",...}{"chunk_id":"a3f2b8c9:000:001","text":"【适应症】用于胃溃疡...","section":"适应症",...}💡 通俗理解: 就像每个人的个人档案袋,只装自己的资料,想查谁的、改谁的,直接拿对应的档案袋就行。
4.3 存 Master JSONL:建"全局花名册"
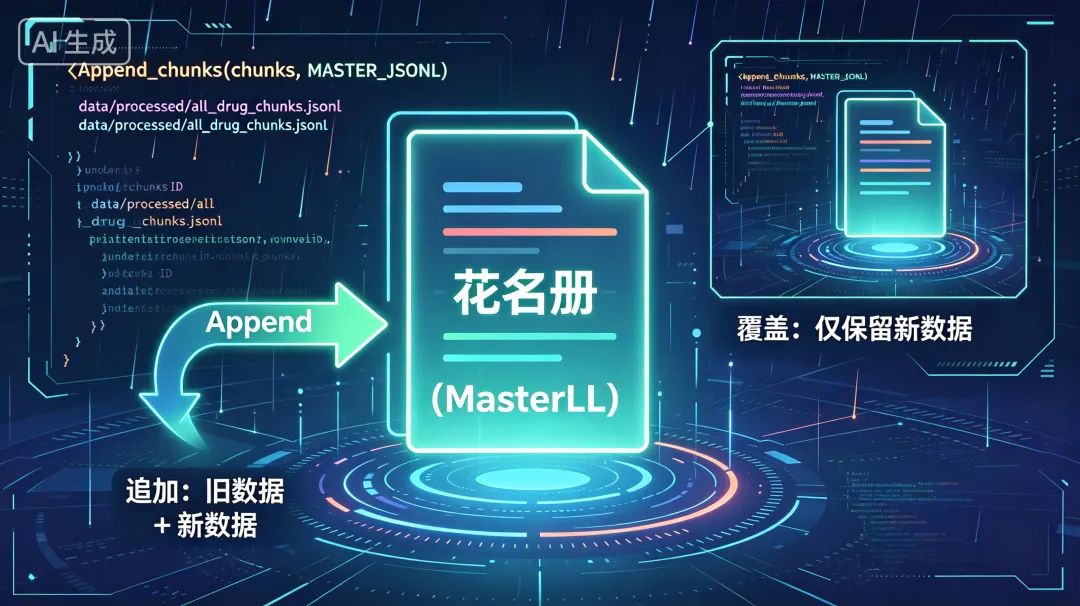
所有文档的小片段,都会追加到一个全局的 JSONL 文件里,相当于"全公司的员工花名册":
# 代码片段 8:追加到全局文件(第383行)_append_chunks(chunks, MASTER_JSONL)# 路径:data/processed/all_drug_chunks.jsonl💡 关键: 这里用**"追加"而不是"覆盖"**!如果覆盖,每次上传新文件都会清空旧数据,系统永远只认识最后一个药;而追加就像花名册加新人,旧人还在,新人也来。下面是一个直观对比:
五、第四关:向量化与索引构建——给 AI"装上懂行的脑子"
拆好、存好的文字,AI 还"看不懂",得把文字变成"数字指纹"(向量),再存进向量数据库,AI 才能快速找到"语义相似"的内容。
5.1 第一步:把文字变成"数字指纹"(Embedding)

Embedding 模型会把每一段文字,转换成一串 512 个数字组成的向量——语义越像,数字指纹越接近:
# 代码片段 9:创建Embedding模型(第47-53行)embeddings = build_embeddings( provider=embedding_provider, # 如 "dashscope" 或 "hash" model=embedding_model, dimensions=512, # 每个向量512维)# 提取所有chunk的文本(第57行)texts = [chunk.text for chunk in chunks]# 转换为向量并存入Chroma(第73行)vector_store.add_texts(texts=texts, metadatas=metadatas, ids=ids)💡 通俗理解: 就像把每句话变成一幅画,Embedding 模型把这幅画压缩成 512 个"颜色值"—"奥美拉唑治胃溃疡"和"奥美拉唑治十二指肠溃疡"的画长得像,颜色值也几乎一样,AI 一眼就能认出来。
向量相似度示例:
"奥美拉唑用于治疗胃溃疡" → [0.23, -0.45, 0.78, ..., 0.12] (512维)"奥美拉唑主治十二指肠溃疡" → [0.25, -0.43, 0.76, ..., 0.14] (512维)# 两个向量非常接近 → 余弦相似度 ≈ 0.97# 因为语义极其相似!5.2 第二步:把指纹存进"智能书架"(Chroma 向量库)

向量不会乱存,会放进 Chroma 向量数据库——这个数据库就像带"智能导航"的书架,能快速找到"指纹相似"的内容:
# 代码片段 10:初始化Chroma(第63-69行)Path(persist_dir).mkdir(parents=True, exist_ok=True)vector_store = Chroma( collection_name="drug_chunks", persist_directory="data/chroma", embedding_function=embeddings,)Chroma 的存储结构:
data/chroma/├── chroma.sqlite3 # SQLite数据库,存储元数据和ID映射├── data_level0.bin # HNSW向量索引(核心检索结构)├── header.bin # 索引头信息├── length.bin # 向量数量└── link_lists.bin # HNSW图结构链接💡 通俗理解: Chroma 里的 HNSW 算法,就像在多维空间里给向量建了"高速公路网"—要找相似向量,不用挨个查(慢),走"高速"能直接定位(快),检索速度从"数小时"变成"毫秒级"。
六、第五关:目录聚合——给 AI 做"快速检索目录"
如果用户问"系统里有哪些降压药",总不能挨个查 5000 个小片段吧?系统会建一个"精简目录",把关键信息汇总,提速 200 倍!
6.1 构建 Catalog:汇总关键元数据
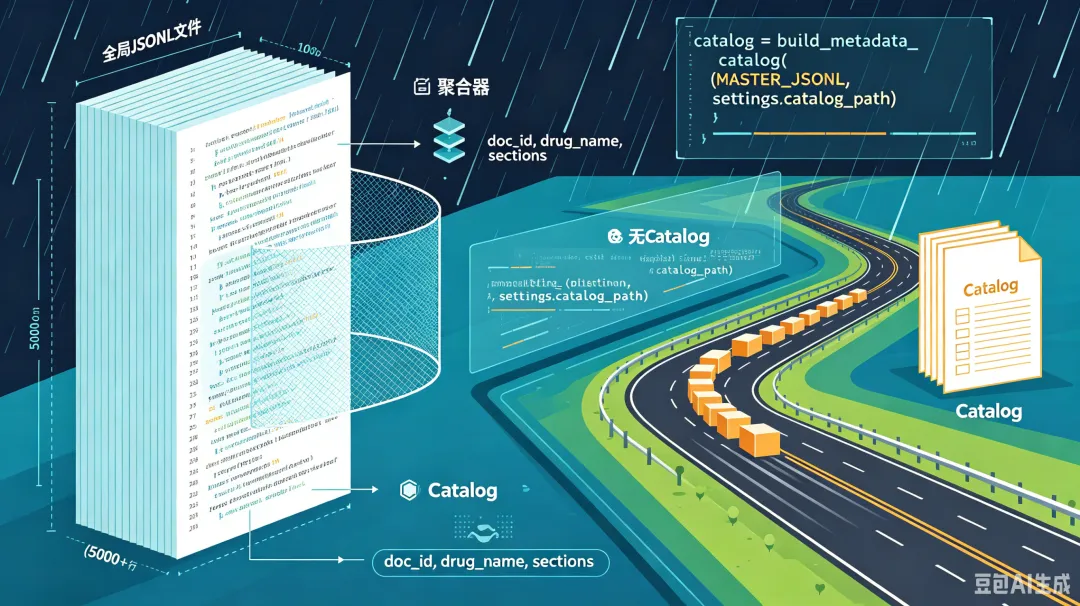
系统会从全局 JSONL 里提取每个文档的核心信息,生成一个极简的目录文件:
# 代码片段 11:重建catalog(第413行)catalog = build_metadata_catalog(MASTER_JSONL, settings.catalog_path)核心逻辑就是"去繁就简":
# 读取all_drug_chunks.jsonl(可能5000+行)for chunk in read_jsonl(jsonl_path): grouped[chunk.doc_id].append(chunk)# 按doc_id聚合,每个文档只保留一条元数据记录drugs.append({"doc_id": doc_id,"drug_name": first.drug_name,"generic_name": first.generic_name,"sections": ["药品名称", "适应症", ...], # 所有章节名"chunk_count": 34, # 该文档有多少个chunks})6.2 Catalog 的威力:200 倍提速!
| 2 秒 | 10 毫秒 | |
| 200 倍 |
💡 通俗理解: 就像查字典,没有目录要翻整本,有目录直接翻到"J"开头,快到飞起——这就是 "用空间换时间",多存一个 10KB 的小文件,换 200 倍的速度提升。
七、第六关:缓存清理——给系统"刷新内存"
系统会把常用的东西(比如向量库连接、Catalog 数据)存在内存里(LRU 缓存),新数据入库后,旧缓存就"过时了",必须清理:
# 代码片段 12:清理LRU缓存(第415-416行)get_runtime.cache_clear() # 清除向量库连接缓存get_catalog.cache_clear() # 清除catalog缓存💡 通俗理解: 就像浏览器缓存,网站更新后你要按 Ctrl+F5 刷新,才能看到最新内容——不清理缓存,用户查到的还是"旧数据",比如明明传了新的降压药,却显示"没有"。
八、总结:一次上传的完整"旅程图"
把整个流程串起来,就是这样一条清晰的路径:
用户上传PDF ↓┌─────────────────────────────────────┐│ 【校验层】 ││ 类型检查(PDF/TXT/MD/DOCX) ││ + MD5哈希去重 │└─────────────────────────────────────┘ ↓┌─────────────────────────────────────┐│ 【解析层】 ││ 章节识别(正则匹配【】标记) ││ → 窗口切片(900字符+120重叠) ││ → 生成层级化Chunk ID │└─────────────────────────────────────┘ ↓┌─────────────────────────────────────┐│ 【持久化层】(三重存储) ││ ├─ data/uploads/原始PDF ││ ├─ data/processed/uploads/{doc_id}.jsonl ││ └─ data/processed/all_drug_chunks.jsonl │└─────────────────────────────────────┘ ↓┌─────────────────────────────────────┐│ 【索引层】 ││ ├─ Chroma向量数据库(data/chroma/) ││ └─ 摘要索引(drug_summaries集合) │└─────────────────────────────────────┘ ↓┌─────────────────────────────────────┐│ 【目录层】 ││ data/processed/drug_catalog.json │└─────────────────────────────────────┘ ↓┌─────────────────────────────────────┐│ 【缓存层】 ││ 清理LRU缓存 │└─────────────────────────────────────┘ ↓返回成功响应 ✅九、技术亮点:藏在细节里的"巧思"
| 职责分离 | |||
| 层级化 ID | |||
| 追加模式 | |||
| 空间换时间 | |||
| 语义保护 |
十、结语:这是 RAG 系统的"半壁江山"
药品说明书的上传流程,看似只是"存文件",实则是 RAG(检索增强生成)系统的核心——把非结构化的 PDF,变成 AI 能快速检索的结构化知识。
当你问"奥美拉唑怎么吃"时,AI 能毫秒级找到答案,背后就是这套流程在"打底":把说明书拆成小块、变成向量、存进智能库、快速检索。理解了这个过程,你就懂了 RAG 系统的一半逻辑。
📌 下期预告:《从向量检索到智能问答:RAG 系统的检索链路深度解析》
💬 欢迎留言讨论:你认为还有哪些优化空间?表格类内容如何处理?我们下期见!
