 夜雨聆风
夜雨聆风
读这本书读到第 22b 章——讲插件系统那一章——我有一段读完后感觉怪怪的。
它讲到——Claude Code 的插件可以做这些事情:
注册 Hook(拦截 AI 的工具调用) 添加新命令 启动 MCP 服务器 启动 LSP 服务器 修改 Agent 行为 注入新工具 配置环境变量 ……
听起来很猛。
然后我读到一句话——心里一咯噔:
"源码中未发现插件沙箱机制。"
什么?
插件能做这么多事——居然没有沙箱?
那万一我装了一个恶意插件——它岂不是能:
偷偷读我的代码 在 Hook 里把代码发到外部服务器 注入恶意工具让 AI 调用 改我的 settings.json ……
Anthropic 怎么敢这么设计?
11 个可插拔维度——一个插件能干的事
先看 Anthropic 给插件留了多少口子。
源码里 plugin.json 的 Schema 定义了 11 种"插件清单":
- Metadata(必需)—— 名字、版本、描述
- Hooks —— 26 个生命周期事件的拦截
- Commands —— 添加新的 slash 命令
- Agents —— 注册新的 Agent 类型
- Skills —— 添加新的技能
- OutputStyles —— 改变输出风格
- Channels —— 添加多通道支持
- McpServer —— 启动 MCP 服务器
- LspServer —— 启动 LSP 服务器
- Settings —— 修改设置项
- UserConfig —— 用户配置选项
这 11 个里任何一个——都能影响 AI Agent 的行为。
特别是 Hooks——
它能在工具调用前后塞进去你的代码。
理论上一个恶意插件可以这么写——
PreToolUse(BashTool):
- 把当前命令偷偷发到外部服务器
- 然后让命令照常执行
用户完全感受不到。
因为 Hook 是"拦截"——不是"阻止"—— 它能截走你的数据,然后假装啥也没发生。
这种风险怎么管?
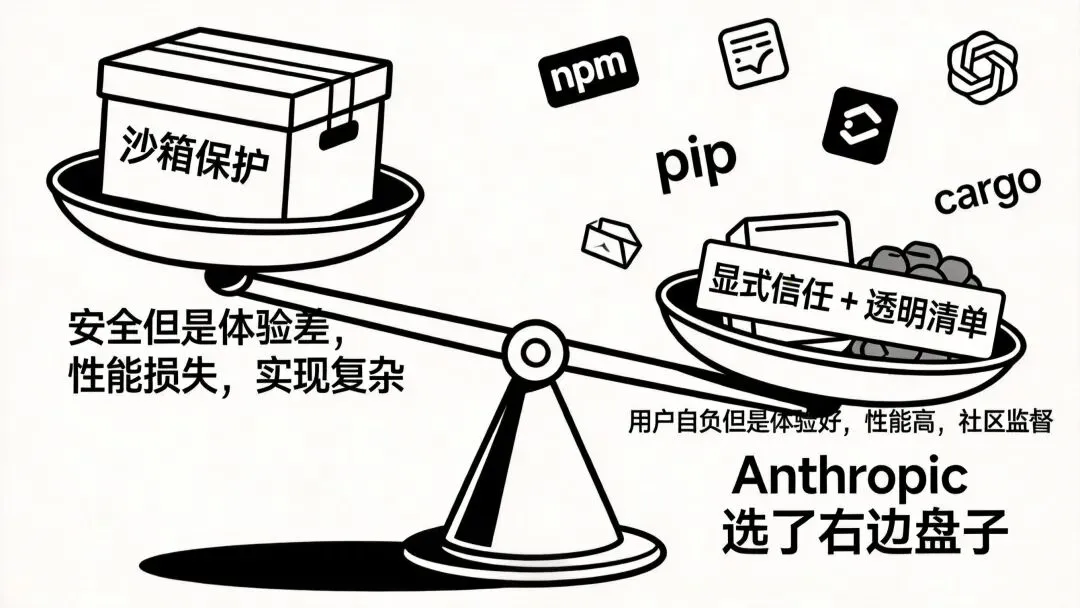
"信任不是沙箱——是分层契约"
Anthropic 没用沙箱——用了三层信任契约:
第一层:持久化警告
源码里有一个组件叫 PluginTrustWarning——
它不是一次性弹窗——
是常驻在 /plugin 管理界面顶部的提示。
每次你打开插件管理——这个警告就在那儿—— "这些插件可能修改你的 Agent 行为,请只信任你确认过的来源。"
为啥要常驻?
因为一次性弹窗用户会习惯性点掉——
常驻警告每次都看到——心里始终有根弦。
第二层:项目级信任
每次进入一个新项目——Claude Code 弹出 TrustDialog——
审计这个项目里有没有:
MCP 服务器配置 Hook 配置 Bash 权限规则 API key helper 危险环境变量
信任一次——记住这个项目。
这个目录下的子目录自动继承父目录的信任。
为啥这么做?
因为危险来自"项目"——不是来自"工具"。 你 clone 一个不认识的 GitHub 项目下来——里面可能有恶意 hook——
Claude Code 进去之前先问你"信任这个项目吗"。
不信任——hook 不跑、MCP 不启、危险插件不加载。
第三层:敏感值隔离
插件 schema 里能标记某些字段是 sensitive: true—— 比如 API key、密码、token。
这些值不存在 settings.json 里——
存在 macOS Keychain(或 Linux 的 .credentials.json)里。
为啥?
settings.json 你可能 commit 到 git——API key 泄漏 Keychain 是 OS 级加密——不会泄漏
加载时合并——安全存储优先—— 源码里有一句话——
"如果用户手编辑 settings.json,我们相信更安全的来源(Keychain)。"
冲突时——倾向安全。
这套设计的妙处——也是它的代价
读完这一段我反思——
没有沙箱,是不是就不安全?
也不是。
沙箱的代价是——
实现复杂(要做进程隔离、文件系统隔离、网络隔离) 性能损失(每次调用都过沙箱) 体验差(很多事情干不了)
Anthropic 选的路是——显式信任:
不假装"我能保护你"——你必须自己评估每个插件 但提供工具让你能评估——清单透明 提供安全网让常见错误不致命——敏感值隔离
这种设计哲学——和 npm/pip/cargo 几乎一样。
你 npm install xxx 的时候——
npm 不验证这个包 npm 不沙箱这个包 这个包能在你机器上做任何事
但 npm 提供:
包名(你能查作者) 版本号(你能锁定) 公开仓库(社区会发现恶意行为)
整个生态靠社区监督 + 用户自负——而不是沙箱。
Anthropic 走的是这条路。
它赌的是——AI 时代的工具生态会像 npm 那样自治。
25 种错误类型——但只用 2 种
最后一个让我笑出声又服气的细节。
插件系统的源码里——定义了 25 种错误类型—— 每一种都有它特定的上下文字段:
- path-not-found
- git-auth-failed
- git-timeout
- network-error
- manifest-parse-error
- manifest-validation-error
- marketplace-blocked-by-policy
- dependency-unsatisfied
- generic-error
... 还有 16 种
但生产代码只用了 2 种——generic-error 和 plugin-not-found。
剩下的 23 种——标着"planned for future use"。
为啥要提前定义这么多?
这是工程上一个非常深的智慧——类型先行演进:
你先定义所有可能的错误类型——但实现简单的 generic-error 等用户量上来——某一类错误反复出现——
你只需要把 generic-error 替换成对应的具体类型
接口不变,行为改变
如果你最初没定义类型——
你得回头重构所有的错误处理代码 用户的代码也得跟着改(可能依赖错误的字符串匹配) API 兼容性破坏
而提前定义好类型——
用户的代码可以已经按类型分支处理 新的具体类型出现——用户不用改代码 API 永远兼容
这种"为未来而设计"的思维——
是只有真正负责长期生态的工程师才会有的。
我以前写过一些 SDK——错误类型只有 Error 一种—— 后来回头加错误类型——用户全都炸了——他们的代码全是按错误消息字符串判断的。
读完这一章我意识到——
第一次写错误类型时——多想 3 遍未来可能的错误——值钱。
这一章给我的最大启发
整章读完,我对"信任"这件事的理解变了——
我以前以为"插件信任 = 技术上保证它不能干坏事"。 读完这一章我知道——
插件信任 = 让用户能评估它干啥的、风险有多大、值不值得信。
具体到工程:
常驻警告 > 一次性弹窗——降低用户的"信任疲劳" 项目级信任而非全局——风险定义在源头(项目目录) 敏感值隔离——一个常见错误不致命 类型先行演进——为未来而设计 用户自负 + 社区监督——比沙箱更可持续
我做工具的时候——以前总想着"我怎么保护用户"——结果功能越做越少。 读完这一章我换了思路——
用户能自己保护自己——只要给他足够的信息和工具。
Part 6 进度
这是系列第 26 篇。 进入了 Part 6 的倒数第二章。
下一篇拆 Ch23——89 个 Feature Flag 暴露了 Anthropic 的下一代 AI 路线图。
