 夜雨聆风
夜雨聆风在 AI 技术爆发的当下,语音转文字(ASR)早已不再是陌生的技术。
从会议记录到播客字幕,从在线教育到社交媒体,几乎每一个与语音相关的场景都离不开转录技术的支持。
然而,当场景从单人演讲转向多人对话时,问题就变得棘手起来。
• 一场激烈的头脑风暴会议,几个人同时发言,你一言我一语,语速飞快还经常重叠; • 一段精彩的播客访谈,主持人和嘉宾来回切换,突然打断插话是家常便饭; • 一部精彩的电视剧,多幕场景切换,同一个人的声音在不同环境下差异巨大……
面对这些复杂情况,传统的转录系统要么混淆说话人身份,要么丢失重叠部分的内容,要么产生大量错误。
不过,就在这周,这一领域也迎来了一个重大突破:Soul App 联合西北工业大学 ASLP@NPU 团队及 Moonstep AI,正式开源了端到端多人对话转录模型 SoulX-Transcriber!

SoulX-Transcriber 是什么?
SoulX-Transcriber 是一款专门为长音频、多说话人场景设计的语音理解模型。
与传统依赖级联流水线的系统不同,它采用了统一的端到端架构,能够直接从多人对话音频中生成包含 时间戳、说话人身份、转录文本 的完整结构化结果。
这个项目由三方强强联合打造:
• Soul AI Lab:Soul App的 AI 技术团队,在语音技术领域有着深厚积累,此前还开源过SoulX-Podcast播客生成模型• ASLP@NPU:西北工业大学音频语音与语言处理研究组,国内顶尖的语音技术研究团队• Moonstep AI:专注于AI音频技术的创新公司
从技术路线来看,SoulX-Transcriber 摒弃了传统的 "说话人分割+语音识别" 分开处理的方式,而是将这两个任务融合在一个统一的大语言模型框架中。
这种端到端的设计让模型能够更自然地处理多人对话中常见的重叠、快速切换、同性别混淆等棘手问题。
三大核心亮点
1、性能登顶公开基准测试
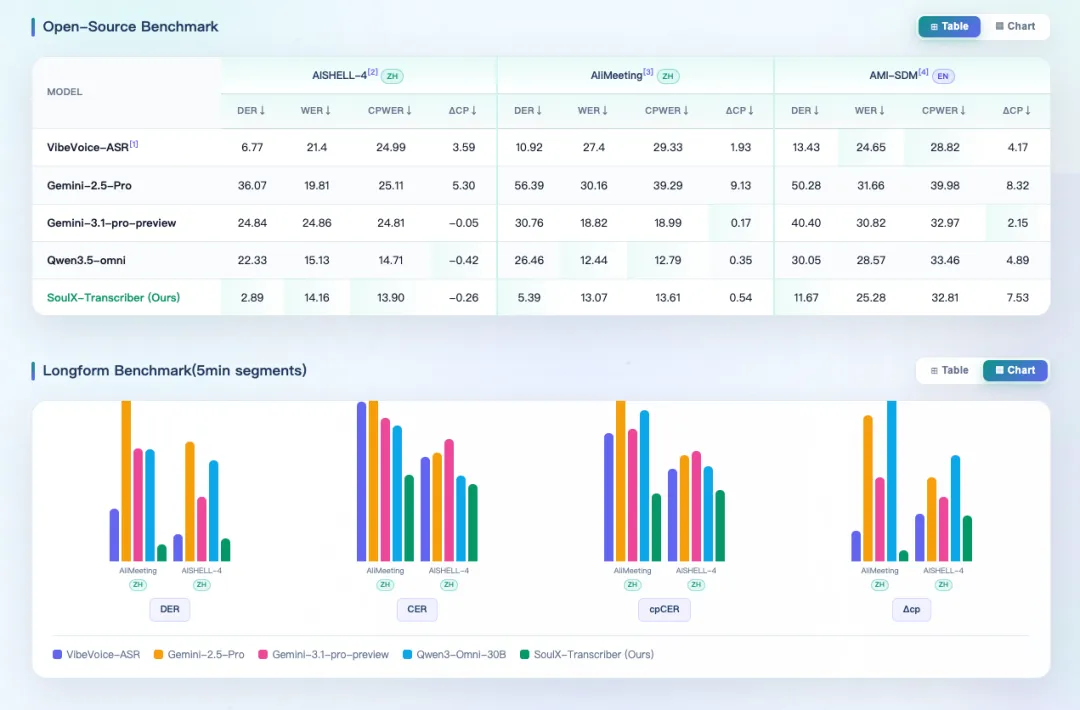
在多人对话转录领域,有几个公认的权威基准测试数据集,比如 AISHELL-4、AliMeeting等。
SoulX-Transcriber在这些测试中都取得了碾压式的领先表现。
让我们看看具体数据(所有指标都是越低越好):
甚至连 Gemini 3.1 Pro、Qwen3.5-Omni 这样的闭源大模型,在这些指标上也被 SoulX-Transcriber 大幅超越!
更令人印象深刻的是,在内部多领域测试(社交对话、影视剧、播客)中,SoulX-Transcriber 同样表现抢眼,在社交对话场景下DER甚至低至 1.32%。
2、说话人感知的多阶段训练
SoulX-Transcriber 的优秀表现不是偶然的,背后是创新的训练策略。
团队采用了 说话人感知的多任务持续预训练 + 有监督微调 的两阶段训练方法。
这种方法的好处是:
• 显著增强了模型对说话人特征的表示能力 • 大幅提升了对多人对话场景的鲁棒性 • 有效缓解了同性别说话人混淆、语音重叠、边界划分错误等常见问题
在传统系统中,这些问题往往需要复杂的后处理算法来解决,而 SoulX-Transcriber 通过端到端训练就能自然地处理这些情况。
3、更自然的对话生成与数据增强
为了提升模型在真实场景下的泛化能力,团队还提出了一套 基于说话人特征驱动的音频匹配流水线。
通过这种方式,团队能够生成海量高质量的多人对话训练数据,让模型在各种真实场景下都能有出色表现。
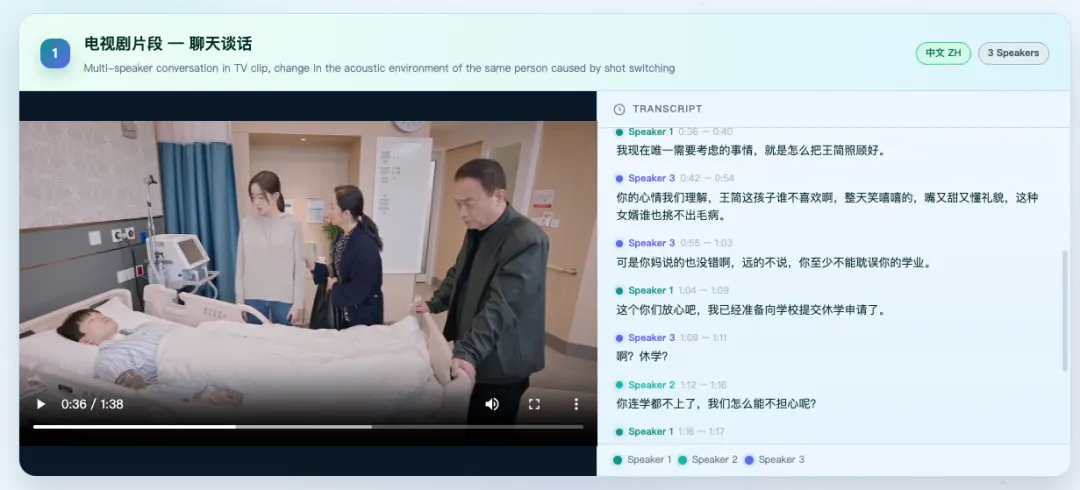
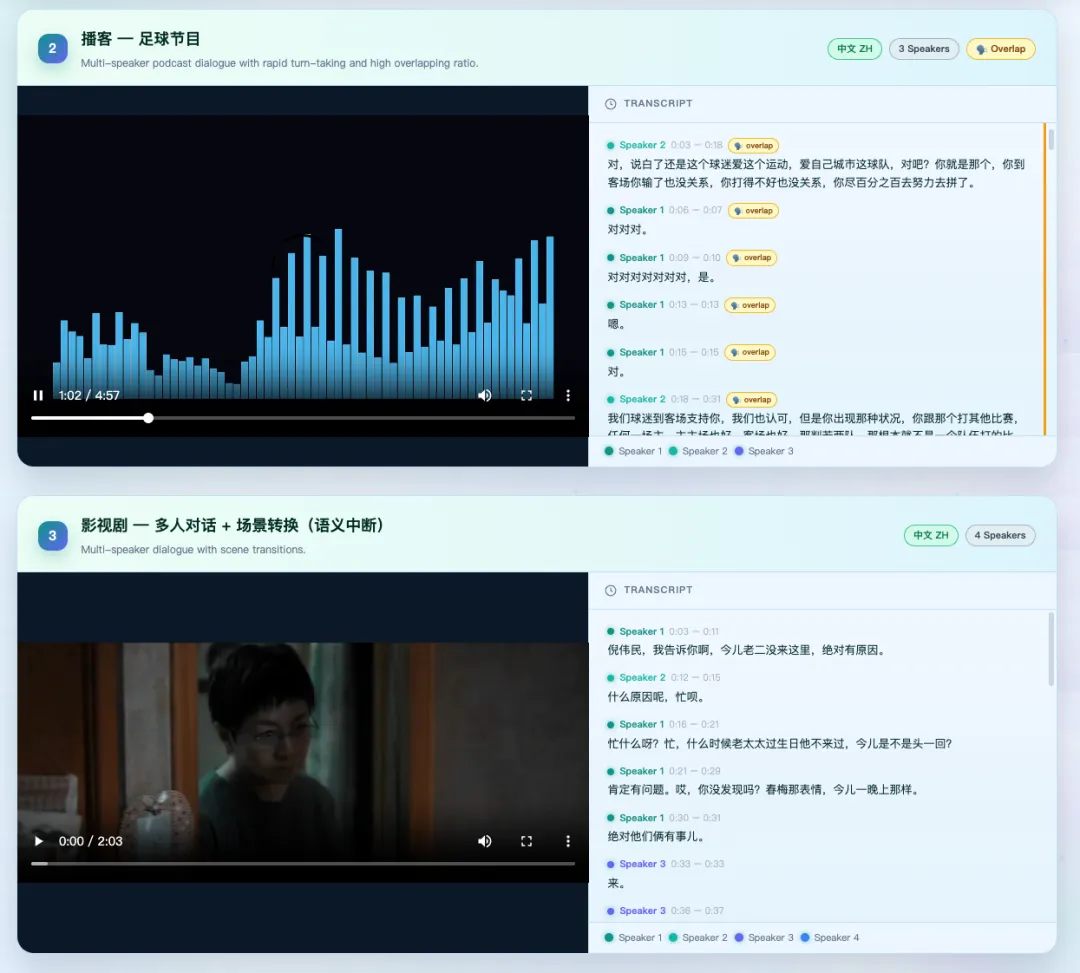
官方示例场景:
快速上手
首先,你需要克隆项目代码并创建Python环境:
git clone https://github.com/Soul-AILab/SoulX-Transcriber.git
cd SoulX-Transcriber
# 创建conda环境
conda create -n soulx_transcriber python=3.12 -y
conda activate soulx_transcriber
# 安装MS-Swift和依赖
pip install ms-swift预训练模型权重已经在 Hugging Face 和 ModelScope 上开放下载:
• Hugging Face:https://huggingface.co/Soul-AILab/SoulX-Transcriber • ModelScope:https://modelscope.cn/models/Soul-AILab/SoulX-Transcriber
使用 vLLM-Omni 进行推理,安装步骤如下:
cd your_env_path/
# 安装uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# 创建新的uv环境(使用阿里云镜像)
uv venv vllm_omni --python 3.12 --seed --index-url https://mirrors.aliyun.com/pypi/simple/
# 激活uv环境
source vllm_omni/bin/activate
# 安装vLLM
uv pip install vllm --torch-backend=auto --index-url https://mirrors.aliyun.com/pypi/simple/
# 安装vllm-omni
uv pip install vllm-omni --index-url https://mirrors.aliyun.com/pypi/simple/
# 安装Gradio(可选,用于演示界面)
uv pip install 'vllm-omni[demo]' --index-url https://mirrors.aliyun.com/pypi/simple/
# 如果遇到"Undefined symbol"错误,可以从源码构建
git clone https://github.com/vllm-project/vllm-omni.git
cd vllm-omni
uv pip install -e . --index-url https://mirrors.aliyun.com/pypi/simple/下载模型权重后,运行推理脚本:
source your_env_path/vllm_omni/bin/activate
bash ./inference.sh就这么简单!你可以用自己的多人对话音频来测试这个强大的模型。
应用场景
• 会议记录:自动生成带说话人标注的会议纪要,谁在什么时候说了什么一目了然 • 播客字幕:为播客节目自动生成精准的字幕,还能区分不同嘉宾 • 影视剧台词提取:自动提取电视剧、电影的台词,区分不同角色 • 在线教育:记录课堂讨论,生成结构化的学习资料 • 社交媒体内容分析:分析语音直播、语音聊天室的内容 • 法律取证:精准转录多人对话的录音材料,作为证据使用 • 医疗问诊记录:记录医患对话,生成结构化的病历
任何涉及多人语音对话的场景,SoulX-Transcriber都能大显身手!
写在最后
SoulX-Transcriber 的出现,标志着多人对话转录技术进入了一个新的阶段。
它用端到端的架构设计,解决了传统级联系统的诸多痛点,在公开基准测试中取得了碾压式的领先表现。
快去试试这个强大的模型吧!相信它会给你带来惊喜!
相关链接:
• 项目页面:https://soul-ailab.github.io/soulx-transcriber/ • GitHub:https://github.com/Soul-AILab/SoulX-Transcriber

如果本文对您有帮助,也请帮忙点个 赞👍 + 在看 哈!❤️

