 夜雨聆风
夜雨聆风做数据处理时,最头疼的就是原始数据格式不统一、杂乱无章。其实Excel内置的几个文本函数就能帮你快速搞定清洗工作,把混乱的数据变成规整可用的表格。今天就把这些实用的数据清洗技巧分享给大家。
表姐整理了552页《Office从入门到精通》,私信【教程】即可领取!↑↑↑

一、FIND函数(查找文本位置)
FIND函数用来在一段文本中查找指定字符或字符串出现的位置,返回的是一个数字,表示从第几个字符开始找到目标。这个函数在数据清洗中非常常用,比如你要把"500g/份"中的数字和单位拆分开,首先就得知道"/"出现在第几位,FIND就能帮你精确定位。 实际工作中,当商品规格、型号等混在一起的时候,我们经常需要用FIND先定位分隔符的位置,然后再配合LEFT、MID、RIGHT等函数截取需要的部分。可以说FIND是文本拆解类操作的基础中的基础。 参数方面,第一个参数是要查找的文本(如"/"),第二个参数是在哪个单元格中查找(如A2),第三个参数是从第几位开始找(通常写1表示从头开始找)。
=FIND("/",A2,1)

二、REPLACE函数(按位置替换字符)
REPLACE函数的功能是根据位置来替换字符串中的部分内容,你告诉它从第几个字符开始、替换掉几个字符、换成什么新内容,它就照做不误。这个函数的特点是不关心替换的是什么字,只关心位置,所以特别适合处理固定格式的脱敏操作。 最常见的场景就是手机号脱敏,手机号都是11位且中间4位需要隐藏,用REPLACE从第4位开始替换4个字符为星号,一行公式就能批量搞定成百上千条记录,效率极高。 参数依次为:原文本所在单元格、起始位置(从第几位开始替换)、要替换掉的字符个数、替换成的新文本内容。
=REPLACE(A2,4,4,"****")

三、SUBSTITUTE函数(按内容替换字符)
SUBSTITUTE函数同样是做替换的,但它和REPLACE不同之处在于它是按内容来替换的,你告诉它把哪个旧文字换成什么新文字,它就会在文本中找到所有匹配的内容进行替换。这个函数更直观也更灵活,不需要知道目标文字出现在第几位。 比如公司部门调整后,要把所有员工信息里的"运营部"统一改成"人事部",用SUBSTITUTE一行公式就能批量完成全部替换,不用逐条手动修改,省时又不容易出错。 参数依次为:要处理的文本单元格、被替换的旧文本、替换成的新文本、可选的第几个实例(省略则替换所有匹配项)。
=SUBSTITUTE(A2,"运营","人事")

四、TEXT函数(数值格式转文本)
TEXT函数的作用是把一个数值按照指定的格式转换成文本形式,这在日期格式统一和数据报表展示中非常有用。很多时候系统导出的日期格式五花八门,有的用斜杠分隔,有的用横杠,TEXT可以强制统一输出格式。 举个例子,你的表格里日期列有的是2023/12/13这种格式,但报告要求统一用横杠分隔写成2023-12-13,用TEXT配合格式代码"yyyy-mm-dd"就能一键转换,而且转换后是纯文本不会再变回日期序列号。 参数很简单:第一个是要转换的数值或日期单元格,第二个是用双引号括起来的格式代码(如"yyyy-mm-dd"表示年-月-日)。
=TEXT(A2,"yyyy-mm-dd")

五、计算单元格内的项目个数
这个技巧的核心思路是用总长度减去去掉分隔符后的长度来推算出有多少个项目,原理非常巧妙。具体来说,一个单元格里如果有N个人名,那它们之间一定有N-1个顿号或逗号作为分隔符。 在实际工作中经常遇到这种情况:一个部门对应多个员工姓名,用顿号隔开写在同一个单元格里,领导突然问你每个部门有几个人,手动数肯定不现实。这个公式利用了分隔符数量与项目数量的数学关系,自动算出人数。 公式的逻辑是:LEN(B2)算出原始文本总长度,SUBSTITUTE把所有顿号替换为空后再用LEN算一次长度,两者相减就是顿号的个数,加1就是项目总数。
=LEN(B2)-LEN(SUBSTITUTE(B2、"、"))+1

六、LEFT+FIND组合提取品名
这个组合的目的是从一个包含多种属性信息的商品字段中提取出品名称,关键在于品名总是位于最前面,后面跟着连字符或其他分隔符。所以我们需要先用FIND定位第一个分隔符的位置,然后用LEFT从左边截取到分隔符之前的部分。 电商和库存管理中很常见这种需求,商品信息写成"针织衫-男-L"这样的格式,品名、性别、尺码全挤在一个单元格里。要做数据分析的话必须把它们拆开,提取品名就是第一步,后续才能按品类统计销量。 LEFT函数从左端截取指定长度的文本,FIND找到第一个"-"的位置后减1就是品名的字符数,两者配合精准截取。
=LEFT(A2,FIND("-",A2)-1)

七、MID+FIND组合提取性别
提取完品名之后,接下来要取中间的性别信息,这时候LEFT已经不够用了,需要用到MID函数从中间位置截取。关键是确定从哪里开始取以及取几个字,这同样依赖FIND来定位分隔符的位置。 继续以"针织衫-男-L"为例,性别信息夹在两个"-"之间,所以起点应该是第一个"-"之后一位,长度固定为1个字符(因为性别就是一个字)。MID正好支持从任意位置开始截取指定长度的文本。 MID的第一个参数是源文本,第二个参数是起始位置(用FIND找到第一个"-"的位置加1),第三个参数是截取长度(这里写1表示只取1个字符)。
=MID(A2,FIND("-",A2)+1,1)

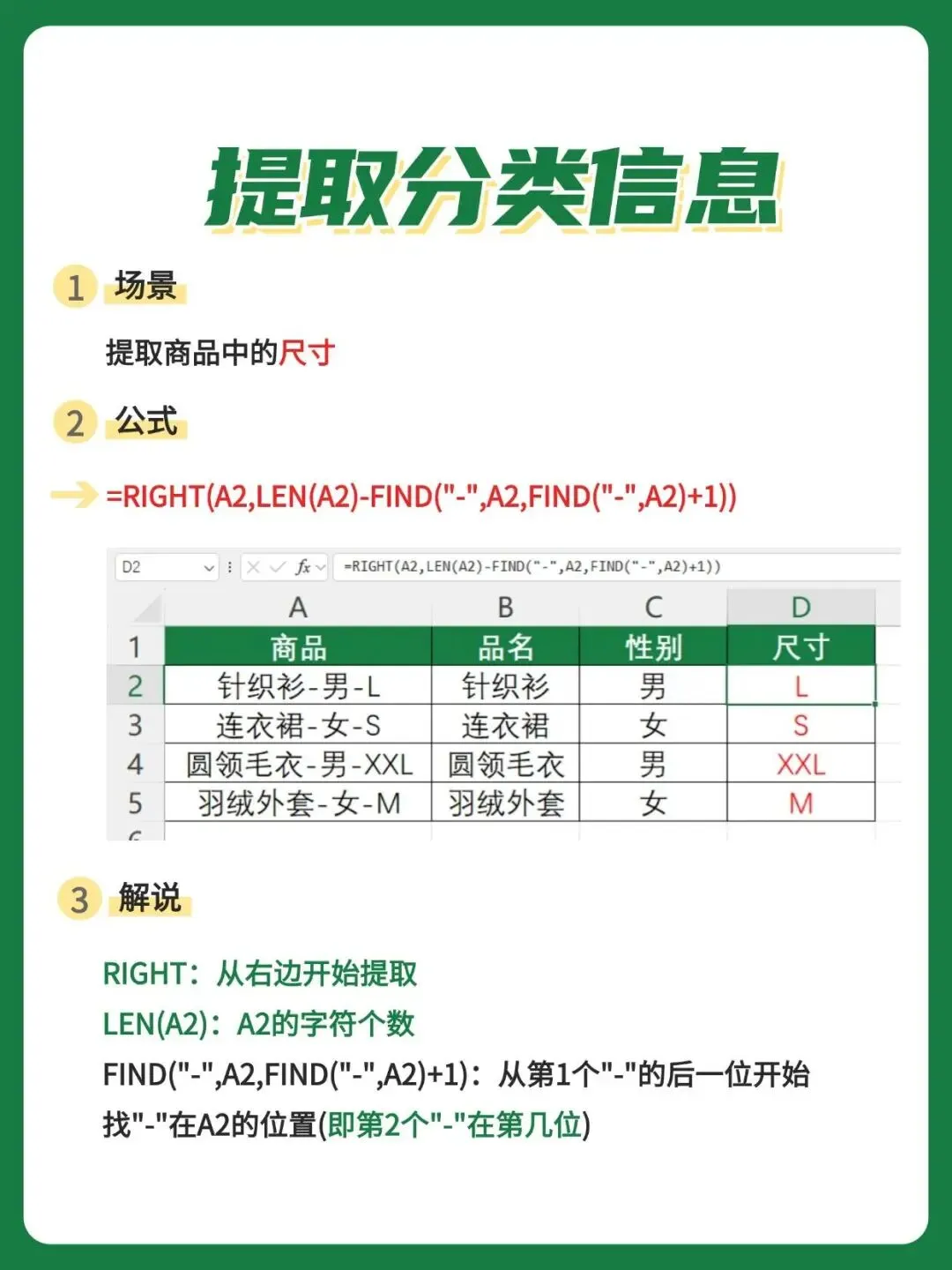
八、RIGHT+LEN+FIND组合提取尺寸
提取最后一个分段信息(这里是尺码)要用到RIGHT函数从右端截取,难点在于你需要知道右边有多少个字符属于尺码部分。方法是先找到第二个"-"的位置,然后用总长度减去这个位置就得到右侧剩余的字符数。 在商品信息拆解的场景中,尺码通常是最后一段,而且长度不固定(可能是L、S也可能是XXL、XXXL),所以不能写死长度。通过找到倒数第二个分隔符的位置来动态计算右侧字符数是最稳妥的做法。 RIGHT从右端往左截取,LEN算出总长度,两个FIND配合定位到第二个"-"的位置,三者结合就能准确取出末尾的尺码信息。
=RIGHT(A2,LEN(A2)-FIND("-",A2,FIND("-",A2)+1))
九、提取地址中的一级行政区(省市自治区)
从完整地址中提取省份或直辖市信息是一个经典难题,因为中国的一级行政区结尾各不相同,有省、市、自治区三种形式。这个公式的巧妙之处在于同时搜索这三个关键字,取最先出现的那个位置,然后用LEFT截取出来。 实际应用场景包括物流发货地址标准化、客户区域统计分析等,原始地址可能写着"广东省广州市吕尚街"或者"重庆市渝中区民族路",需要自动识别出一级归属地是广东省还是重庆市。 公式核心是用FIND同时查找"省""市""区"三个字,MIN取最小的那个位置(即最先出现的),再拼接一个容错用的假关键词确保不会出错,最后用LEFT截取。
=LEFT(A2,MIN(FIND({"省","市","区"},A2&"省市区")))

十、提取地址中的二级行政区(市县区)
提取二级行政区的思路是先把已经提取出的一级区划从地址中去掉,然后在剩下的文本里再找"市""县""区"这些二级关键字。这里用SUBSTITUTE把一级区划替换为空,相当于从地址中删掉了前半段。 为什么不能直接在原始地址上找呢?因为"区"字既可能是一级的"自治区"的一部分,也可能是二级的"渝中区",直接搜会定位错误。所以必须先剔除一级部分再搜索,逻辑上更加严谨。 公式先通过SUBSTITUTE将一级区划替换为空得到剩余地址,然后在这个基础上用MIN+FIND找"市""县""区"中最靠前的位置,最后LEFT截取出二级名称。
=LEFT(SUBSTITUTE(A2,B2,""),MIN(FIND({"市","县","区"},SUBSTITUTE(A2,B2,"")&"市县区")))

十一、提取地址中的三级行政区(街道乡镇)
经过前面两步已经分别拿到了一级和二级区划,那么三级行政区其实就是剩下的部分了。用SUBSTITUTE把一级和二级都替换为空,剩下的自然就是三级地址内容,思路简洁明了。 这个方法的好处是完全不需要再做任何定位和搜索操作,前面两步已经把前面的层级都剥离干净了,最后一步就是收尾工作,把残留的三级信息露出来。 公式只需要一个SUBSTITUTE,把B列的一级区划和C列的二级行政区都替换为空字符串,结果就是最终的三级行政区名称。
=SUBSTITUTE(A2,B2&C2,"")

以上就是Excel数据清洗中常用的11个函数和组合技巧,涵盖了文本查找、替换、格式转换、项目计数、字段拆分和地址解析等典型场景。掌握这些函数,日常工作中遇到的大部分脏数据问题都能轻松应对。
