 夜雨聆风
夜雨聆风过去两年,OCR 工具已经很多了。Surya、Marker、MinerU、PaddleOCR……大家都能跑,也确实解决了不少问题。但一旦你开始碰真实业务里的文档——合同、年报、研报、跨页表格——有些弱点就慢慢暴露出来了。
更关键的是,现在 Agent 时代来了。我们对 AI 的期望,已经从"帮我总结一下这份文档",变成了"帮我读完这批合同,找出风险条款,标出依据,并生成审查意见"。
能看懂一次,和能稳定处理一批,是两回事。
而稳定处理一批的前提,是有一款靠谱的文档解析工具。最近我试了 xParse Skill,感觉这件事扛起来了。
为什么Agent最缺的是文档工具?
Agent 正在从"聊天助手"变成"任务执行者"
以前我们用 AI,就是聊天。问个问题,给个回答,完事。
现在不一样了。我们希望 Agent 能干完整的工作流:
"帮我分析 20 份研报,提取关键财务指标,生成投研摘要。" "帮我把这批合同的违约条款全找出来,对比差异。" "把这份审计报告的资产负债表抽出来,转成结构化数据。"
这些任务有个共同点:它们都要求 Agent 先读懂文档,再执行任务。
读不懂,后面再聪明也白搭。垃圾进,垃圾出。
真实业务中,关键信息分散于各类非结构化文档,Agent 的核心价值在于通过总结、抽取、比对、问答、审核等能力,将这些文档转化为可检索、可决策的结构化知识。
Agent 要真正进入业务场景,第一步不是能调用多少工具,而是能不能可靠理解这些文档。今天要介绍一个最近测试还不错的解析skill-TextIn xParse skill。能力很强,还能免费使用,满足了我的日常需求。
TextIn xParse是什么
一句话:把 PDF、图片、Word 等原始文件,转成 Markdown 和结构化 JSON,让 Agent 真正读懂文档内容。
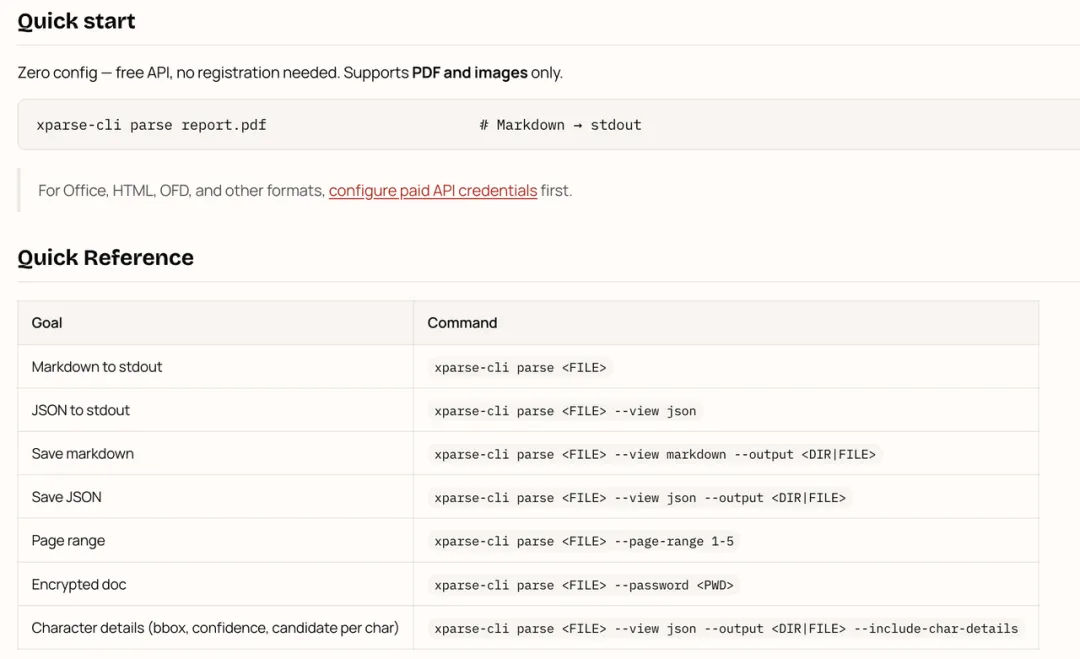
它不是一个新 OCR 模型,而是一个面向 Agent 时代的文档解析 Skill。装上就能用,说话就能调,不用写一行代码。
和其他文档解析方案比,强在哪
xParse 背后是合合信息 TextIn 的生产级文档解析能力,本身就在服务各个行业的头部大企业:
解析精度:复杂表格、标题层级、文字识别率效果领先 速度:极快,是同行的 3~5 倍 兼容性:适配主流国产软硬件设备(显卡、数据库等) 企业级观测能力:完整的日志记录和回查 企业级调度能力:支持解析任务优先级调整、同步/异步接口调度
但最让我觉得省心的,不是这些硬指标——而是它作为一个 Skill 的存在方式。
从 0 跑通一次 Skill 调用
安装:一句话的事
方式一:对话框直接说
帮我从技能市场安装 intsig-textin/xparse-parser方式二:npx 命令(推荐)
npx skills add intsig-textin/xparse-skills --yes方式三:手动安装
从 GitHub 或 Gitee 仓库拉取:
- https://github.com/intsig-textin/xparse-skills- https://gitee.com/intsig-textin/xparse-skills初始化:也是一句话
帮我初始化 xparse-cli 工具,更新到最新版本凭证配置只需要一条命令:
xparse-cli auth按提示输入 App ID 和 Secret Code,保存到 ~/.xparse-cli/config.yaml,后续自动读取。
注册地址:https://www.textin.com/market/detail/xparse?from=5l27ydqsktg
每天1000页的免费额度基本能够个人使用,如果需要解析的文件不属于PDF和图片,需要解锁更多格式比如office、HTML等等可以升级凭证,单次处理的文件大小和页数也会更多。不过最近注册都会送1000页,升级不亏,体验更丝滑。
也支持环境变量方式(适合 CI/CD):
export XPARSE_APP_ID=your_app_idexport XPARSE_SECRET_CODE=your_secret_code使用指南:说人话就行
在 OpenClaw、Claude Code 等 Agent 平台安装 xParse Skill 后,自然语言指令即可完成解析全流程:
"帮我读一下这份 PDF 合同,提取关键条款" "把这个报告转成 Markdown,保存到桌面" "这份加密 PDF 密码是 123456,帮我解析前 10 页" "提取这张表格图片里的内容,输出 JSON"
全程你不用写一行代码,甚至不用知道 xparse-cli 怎么用。
使用体验
无线表和分行,完全没有压力
上传了一份论文,使用xparse-cli做做分析,完全不在话下。只需在输入一句话,就能得到结果:
使用xparse-cli工具,把12页的table 3,提取出来
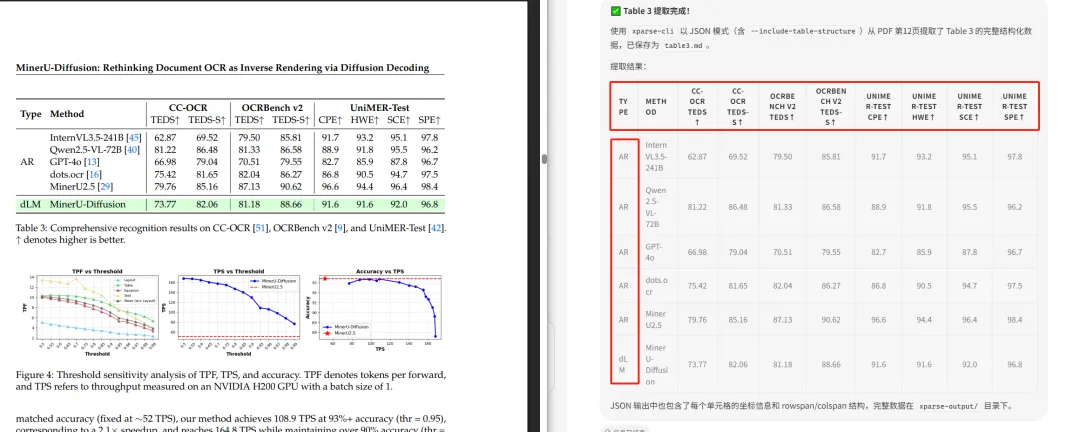
默认开启的解析能力:标题层级识别、表格结构保留(HTML 格式)、图片提取、目录树生成、分页结果。唯一需要手动开启的是 --include-char-details(字符级坐标),因为这个会大幅增加返回数据量。
研报理解也能行
可搜:上传一份研报,TextIn xParse可以把文档结构化为层次清晰,干净的MD格式。
高阶一点,如果想要对固定内容做提取和分析,我们可以这么干:
使用xparse-cli工具,找到包含 ‘归母净利润’的表格,转成markdown
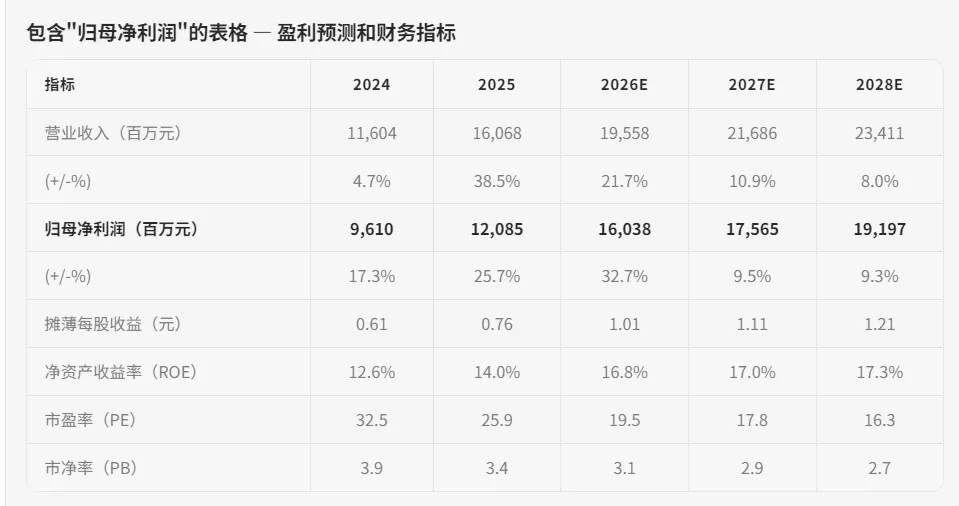
可理解:结构清晰了,内容准确了,理解就是手到擒来。对于研报指标,一句话都能得到准确值和走势,分析和写文档进一步简化:列出每年的归母净利润是多少,做出折线图
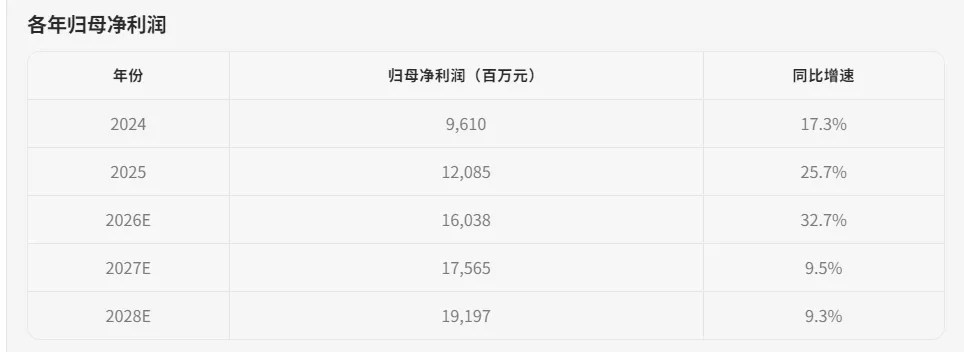
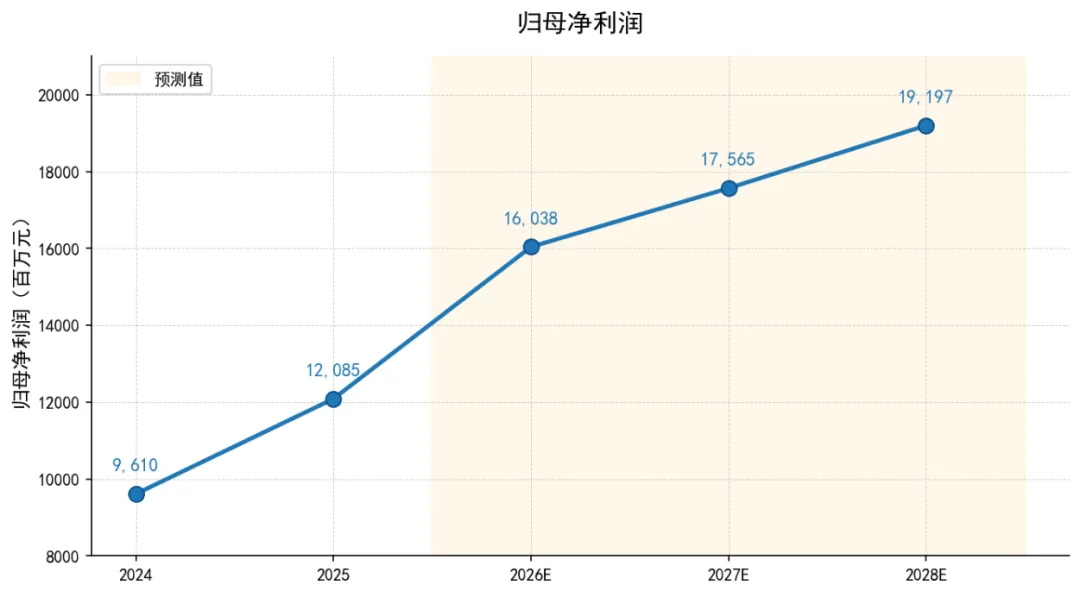
统计和应用就是这么简单,以前复制、粘贴、写函数的工作统统没有了。
文档解析的终极目标不是"读出来",而是"用起来"。
融合到你的LLM Wiki
四步走:
任意选一个开源的 LLM Wiki 实现 让 Agent 把仓库在本地拉起来 让 Agent 将 xParse 替换原来的解析层 问答体验
几个可用的开源实现:
我的判断
看完TextIn xParse Skill,我最大的感受是:文档解析这件事,终于从"技术问题"变成了"集成问题"。
过去你选 OCR 工具,要考虑模型精度、部署复杂度、API 调用方式、输出格式适配……每个环节都是坑。
现在TextIn xParse 把这些全包了,而且以 Skill 的方式存在——Agent 说一句话就能调,不用管底层是 API 还是 CLI,不用管输出格式是 Markdown 还是 JSON。
这才是 Agent 时代文档解析该有的样子。
项目地址:https://github.com/intsig-textin/xparse-skills凭证注册:https://cc.co/16YSfd