 夜雨聆风
夜雨聆风继续跟进【文档智能】解析进展。 多模态文档解析目前整体架构方案侧没有什么特别大的改变,最近进展的几个模型(DocHumming和paddleocr-vl-1.6)仍然集中在训练数据的构造上(尤其是拍摄场景等)。
DocHumming方案
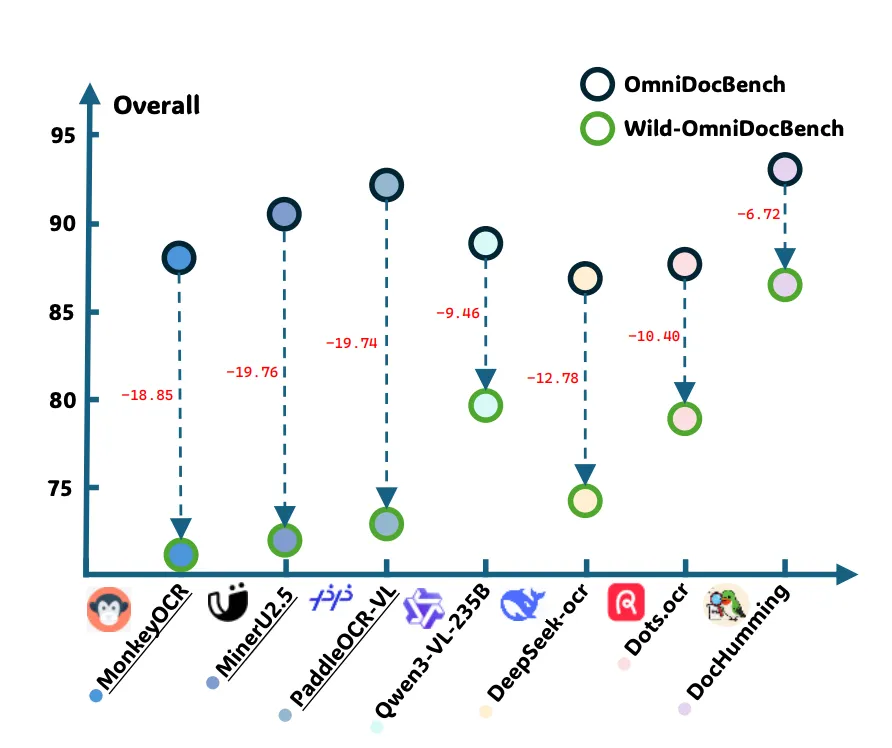
如下图,DocHumming提到mineru等级联模型【先layout再ocr】在拍照等场景容易产生幻觉,并且缺少大规模高质量全页SFT数据。

故DocHumming的主要方案就是解决上述两个问题,主要从数据合成层面进行。
真是场景数据合成

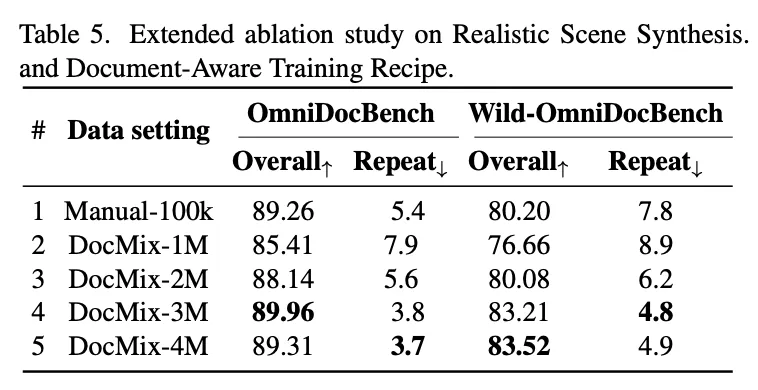
整个pipeline:区块元素库【表格、公式、段落、图像】 + 布局模板库【收集带阅读顺序标注的公开布局数据集+网络挖掘真实文档布局】 → 按空间/结构约束合成全页文档 → 真实拍照感知增强 → 输出DocMix-3M合成数据集【多语言、结构高度多样、带显式阅读顺序】。
真实拍摄感知增强:模拟随手拍摄的真实干扰,缩小合成→真实域间隙:
几何干扰:透视偏移、弯曲、褶皱、卷曲; 光度干扰:光照不均、曝光变化、阴影; 相机干扰:随机旋转、拍摄角度偏移; 环境干扰:真实背景叠加。
训练方案
渐进式训练分两个阶段:
阶段1:元素级训练【数据:9M孤立原子元素(表格/公式/段落)】 阶段2:全文档统一训练【DocMix-3M + 1M阶段1样本 + 10万人工标注真实文档】
结构Token感知优化
核心问题:常规训练对所有输出Token一视同仁,而表格/表单等结构边界Token一旦出错,会引发整段重复、结构坍塌。
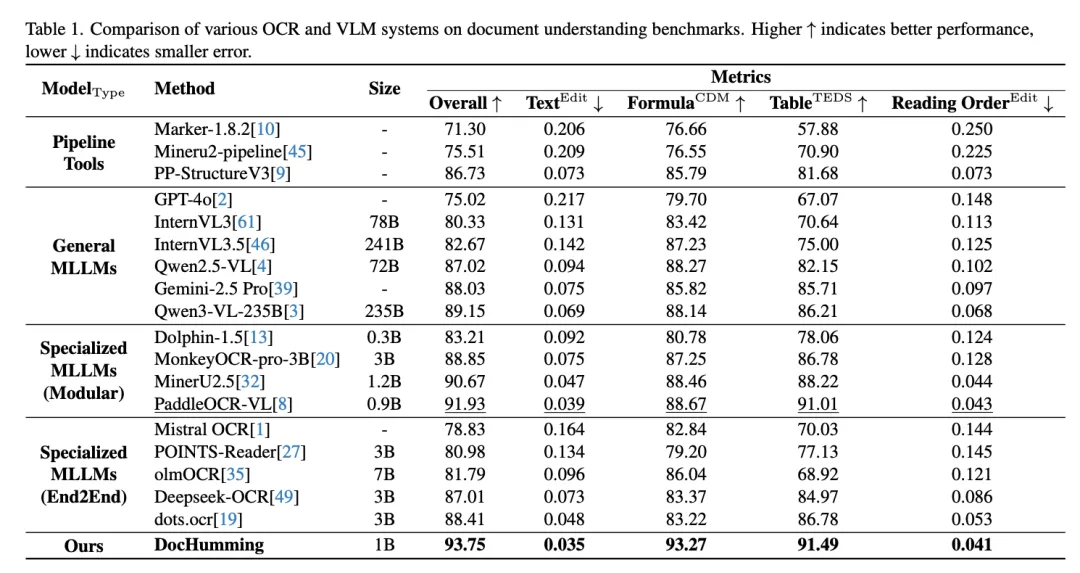
实验评测
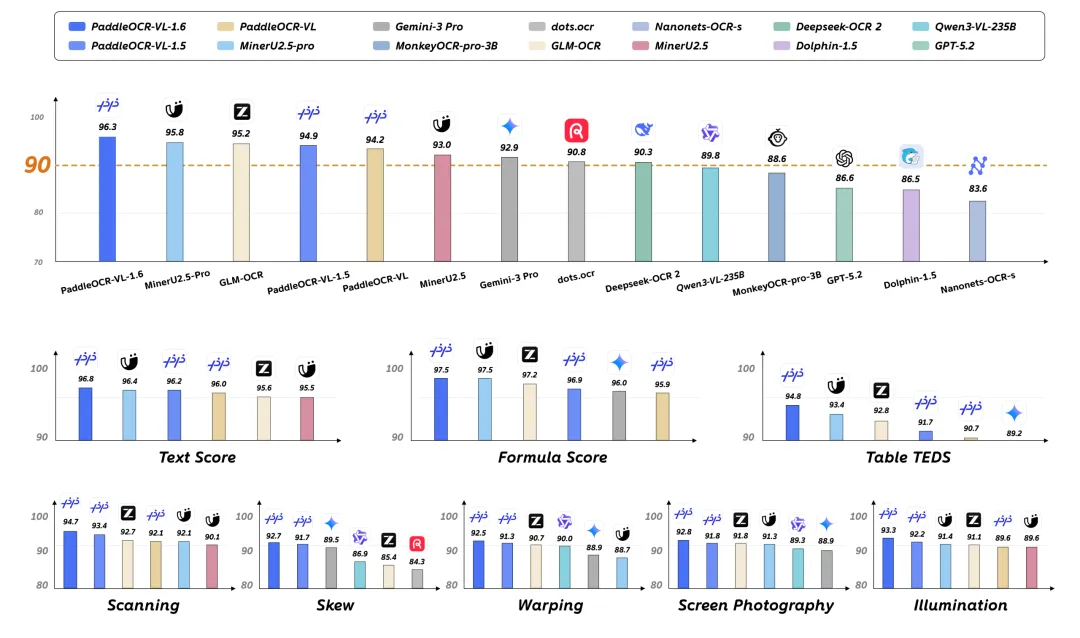
PaddleOCR-VL-1.6
PaddleOCR-VL-1.6优化了集中出现在一批欠优化区域中——包括预测不稳定、数据覆盖不足、监督信号不可靠等局部弱区。围绕这些弱点构建高价值数据,最后通过继续预训练、监督微调、强化学习的渐进式后训练流程,将新增数据的价值稳定注入模型。
模型架构及演进方案在前期文章中也讲过,这里不再继续赘述,下面主要也看其在数据构造上的特点。
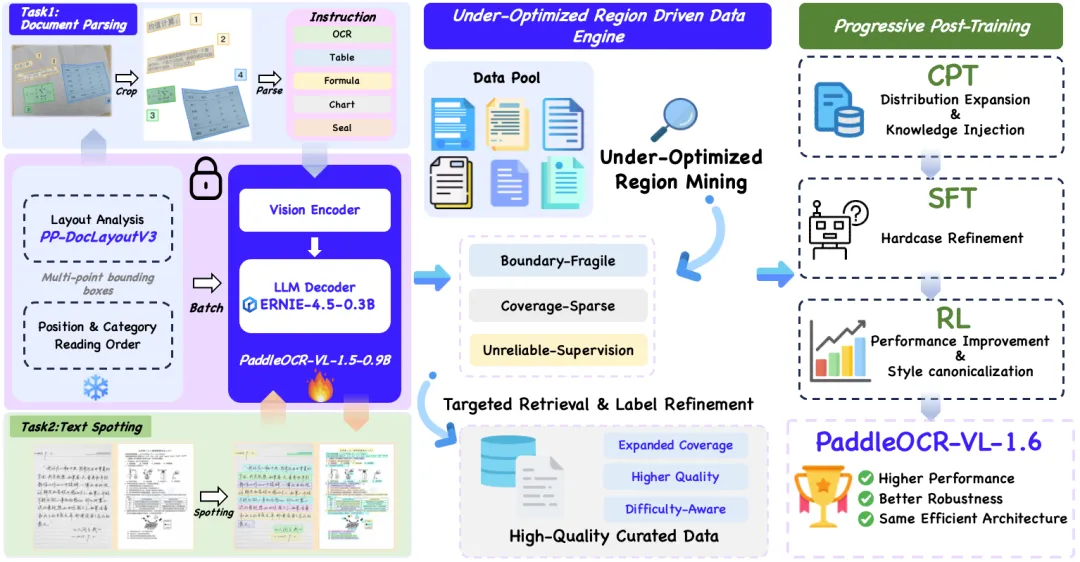
从上图可以看到,PaddleOCR-VL-1.6相比上个版本主要集中优化了上版本弱项内能力(一些比较少见的长尾case)。
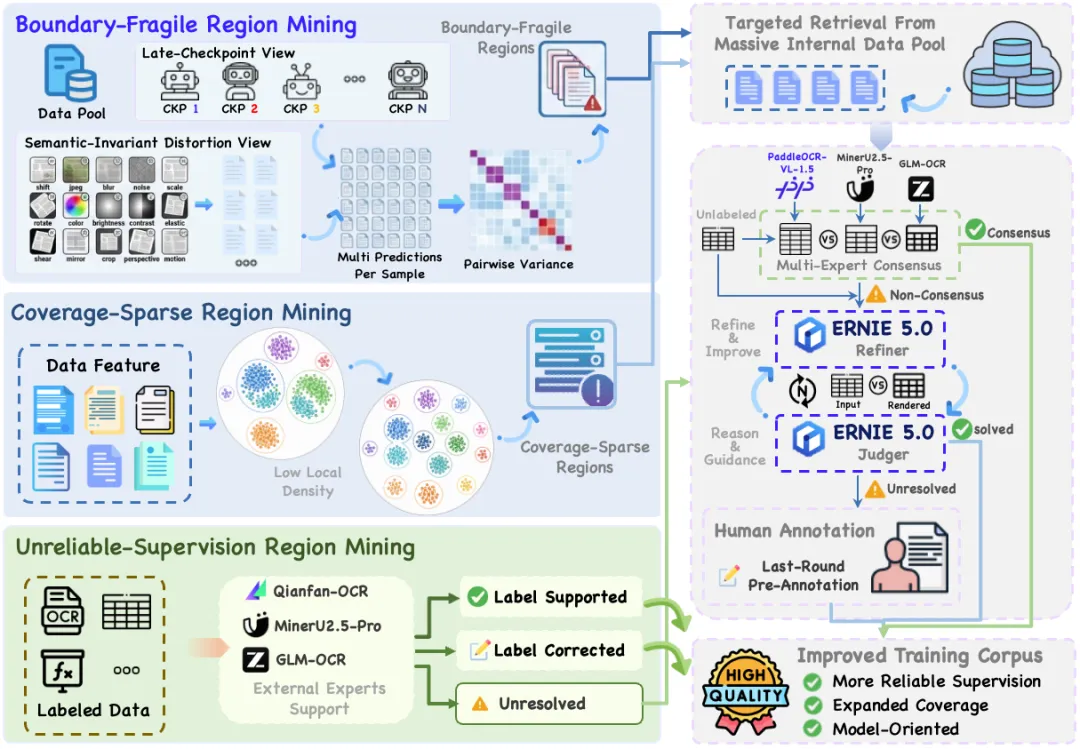
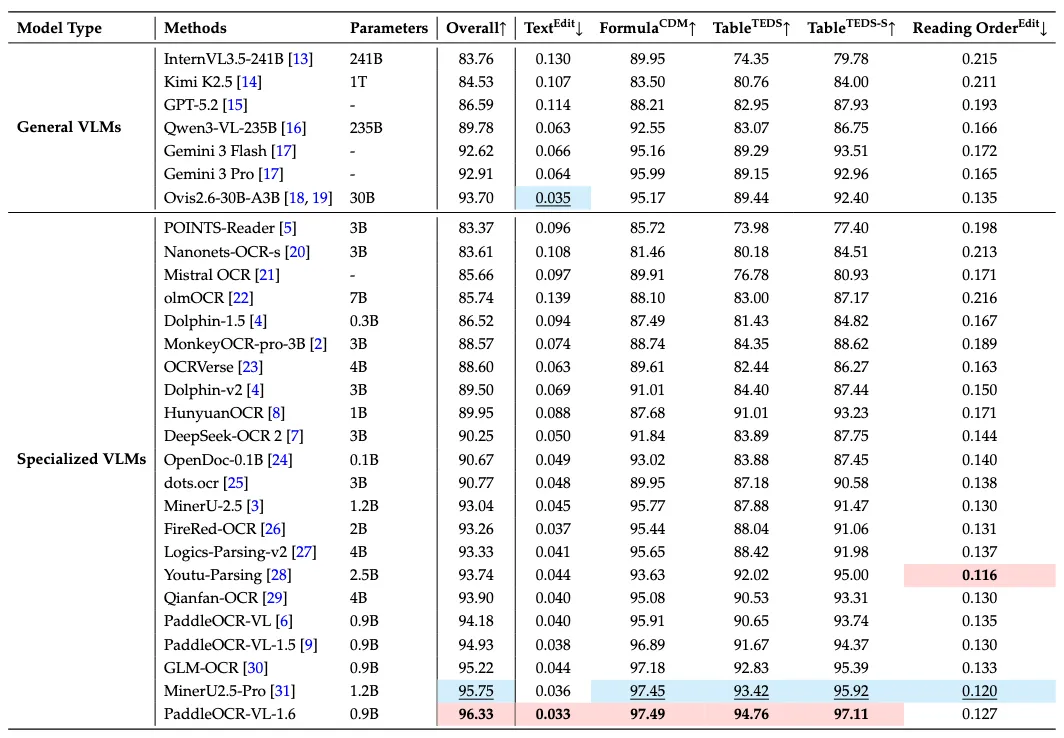
实验评测
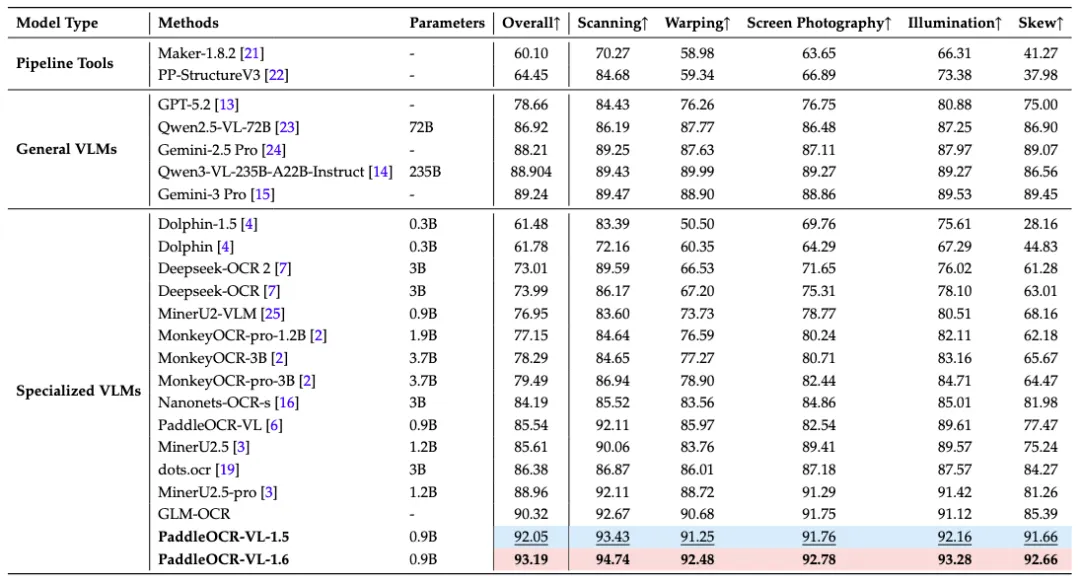
参考文献
Towards Real-World Document Parsing via Realistic Scene Synthesis and Document-Aware Training,https://arxiv.org/pdf/2603.23885v1 huggingface.co/PaddlePaddle/PaddleOCR-VL-1.6
往期相关
多模态文档解析的开源项目模型技术方案都在《文档智能专栏》,如:
...
