 夜雨聆风
夜雨聆风
职场里最让人崩溃的瞬间是什么?
你带着满脑子牛逼的方案推开会议室的门,结果却花了10分钟满地找HDMI线、找转接头、调分辨率,把投屏重新折腾一遍,全场人干巴巴地看着你。
最近,我在用 AI Agent 帮我处理网页自动化任务时,真切地体会到了这种感觉。
不管你是搞AI研发需要全网追踪开源项目,还是做自媒体需要高频刷新各大平台的热点榜单,亦或是每天要登录好几个后台系统扒取数据报表的业务人——理论上,这些繁琐的浏览工作,只要一句话,Agent 就应该能帮你全部搞定。
但现实中,让 Agent 去同一个网站执行相似的任务,它的表现就像那个永远记不住你电脑型号的旧投影仪。
你想让它查个资料,它常常迷失在无尽的超链接里;想让它填个表单,它总是找不到隐藏的下拉框;想让它盯个动态,它每次都要重新摸索一遍页面的DOM结构。
派一次活,你就要手把手重新教一遍。
01
一场血压飙升的"在线连线"
前几天,我想让 Agent 帮我查一下B站某位UP主的最新视频数据。我以为这是一句话的事,结果却变成了一场让我血压飙升的在线教学。
一开始,它不走正道,试图用通用的搜索引擎去搜,结果全是过时的网页快照。
💬 "你直接进B站搜。"
进了B站,它又在首页迷路了,找不到UP主的房间。
💬 "不是这个,你点UP主头像进去。"
好不容易进了主页,它又瞎转悠,点了半天其他标签页。
💬 "点投稿,按时间排序。"
就这样,在我的反复纠正下,它勉强完成了任务。但一看时间,10分钟过去了。
更要命的是,仅仅这一次查询,就吃掉了将近 150k 的上下文窗口。当上下文被大量消耗时,模型的推理能力会明显衰减。更糟糕的是,下周如果我再让它查一次,同样的事情还要再来一遍。
那天查完视频后我坐在电脑前,意识到一个致命问题:我不是在让 Agent 帮我查视频,我是在一遍遍地教它"怎么使用B站"。
这感觉,简直和我每天在3号会议室重新拔插一次投屏线、重新调一次分辨率一模一样。
02
Agent缺的不是知识,而是"程序性记忆"
人类的记忆分两种。
一种是"知道是什么"(陈述性记忆),比如你知道引力波的概念;另一种是"记住了怎么做"(程序性记忆),比如骑自行车、游泳,你一旦学会,身体就会自动平衡,不需要每次重新推导。
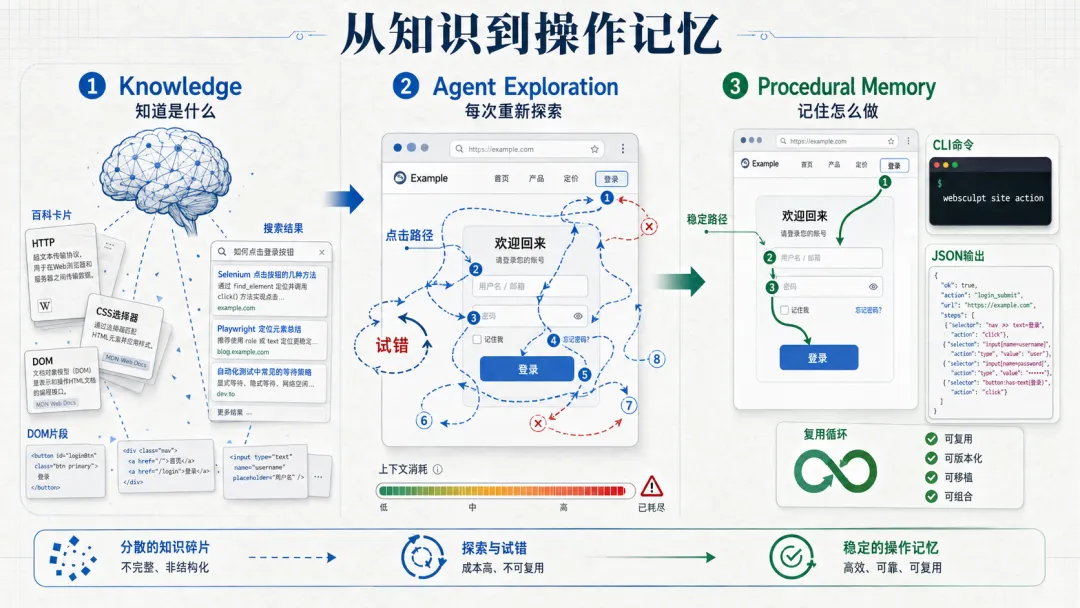
现在的 Agent 方案已经能解决很多问题,但它们赋予AI的大多是"陈述性"的知识。它知道B站是什么,也知道怎么点击,但它就是没法在外部沉淀出"怎么获取B站数据"的程序性记忆。
这导致了单次操作极度消耗上下文,复杂的长链路更是经常崩溃。就像你其实知道HDMI线长什么样,但系统就是无法自动记住匹配协议,每次都要重新握手。
现在操作浏览器的工具,底层有 playwright 这样成熟稳定的自动化框架,之上也有 playwright-cli 让 Agent 能够通过命令行直接调用浏览器。
但它们依然没有解决"记忆"的问题。
开源社区试图将软件或网站 CLI 化(预置各种命令库)来解决,但我很快发现它无法覆盖我的需求——互联网是无限的,我想查知乎上我最新文章的"阅读量、赞同数、评论数、收藏趋势",没有任何预置库会内置如此个性化的指令。
去阅读底层源码自建命令?太费劲了。这让我有了一个新思路。
03
WebSculpt:把旧会议室,改造成"推门就亮"
我真正需要的,不是把整个知乎变成一个通用的API,而是把"我查知乎数据"的这个习惯,让AI沉淀下来。
基于这个想法,我开发了 WebSculpt。
它本质上是一个浏览器自动化的 CLI 命令记忆层。如果说之前的自动化工具是让你每次手动插线,那 WebSculpt 就是给你的系统装了一个"无线智能记忆":只要你成功连过一次,下次一句话,屏幕瞬间点亮。
安装极其简单,你甚至可以直接把我的 GitHub 地址扔给 Agent,让它自己跑下面两行命令:
npm install -g @playwright/cli@^0.1.8 websculptwebsculpt skill install --lang zh
这两行命令的本质,不仅仅是装了个工具,而是向你的 Agent 植入了三个协作 Skill(技能)。它们有着清晰的分工:
🔍 websculpt-explore:指引 Agent 在没有现成命令时,去探索网络,并完成浏览器自动化的试错与跑通。
💾 websculpt-capture:指引 Agent 将探索成功的经验,转换为标准命令格式,完成知识的沉淀。
🛡️ websculpt-scope:指引 Agent 自动感知当前项目需要哪些命令,过滤无关项,保持上下文的绝对纯净。
加入了这个"记忆层"后,Agent的操作会发生什么根本性的改变?看下面这个工作流:
🏃♂️ 第一次:探索与沉淀(辛苦踩坑)
你:"帮我查一下知乎热榜。"
Agent 检查本地记忆库,发现没有相关命令。于是自动打开浏览器,开始尝试解析页面、寻找热榜元素、测试验证。几分钟后,拿到数据。
此时,Agent 会询问:"我已经跑通了路径,是否需要将这段经验沉淀为 zhihu/get-hot 命令?"
你:"确认沉淀。"
当初 Agent 折腾半天跑通的路径,此刻已经变成了一个极其精简的本地命令资产。
🚀 第二次:零成本无限复用(推门就亮)
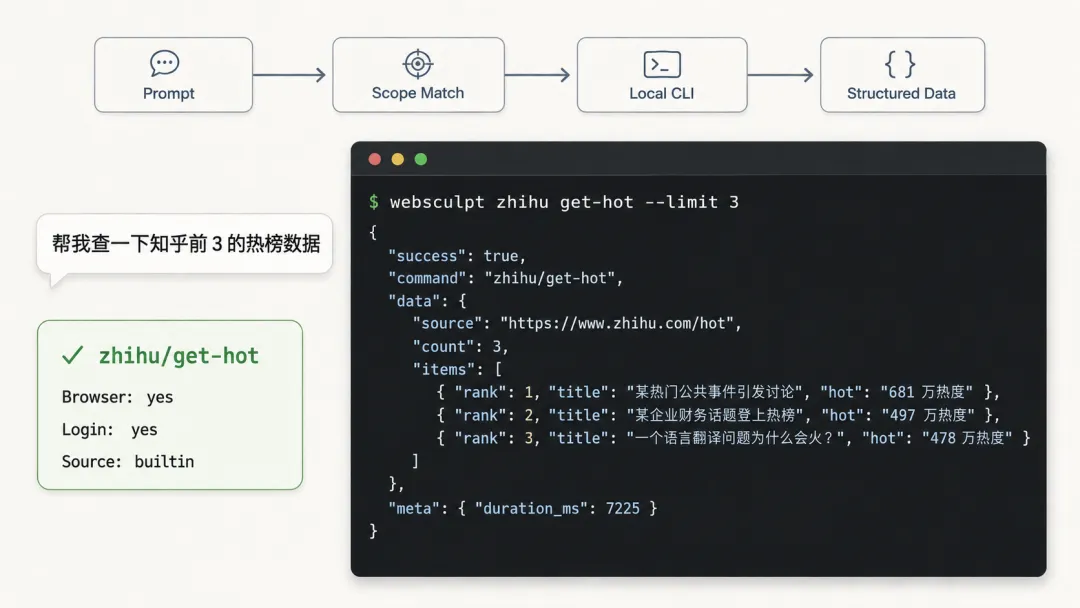
几天后,你:"帮我查一下知乎前3的热榜数据。"
这次,Agent 发现了记忆库里的 zhihu/get-hot,它毫不犹豫地直接调用代码:
$ websculpt zhihu get-hot --limit 3
屏幕闪烁了一下,数据秒级返回。就像你推开会议室的门,PPT已经完美显示在大屏幕上。
这一次,没有漫长的DOM分析,没有盲目的点击试错,零 Agent 思考时间,零额外 Token 消耗。纯代码执行,结果极其稳定。你甚至可以自己在终端里手动敲入这行代码,获得完全一致的结果。
04
纯净的上下文与"自带账号体系"
随着日常使用,你的命令库里可能会积累几十上百个命令。为了防止过多的命令干扰 Agent 的判断,WebSculpt 支持 Scope(项目级白名单)机制。
你不需要去记繁琐的配置指令。 只需要直接和 Agent 说:"当前这个项目我只需要知乎相关的命令。"
Agent 就会自动替你配置白名单,屏蔽掉 B站 或 GitHub 的指令噪音,从而保持极致纯净的上下文。
更重要的是,WebSculpt 解决了一个核心痛点:登录态。
国内极具价值的信息几乎都在站内,必须登录才能查看。大多数人并不愿意把自己的账号密码或 Cookie 交给第三方的云端 API。
WebSculpt 通过 CDP(Chrome DevTools Protocol)直接连接你本地的 Chrome 浏览器。这就意味着它天然复用你本机的登录态。这种"本地CLI + 本地浏览器"的组合,是兼顾自动化与保护隐私最合理的边界。
05
水面下的状态机:约束Agent的边界
为了保证这种"无限复用"的绝对稳定,WebSculpt 在水面下的执行逻辑设计了一套严密的约束机制。
最核心的设计,是将过程拆分为 explore(探索) 和 capture(沉淀) 两个严格分离的阶段。这就像是"试驾"和"量产"的区别。
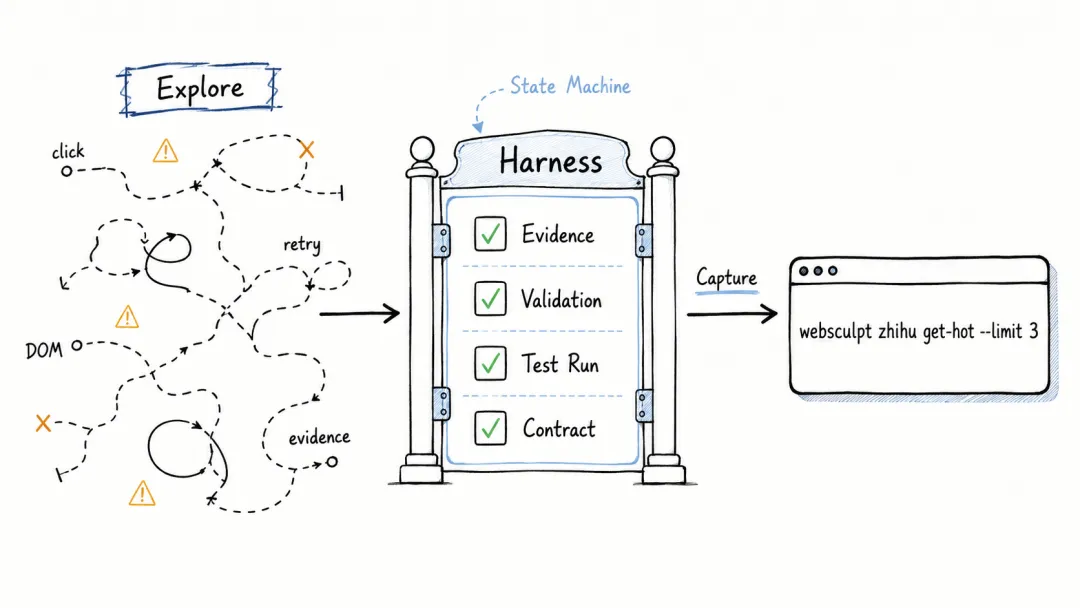
在探索阶段(试驾),允许Agent犯错、走弯路,目标是把路跑通;但在沉淀阶段(量产),要求极度严谨。
如果不加约束,Agent 经常会"自由发挥"(比如跳过关键步骤)。因此,底层的核心机制是一个 Harness 状态机。Agent 只有提供了证据、通过了校验和测试,状态机才会允许它进入下一步,从根本上杜绝了交付残缺代码的可能。
💡 写在最后
梳理 WebSculpt 逻辑的过程,其实也是我重新思考人与AI关系的过程。
一开始,我觉得把常用的网站封装成CLI就够了。但最后我发现,每个人对数据的诉求千差万别。不是网站需要被CLI化,而是你使用浏览器的"业务习惯"需要被CLI化。
工具应当记住人的成功经验,而不是让人去适应工具的预设。
AI 模型再强大,它的强项在于理解DOM、编写脚本、执行点击;而定义一条有价值的数据获取路径,依然需要人的经验去引导。把这条经验喂给 AI,并固化下来,这才是完成自动化闭环的关键。
AI 时代的稀缺资源,不是算力,而是"用好AI、并知道如何让AI沉淀业务逻辑的人"。
如果你也受够了同一个网站每次都要重新教 Agent 一遍的折磨,受够了每次进会议室都要重新连投屏的无力感,欢迎来试试 WebSculpt。
让AI真正成为那个"推门就能开会"的默契搭档。
👇 获取方式 / 开源地址 👇
GitHub地址:github.com/bqw1013/WebSculpt(开源不易,欢迎来点个 ⭐️ Star 支持一下)
一键安装命令:npm install -g @playwright/cli@^0.1.8 websculpt

💡 互动一下:你在用 AI 做网页自动化时,经历过哪些"高血压"瞬间?欢迎在评论区和我聊聊。
