 夜雨聆风
夜雨聆风先说个题外话:我的"笔记软件折腾史"
我折腾笔记软件这件事,差不多有十几年了。
最早是百度网盘——存了一堆 PDF 和课件。说实话,存在百度网盘里的东西,打开的概率比收藏夹还低。后来硬盘换了,那些文件至今还在网盘里躺着,再也没动过。
然后换了印象笔记——剪藏了一堆文章,分类建了十几个笔记本,当时的想法是"以后一定能用上"。后来发现,那个"以后"从来没来过。
再后来用飞书文档——毕竟工作天天用飞书,顺手建了个人的知识库,塞了不少东西。换工作之后,那些文档和我的飞书账号一起留在了前公司的服务器里。
最近还试了语雀和IMA——觉得"这次应该能坚持下来了吧",但说实话,存进去的东西还是在"吃灰"。
你发现没有?工具换了一个又一个,但问题从来都没变:存进去了,就没再打开过。
年前整理过一次印象笔记,翻到一条 2022 年存的关于"PMP 备考攻略"的文章——那时候想转项目经理岗,想着存下来以后考了有用。结果四年过去了,PMP 证书还没考下来,那篇文章还在印象笔记里躺着。
这不是工具的问题,是我的"知识管理方式"本身就有问题。
所以我看到卡帕西那个「LLM Wiki」概念的时候,第一反应不是"这是啥",而是——他是不是也经历过一样的痛苦?
先说说卡帕西是谁
Andrej Karpathy,前 OpenAI 创始成员,前特斯拉 AI 总监。AI 圈的大神级人物。
今年 4 月,他发了一个 idea file——不是一个论文,不是一套代码,就是一个想法。结果这篇内容被大量转发和讨论。
我读完他的原文后,最大的感受是:这个思路太"反直觉"了,但越想越有道理。
他核心就解决一个问题:知识存了不用,等于没存
卡帕西有一个很形象的比喻。
传统的知识管理,是让你自己当图书管理员——你要亲自分类、打标签、写摘要、建索引。听起来很美好,但现实是:大多数人连分类都懒得做,更别提后续维护了。
所以你收藏的文章越来越多,但真正消化的、串联起来的,几乎没有。
那么,能不能反过来?
卡帕西说了一句话,我觉得是整个 LLM Wiki 的核心:
让 AI 来当图书管理员,你来当读者。
而 Obsidian 在这套体系里,就是读者的"阅读器"。
为什么偏偏是 Obsidian?
你可能想问:那么多笔记软件,为什么卡帕西选 Obsidian?
三个原因:
① 文件是纯本地的 Markdown
你存的所有内容,都是 .md 文件,存在你自己的硬盘上。不存在"换公司了资料带不走"的问题。不存在"软件倒闭了数据怎么办"的问题。你的知识永远是你自己的。
② 文件即数据,AI 可以直接读
这很关键。印象笔记的数据是存在它的服务器里,飞书的数据也是云端封闭格式。但 Obsidian 的 Markdown 文件,AI 可以直接打开、读取、修改。这是 LLM 能帮你"管理"知识库的前提。
③ 双向链接,天然适合知识网络
Obsidian 最核心的功能是双向链接——你可以在两个笔记之间建关联,形成一个知识网络。LLM Wiki 自动帮你维护这个网络,你打开 Obsidian 就能直接看到。
卡帕西的原话是:Obsidian 是 IDE,LLM 是程序员,知识库是代码库。你只读代码,不写代码。
意思就是:知识库交给 AI 维护,你用 Obsidian 浏览和查阅就行。
那这个 LLM Wiki 到底是怎么运作的?
拆开来看,就是三层,而且每一层都不复杂。
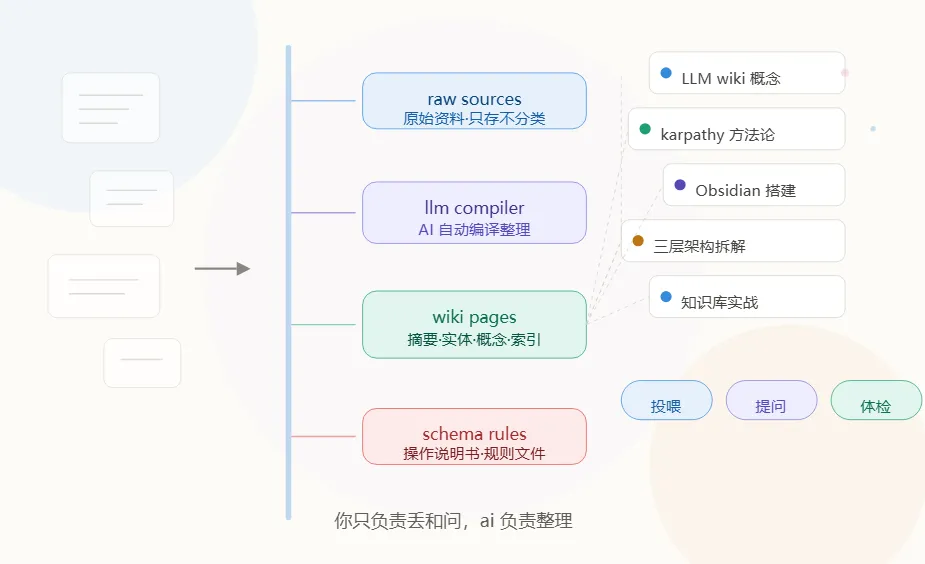
第一层:原料池
你看到什么想存的文章、论文、截图,直接丢进去就行,不用分类不用打标签。
对,没看错——不需要想"这篇该放哪个文件夹"。
唯一的要求:存进去就不能改。它是原始证据,AI 只读不写。
第二层:知识库
这是最反直觉的部分。
你存进去的文章,不需要自己写笔记。AI 来写。
你丢一篇文章,AI 自动做这些事:
你存一篇新文章,可能同时更新了 10 个已有的知识页面。你的知识不是一篇一篇堆在那里的,而是一张网——每加一条线,整张网都在变大。
第三层:操作说明书
AI 不是天生就会干这些活的。你需要给它一份"操作手册",告诉它:
这份手册你和 AI 一起写,用几次就越来越顺手。
日常怎么用?三个动作
动作一:投喂→ 看到好东西,存进去,让 AI 消化
动作二:提问→ 有问题直接问 AI,它会翻阅整个知识库来回答
动作三:体检→ 隔段时间让 AI 检查有没有矛盾、有没有遗漏
三个动作,没了。
你不用操心分类、打标签、建连接——这些全是 AI 的活。
最后
这篇文章只是把这个概念讲清楚。
那我自己到底能不能用这套方法,搭出一个真正有用的知识库?说实话,我也不知道。但我决定试试。
过几天我会用我自己这几年的实际内容当"试验材料",走一遍完整的搭建流程。能成最好,踩坑了就当给大家避雷了。
感兴趣的话可以留意一下后续。
参考:Andrej Karpathy「LLM Wiki」Idea File(2026.04)
