当前时间: 2026-06-06 08:09:25
分类:办公文件
评论(0)
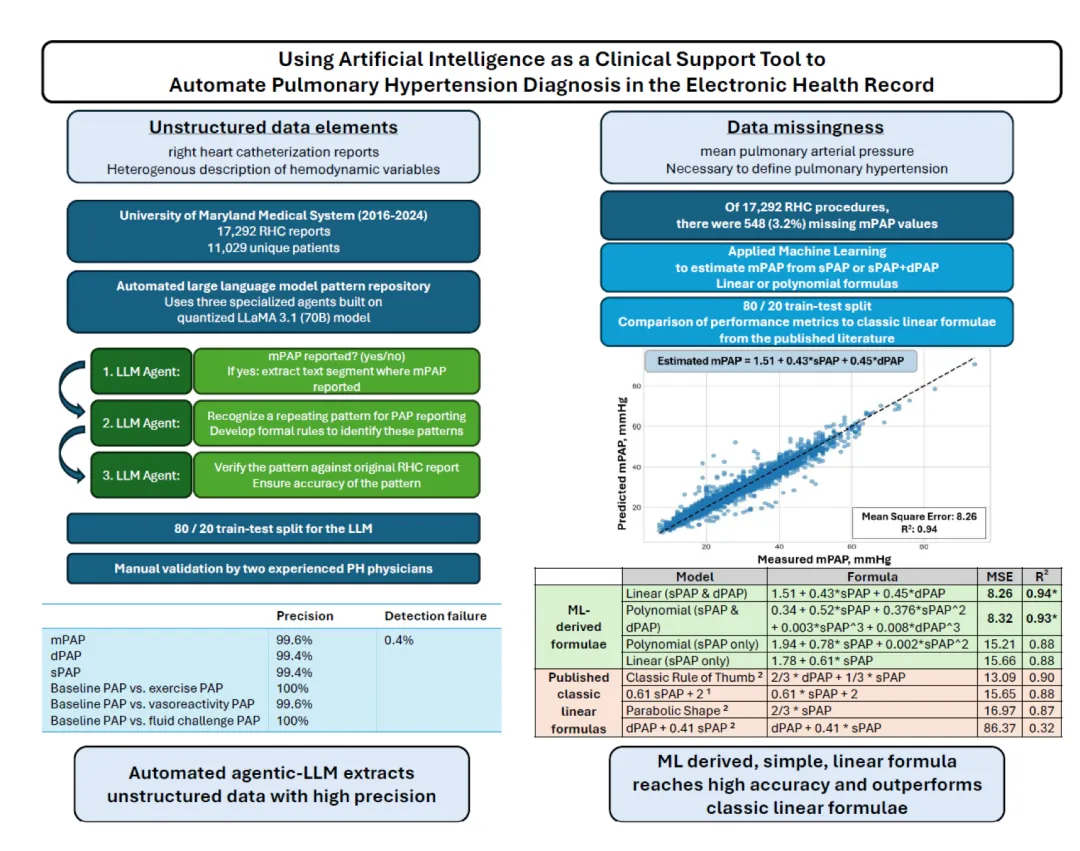
利用人工智能诊断肺高压的临床决策支持工具肺高压(Pulmonary hypertension, PH)是一种高致死致残率的疾病,需要及时诊断以确保患者能够在专家转诊中心接受适当的临床治疗 [1, 2]。然而,临床上对肺高压的警惕性普遍较低,导致诊断往往被延迟,在某些可治疗的亚群中,延迟时间甚至可达两年或更久 [3]。在非肺高压专家诊疗中心,这一问题尤为突出,因为在真实世界的临床实践中,那些对诊断肺高压有用的临床检查结果往往缺失,或者即使存在也常被忽略 [4]。综合这些观察结果表明,我们需要自动化方法来提高常规临床实践中肺高压的准确诊断率。在右心导管检查(Right heart catheterization, RHC)中,平均肺动脉压(mean pulmonary artery pressure, mPAP)升高 >20 mmHg 是诊断肺高压的必要条件,且其存在会增加发生心力衰竭的风险 [2]。2014年,美国进行了超过37.5万例右心导管手术 [5],但仅有82家注册的肺高压专家诊所 [6]。这一现状表明,绝大多数右心导管手术是由非肺高压专家完成的,这也意味着通过关注右心导管检查结果来提高肺高压诊断准确性存在巨大的提升空间。建立一种即使在定义肺高压的关键数据缺失时,也能根据右心导管检查结果准确诊断肺高压的临床决策支持工具,将有助于解决这一庞大且处于心衰风险中的弱势患者群体因诊断延迟而延误治疗的困境。在现代数字化时代,美国乃至全球的医疗系统都在不断扩张。这些医疗系统将城市和农村地区的医院及门诊通过一个统一的行政系统——即电子健康档案(EHR)连接起来。EHR记录了患者在所有社会经济背景下的就医数据,包括诊断测试、临床病程记录和处方,这使得研究患者的真实世界情况成为可能 [7]。然而,利用这一丰富的数据集要求研究人员克服阻碍高效手动整理数据的主要挑战。首先,EHR中包含的信息范围极其庞大,通常超过1万亿个数据点。其次,数据存储在众多且完全不同的格式中(例如自由文本格式)[8]。此外,EHR数据还面临缺失的问题。事实上,数据缺失是真实世界临床实践中评估医疗质量的一个主要障碍。例如,在以往的EHR数据集中,mPAP的缺失率约为7%至10% [9, 10],而在一个大型基于右心导管的登记研究中,这一比例甚至达到了33% [11]。这些共同的挑战可以通过人工智能(AI)来克服。具体而言,大型语言模型(LLM)(例如 ChatGPT)具有极大的吸引力,因为它们可以在极短的时间内协调和处理海量的文本,并对这些信息进行简单明了的总结。虽然已有研究提出利用标准LLM提取EHR数据的潜力 [12],但目前可用的普通LLM通常准确率不够理想,且无法解决数据缺失的问题。在这项研究中,我们分析了马里兰大学医疗系统(UMMS)自2016年1月1日至2024年12月31日的右心导管(RHC)报告。UMMS是一个覆盖马里兰全州的临床网络,服务约230万名患者,包括12家医院和398家门诊。我们收集了基线人口学特征,包括年龄、自报种族和性别、身高、体重、体质指数(BMI)、右心导管检查日期,以及右心导管检查前6个月内基于国际疾病分类第10版(ICD-10)编码的临床合并症 [9, 10]。本研究获得了马里兰大学机构审查委员会(IRB)的批准。我们开发了一个自动化的LLM,用于提取mPAP以及右心导管结果中经常报告的其他变量。我们的LLM(基于量化的 LLaMA 3.1 [70B] 模型构建)被设计用于执行一个包含三个步骤的任务。每一步都由一个“智能体(agent)”来执行,这是一种具有推理和规划能力的计算功能(统称为“智能体大语言模型,agentic-LLM”)。第一步(Agent 1):LLM分析每位患者的整份右心导管报告,并确定是否存在肺动脉压(PAP)值(“是否存在PAP值?”)。如果答案为是,LLM将提取包含该PAP值的完整文本段落(例如,“mean pulmonary arterial pressure is 25mmHg”;“sPAP/dPAP/mPAP was 47/17/32” 等)。第二步(Agent 2):识别并协调右心导管报告文本中PAP的汇报模式(即“正则表达式风格”的模式),以便准确提取每份报告中的PAP。第三步(Agent 3):对照原始右心导管手术记录对包含PAP值的文本段落进行验证,以确保一致性和准确性。这些步骤形成了一个迭代算法,用于优化PAP提取的准确性。我们对UMMS的EHR数据进行了 80/20 的训练-测试集划分(即80%的数据用于开发模型的提取模式,20%的数据用于评估该模式)。随后,由两位资深的肺高压临床医生(K.Z., M.E.M.)在随机选择的500份报告(代表该队列中的每个年份和每家医院)上,对LLM提取的PAP值(平均压、收缩压和舒张压)进行了独立的盲法人工验证。该LLM在来自11,029名UMMS独特患者的17,292份右心导管报告上进行了开发和验证。患者平均年龄为66(13.5)岁,43%为女性,65%为白人,30%为黑人或非裔美国人,BMI为30(7.7)kg/m2,平均mPAP为28 mmHg(范围为4–94 mmHg)。与人工裁决相比,LLM准确提取mPAP、sPAP(收缩性肺动脉压)和dPAP(舒张性肺动脉压)的精准度(Precision)分别为 99.6%、99.4% 和 99.4%。在区分基线PAP值与运动、血管活性试验或液体负荷试验(部分患者在右心导管术中进行的干预操作)后的PAP值时,其精准度分别为 100%、99.6% 和 100%。LLM对已汇报但缺失的PAP值的检测失败率仅为 0.4%(见附图)。鉴于大型医疗系统中右心导管结果中经常缺失mPAP,我们接下来开发了一种利用其他可用右心导管变量来插补(impute)缺失mPAP的方法。我们选择应用机器学习(ML)来寻找能够以最高准确度预测mPAP的公式。我们尝试了使用单用sPAP,或联合sPAP/dPAP来预测mPAP的线性及多项式回归模型。每个模型的性能通过决定系数(R2)和均方误差(MSE)进行评估,并使用双尾 t 检验将结果与先前发表的经典公式进行对比。模型开发和统计检验在 Python 中使用 scikit-learn 和 scipy.stats 包进行。在总共 17,292 份右心导管报告中,有 548 份(3.2%)报告(涉及 507 名 [4.6%] 独特患者)存在 mPAP 缺失但 sPAP 和 dPAP 可用的情况。通过对数据集应用机器学习获得的简单线性公式为:mPAP=1.51+0.43×sPAP+0.45×dPAP该公式达到了 R2=0.94 和 MSE=8.3 mmHg。事实上,应用 Bland-Altman 分析,我们观察到该公式在预测 mPAP 方面的表现优于所有经典的线性方程(p<0.001) [13-15](见附图),并且在所有模型中偏差最低(与报告的真实 mPAP 相比,偏差仅为 −0.1 mmHg)。值得注意的是,经典经验公式(“Rule of Thumb”、0.61×sPAP+2、抛物线形公式,以及 dPAP+0.41×sPAP)的均方误差(MSE)分别为 13 mmHg、16 mmHg、17 mmHg 和 86 mmHg(见附图)。其他使用多项式回归的更复杂机器学习方法的预测效果并未优于该线性公式(p=0.47)。更重要的是,在整个 mPAP 和肺动脉楔压(PAWP)谱系中,该机器学习推导公式在预测 mPAP 方面的优越性均表现得非常稳健。我们使用该机器学习推导的公式对缺失右心导管报告中的 mPAP 进行了插补。结果显示,在 507 名患者中,有 382 名(75.3%)患者的插补 mPAP >20 mmHg,达到了肺高压的诊断标准。该组患者的中位数(IQR)mPAP 为 32(26–39)mmHg。根据先前在全国转诊人群中发表的数据,与正常 mPAP 相比,这一压力水平与远期全因死亡风险独立相关,增加约 2 倍 [9]。因此,这些综合观察结果表明:本研究中大多数 mPAP 缺失的患者实际上确实患有肺高压;插补 mPAP 对于患者的风险分层具有重要且潜在的临床意义。本研究的结果表明,人工智能(在此为大语言模型 LLM 的形式)可以支持在大型且异质性强的医疗系统中实现肺高压的自动化诊断,特别是针对那些高风险患者与非专家频繁接触的医疗网络。我们观察到该 LLM 具有极高的准确性。当大语言模型与用于插补缺失 mPAP 的新型机器学习方法相结合时,我们开发出了一种简单、可扩展且极具成本效益的临床决策支持工具,解决了真实世界中肺高压漏诊、慢诊的难题。EHR 是了解真实世界临床管理和可治疗疾病诊断率的关键工具 [16]。尽管 EHR 具有这一强大优势,但巨大的异质性和数据缺失对基于 EHR 的观察准确性提出了挑战。例如,文献中描述“肺动脉压”所使用的术语具有广泛的异质性 [17],本研究中的右心导管报告也同样体现了这一点。如果不使用新型技术方法,在大型数据集中协调这种变异性是一项无法克服的障碍。在本研究中,我们构建的 LLM 成功克服了这一问题。与使用标准的 LLM 相比,我们开发了 智能体大语言模型(agentic-LLM),因为其具有执行复杂任务、在一定程度上自主执行操作、拥有记忆和持续规划的卓越能力,这与标准大模型基于“提示-响应(prompt/response)”的单次对话机制形成了鲜明对比 [18]。数据缺失是真实世界临床实践中评估医疗质量的一个主要障碍。例如,基于 EHR 的数据集显示 mPAP 的缺失率约为 7%–10% [9, 10],而在全球大型右心导管登记研究中,缺失率甚至高达 12%–33% [11]。先前用于从右心导管结果中计算缺失 PAP 的公式大多源自小型数据集(仅包含 22–94 名肺高压患者),且往往缺乏验证 [13],限制了其临床推外能力、普适性和临床应用。事实上,在我们最初尝试插补 mPAP 时,误差的方差是一个明显的混杂因素,其 MSE 范围高达 13–86 mmHg。然而,这一困境通过机器学习得到了化解,机器学习推导出的简单线性方程将 MSE 降至了 8 mmHg。我们创新的插补方法将 382 名患者从“无诊断状态”重新分类为“诊断为肺高压”。这一过程最终通过大语言模型和机器学习方法的协同工作得以实现,并显著影响了被重新分类患者的远期预后。此外,引入正确的肺高压诊断,使这些患者有可能获得有效的药物治疗或参与临床试验的机会,而如果没有这种床旁(point-of-care)临床支持工具,这一切都是无法实现的。虽然我们的评估利用了一个大型、多元化的多医院网络,但我们的发现(以及大模型的兼容性)在不同医疗系统中的可推广性仍需要进一步的验证。我们没有直接分析右心导管的压力波形,也没有从右心导管报告中提取分类肺高压所有亚型所需的全部变量,但这些都是未来的重要分析方向,可以进一步明确大模型在构建临床诊疗路径中的应用。本报告中描述的 AI 临床支持工具是为研究开发的,可以推广到外推更多的右心导管变量,以构建数字化的肺高压队列。下一个紧迫的步骤是在 EHR 中部署该 AI 临床支持工具,以进行前瞻性实用主义临床试验(prospective pragmatic trial)。该 AI 支持工具未来的临床相关性包括自动化且精准地:在床旁诊断肺高压,即使在 mPAP 缺失的情况下;及时将患者转诊至肺高压专家处,以接受符合 2024 ESC/ERS 临床指南推荐的靶向治疗 [2];通过自动化识别符合条件的患者,提高临床试验的入组效率。我们还注意到,我们的机器学习 mPAP 插补方法有望纠正临床操作员在记录数据时因四舍五入产生的“尾数偏好(terminal digit bias)”,从而减少潜在的患者错误分类 [19]。总之,我们利用人工智能从大型且异质的医疗系统的右心导管数据中成功提取了 mPAP 信息。在相当大比例的患者亚群中,这种方法带来了肺高压的新诊断,其中包括 mPAP 压力水平已达到与死亡风险显著升高独立相关的患者。该技术代表了一种利用 EHR 改善临床医疗的自动化支持工具。图:利用人工智能作为临床决策支持工具诊断肺高压。通过采用自动化的大语言模型,可以极高地准确度从电子健康档案(EHR)中提取数据元素。同时使用机器学习方法插补 EHR 中缺失的 mPAP 值,该方法的表现优于所有经典模型。(缩写:MSE:均方误差;sPAP:收缩性肺动脉压;dPAP:舒张性肺动脉压。参考文献 1:Chemla 等,Chest 2004;参考文献 2:Chemla 等,Chest 2009)这篇发表于《欧洲呼吸杂志》(Eur Respir J 2026)的最新研究,展示了如何通过人工智能(AI)与机器学习(ML)的协同作用,解决真实世界临床实践中肺高压(PH)诊断延迟与数据缺失的痛点。一、 核心要点
1. 真实世界痛点
肺高压诊断金标准是右心导管检查(RHC)中的平均肺动脉压(mPAP)大于20 mmHg。绝大多数 RHC 手术由非专家操作,且面临严重的 EHR 数据缺失(mPAP 缺失率在真实世界中高达 7% 到 33%),导致大量高危患者漏诊、慢诊。2. AI 工具的惊人准确性
基于 LLaMA 3.1 (70B) 量化模型构建的自动化工具,在提取 17,292 份 RHC 报告时,对 mPAP、sPAP、dPAP 的提取精准度高达 99.4% 到 99.6%。该工具能以 100% 的精准度区分基线静息状态压力与运动、液体负荷试验等干预后的压力。3. 机器学习插补与临床重分类
针对 3.2% 缺失 mPAP 的病历,利用机器学习推导出极简线性公式:mPAP = 1.51 + 0.43 * sPAP + 0.45 * dPAP。该公式的均方误差(MSE)仅为 8.3 mmHg,显著优于所有传统经验公式。通过公式插补,将 382 名原本无诊断的患者重新分类为确诊肺高压(占比高达 75.3%)。这群患者的中位 mPAP 为 32 mmHg,其死亡风险比常人高出约 2 倍,重分类使他们重获靶向治疗与试验入组的机会。二、核心创新性
1. 技术创新:引入智能体大语言模型(Agentic-LLM)架构
传统的大模型(如标准 ChatGPT)基于单次的提示-响应机制,无法处理极其复杂的逻辑链,且缺乏自我纠错与验证能力。本项目设计了三级智能体(3-Tier Agent)迭代工作流:Agent 1 负责通读全文定位并抽取包含压力值的文本段;Agent 2 负责利用正则模式自动协调自由文本中五花八门的术语和汇报格式;Agent 3 负责自动将提取结果与原始病程记录进行交叉对比,实现自我纠错。这种拥有记忆、可自主规划、自我验证的架构,是医疗 NLP 领域的重大技术升级。2. 算法创新:用机器学习打破经典经验公式的瓶颈
经典的 mPAP 估算公式大多基于 20 到 90 例极小样本量的队列推导,在面对真实世界复杂患者时,均方误差高达 13 到 86 mmHg,临床实用性极差。本项目利用 1.7 万例大样本真实世界 RHC 数据库,通过线性与多项式回归的机器学习筛选,拟合出了偏差最低(偏差为 -0.1 mmHg)、在全压力谱系下极其稳健的插补公式。3. 临床应用创新:AI 提取与 ML 插补的闭环决策支持工具
传统医疗 AI 往往只能抽取数据或只能预测诊断,而本项目将 LLM 数据清洗与 ML 临床预测无缝结合。该工具不仅能从杂乱的非结构化文本中提炼结构化数据,还能在关键数据缺失时自动进行高质量插补并给出诊断建议。这为未来在 EHR 系统中部署床旁自动预警系统提供了一条极具成本效益、易于推广的全新路径。
基本
文件
流程
错误
SQL
调试
- 请求信息 : 2026-06-06 08:09:31 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/713497.html
- 运行时间 : 0.089182s [ 吞吐率:11.21req/s ] 内存消耗:4,828.48kb 文件加载:145
- 缓存信息 : 0 reads,0 writes
- 会话信息 : SESSION_ID=8b25816ddb17d561dd98513c76f703b1
- CONNECT:[ UseTime:0.000865s ] mysql:host=127.0.0.1;port=3306;dbname=wenku;charset=utf8mb4
- SHOW FULL COLUMNS FROM `fenlei` [ RunTime:0.000972s ]
- SELECT * FROM `fenlei` WHERE `fid` = 0 [ RunTime:0.000320s ]
- SELECT * FROM `fenlei` WHERE `fid` = 63 [ RunTime:0.000285s ]
- SHOW FULL COLUMNS FROM `set` [ RunTime:0.000484s ]
- SELECT * FROM `set` [ RunTime:0.000214s ]
- SHOW FULL COLUMNS FROM `article` [ RunTime:0.000535s ]
- SELECT * FROM `article` WHERE `id` = 713497 LIMIT 1 [ RunTime:0.000433s ]
- UPDATE `article` SET `lasttime` = 1780704571 WHERE `id` = 713497 [ RunTime:0.004063s ]
- SELECT * FROM `fenlei` WHERE `id` = 64 LIMIT 1 [ RunTime:0.000294s ]
- SELECT * FROM `article` WHERE `id` < 713497 ORDER BY `id` DESC LIMIT 1 [ RunTime:0.000526s ]
- SELECT * FROM `article` WHERE `id` > 713497 ORDER BY `id` ASC LIMIT 1 [ RunTime:0.000396s ]
- SELECT * FROM `article` WHERE `id` < 713497 ORDER BY `id` DESC LIMIT 10 [ RunTime:0.000876s ]
- SELECT * FROM `article` WHERE `id` < 713497 ORDER BY `id` DESC LIMIT 10,10 [ RunTime:0.000722s ]
- SELECT * FROM `article` WHERE `id` < 713497 ORDER BY `id` DESC LIMIT 20,10 [ RunTime:0.001119s ]

0.090965s

 夜雨聆风
夜雨聆风