 夜雨聆风
夜雨聆风当AI学会"通关"而不只是"答题"
去年底我帮一个客户团队调Agent架构,他们的场景是这样的:AI需要登录内部系统、找到指定合同、提取关键条款、跟合规数据库做交叉核验、生成摘要、最后把结果邮件发给律师。单拆每一步,模型表现都不错。但串起来跑,成功率掉到了让人尴尬的水平。
2026年6月3日,AWS在SageMaker AI上发布了Multi-turn RL——多轮强化学习。看完技术文档的时候我意识到,这可能是我见过的第一个认真回答"怎么让Agent在多步骤任务中不崩"这个问题的工业级方案。
单步训练造出来的模型,天生不擅长"连续作战"

先说清楚问题出在哪。
过去两年企业部署AI Agent,几乎都撞过同一堵墙:单步任务表现优秀,多步任务开始崩溃。让模型写一份合同摘要,没问题。让它完成一个包含七八个步骤的完整工作流,各种奇怪的失败就冒出来了——前面几步做得好好的,突然在第五步跑偏,或者到最后一步莫名其妙地忘了前面的上下文。
原因其实不复杂。几乎所有大模型的训练,包括大多数微调方案,都是基于单轮范式的:给一个输入,期待一个输出,对了奖励,错了惩罚。模型在这个框架下学到的是"如何在单次交互中表现好",而不是"如何在一个跨越多个步骤的任务中保持连贯的策略"。
打个比方:这就像你通过做一千道围棋死活题来训练一个棋手。他每道题都能做对,但让他下一盘完整的棋,他不知道怎么把每一步串成一个整体的战略。
Multi-turn RL试图修正的,就是这个训练范式和实际使用场景之间的错位。
AWS技术文档里有一句话说得很直白:训练模型的依据是"Agent在整个任务中做出的完整决策序列",而不是某一步的对错。
这个设计带来一个很有意思的效果:如果Agent在第三步做了一个次优选择,但最终还是完成了任务——它仍然能得到正向奖励,甚至可能因此学到了一条更灵活的路径。反过来,如果Agent在第七步失败了,即使前六步都很漂亮——惩罚反映的是整个策略的问题,而不仅仅是第七步本身。
这更接近人类学习复杂技能的方式。你学开车不是学"在这个路口应该打多少度方向盘",而是学"如何把从A到B的整个驾驶过程处理好"。
三个设计决策,暴露了AWS的真实意图

坦白而言,RL训练本身不是新东西。OpenAI、DeepMind早就在用。但AWS这次做的几个架构选择,让我觉得他们想清楚了企业客户真正需要什么。
第一,完全无服务器,按Token付费。
这个细节比听起来重要得多。RL训练传统上是极度计算密集的,需要长时间运行的GPU集群,固定成本高到只有头部AI实验室才玩得起。AWS把它做成了无服务器模式——你不需要预置任何基础设施,用多少Token付多少钱。
这直接把门槛从"你需要一个专门的ML infra团队"降到了"你有一个AWS账户就行"。我第一次看到这个定价模式的时候就想,这是要把Agent RL训练变成像调用API一样普通的事情。
第二,可以连接你自己的真实业务环境。
这是我觉得最聪明的设计。Multi-turn RL不是在一个预设的沙盒里训练——它支持直接连接到你的生产系统:Amazon Bedrock AgentCore Runtime、EKS、EC2、Fargate,或者任何你自己跑Agent的框架。
为什么这很重要?因为一个需要操作CRM、查询合规数据库、调用内部API的企业Agent,如果在模拟环境里训练,它学到的策略跟真实环境之间总有gap。现在你可以让它在真实的API调用链路中训练。这个差别,对于追求生产可靠性的企业来说,是质的变化。
第三,完整的训练闭环加MLflow追踪。
SageMaker管理从rollout编排到轨迹收集、模型训练、检查点管理的整个循环。内置MLflow让你可以审查每一个Agent轨迹——它怎么"思考"的,每一步选了什么工具,在哪里出错了,最终拿到什么奖励。
说到这里,做过企业AI落地的人都知道:可解释性在很多场景下比性能还重要。你需要能跟合规团队解释"这个Agent为什么这样做",才能拿到上线的许可。这个可观察性设计,显然是奔着企业生产环境去的。
"小而专"的经济学正在成立
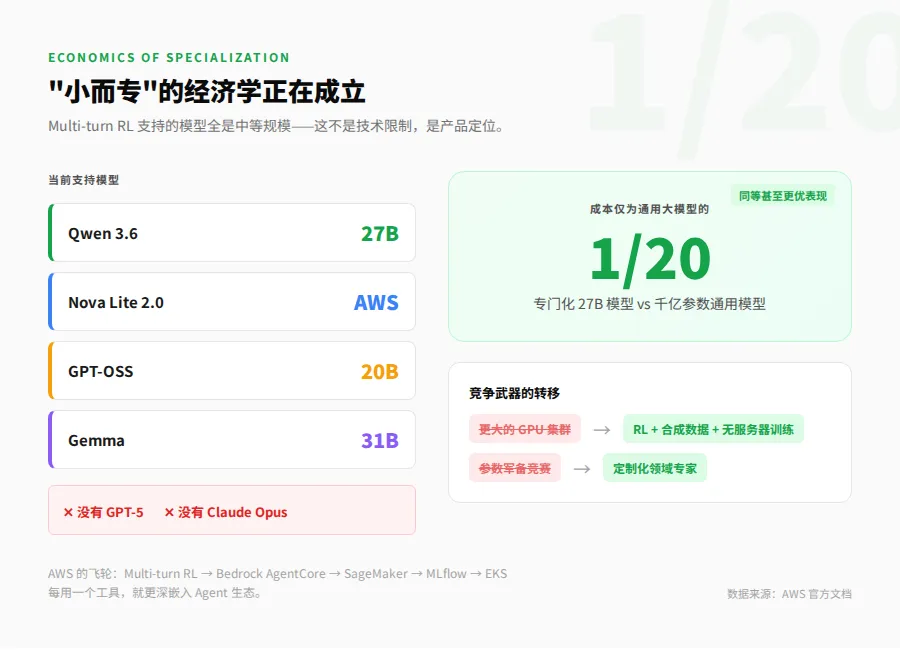
当前Multi-turn RL支持的模型列表很有意思:Qwen 3.6 27B、Nova Lite 2.0(AWS自家的)、GPT-OSS-20B、Gemma 31B。
注意,全是中等规模的模型。没有GPT-5,没有Claude Opus。
这不是技术限制,这是一个刻意的产品定位。AWS官方的说法是:帮你把更小、更低成本的模型专门化,以匹配或超过更大通用模型在你目标任务上的准确度。
翻译成大白话:你不需要为每个业务场景都用最贵的前沿模型。一个专门为你的销售流程训练过的27B模型,在你的任务上可能比通用的千亿参数模型做得更好,成本可能只有二十分之一。
我觉得这背后有一个更大的趋势正在浮现。通用大模型在训练数据和参数规模上的军备竞赛,可能正在让位给另一场竞争:谁能更高效地把通用模型定制成领域专家。这场竞争的武器不是更大的GPU集群,而是RL、合成数据、以及像Multi-turn RL这样的无服务器训练基础设施。
对企业来说,这意味着AI部署的成本曲线可能要出现拐点了。当中小企业可以用无服务器RL在自己的业务环境中微调一个20-30B的模型,使用顶级大模型的边际优势就会持续下降。这对大模型厂商的定价是压力,对企业的AI预算是好消息。
当然,AWS的意图也很透明。Multi-turn RL跟Bedrock AgentCore、SageMaker Studio、MLflow、EKS的深度集成,不是巧合,是飞轮策略。每用一个工具,你就更深地嵌入AWS的Agent生态。这个套路不新鲜,但确实有效。
多步骤可靠性,终于有了工业级解法

回到开头那个法律科技团队的问题。
当AI开始学会"通关"而不只是"答题",企业AI落地中最顽固的技术障碍——多步骤任务的可靠性——开始有了正经的解法。这个解法来自强化学习,来自无服务器基础设施,来自把训练环境直接接入真实业务系统的能力。
有意思的是,AWS在同一天还发布了Anthropic Partner Network。一个解决"谁来帮企业落地AI",一个解决"怎么让AI在企业任务中真的好用"。两个问题都不容易,但至少现在都有人在认真回答了。
参考资料
AWS SageMaker AI Multi-turn RL文档:Amazon SageMaker AI documentation
📚 扩展阅读
📄 LangChain vs AutoGPT vs CrewAI:2026年AI Agent框架大战谁会赢?
📄 从re:Invent到虾群协作:一个架构师的 Agentic AI 认知进化之旅
📄 虾群协作:一个OpenClaw多智能体写作系统诞生的血泪史
📢 免责声明:本文基于公开数据与行业观察进行分析,不构成投资建议,文中观点仅代表作者个人判断,不代表公司观点,欢迎理性讨论。
军见| 洞见科技,洞见职场,洞见自己;科技有深度,职场有方法,管理有温度,做长期有用的内容。
点赞 +「在看」,转发给你身边有需要的朋友。收不到推送?那是因为你只订阅,却没有加星标。
