 夜雨聆风
夜雨聆风你可能遇到过这样一个尴尬场景。
你把一个线上 bug 丢给 Copilot、Cursor 或 Claude Code,说:“登录之后偶尔会跳回首页,帮我修一下。”它很快给出一段看似合理的解释:可能是 session 失效,可能是 token refresh 异常,可能是路由守卫写错了。
然后它停下来,温和地问你:“相关代码在哪个文件?”
这一刻,幻觉破了。
如果它真的理解整个项目,为什么还要你告诉它文件路径?如果企业代码库有百万行,几十个服务,几千个文件,AI 编程助手到底是在“理解代码”,还是只是在当前打开的几个文件里做自动补全?
过去一年,AI 编程领域最重要的变化之一,恰恰发生在这个问题上:大家终于不再幻想把整个代码库硬塞进上下文窗口,而是开始把代码库当成一座城市来导航。
模型不再是背诵整本电话簿的学生,而更像一个会查地图、会问路、会沿着线索追踪的侦探。
“无限上下文”为什么是个伪命题
过去的直觉很简单:上下文窗口越大,AI 越能理解大项目。
10K 不够,就上 128K;128K 不够,就上 1M;1M 还不够,就继续拉长。听起来像是解决了问题:既然代码库放不下,那就造一个更大的篮子。
但 LoCoBench 和 LoCoBench-Agent 给这个幻想泼了一盆冷水。
它们观察到,在软件工程任务里,“能放进去”不等于“能找出来”。长上下文模型即使拥有接近百万 token 的窗口,也会在真实代码库任务中出现性能衰减。原因并不神秘:上下文越长,干扰越多,关键线索越容易被淹没。
这就是代码库里的 Haystack 困境。
不是没有针,而是你把整个仓库、所有历史遗留代码、无关配置、测试样例、过期接口、重复工具函数都堆到了模型面前。模型看到的不是“更多信息”,而是一片噪声森林。
就像你要找一本书里的一句话,有人直接把整座图书馆搬到你桌上。理论上答案就在里面,现实中你只会更慢。
更反直觉的是,LoCoBench-Agent 的实验启示是:战略性探索往往比“死读书”更有效。能规划搜索路径、调用工具、逐步缩小范围的 Agent,并不一定需要读取所有文件。它需要的是找到正确的文件、正确的函数、正确的调用链。
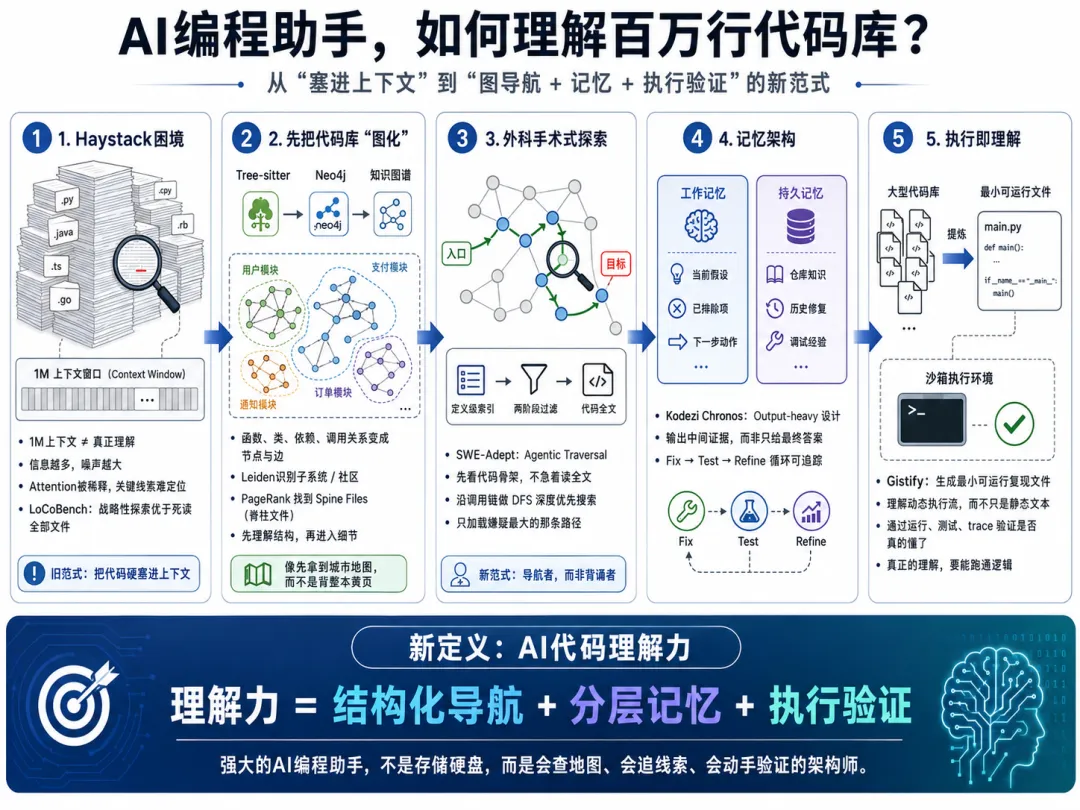
这也是 2025-2026 年 AI 编程助手范式转移的起点:理解代码库,不是扩大上下文,而是优化探索策略。
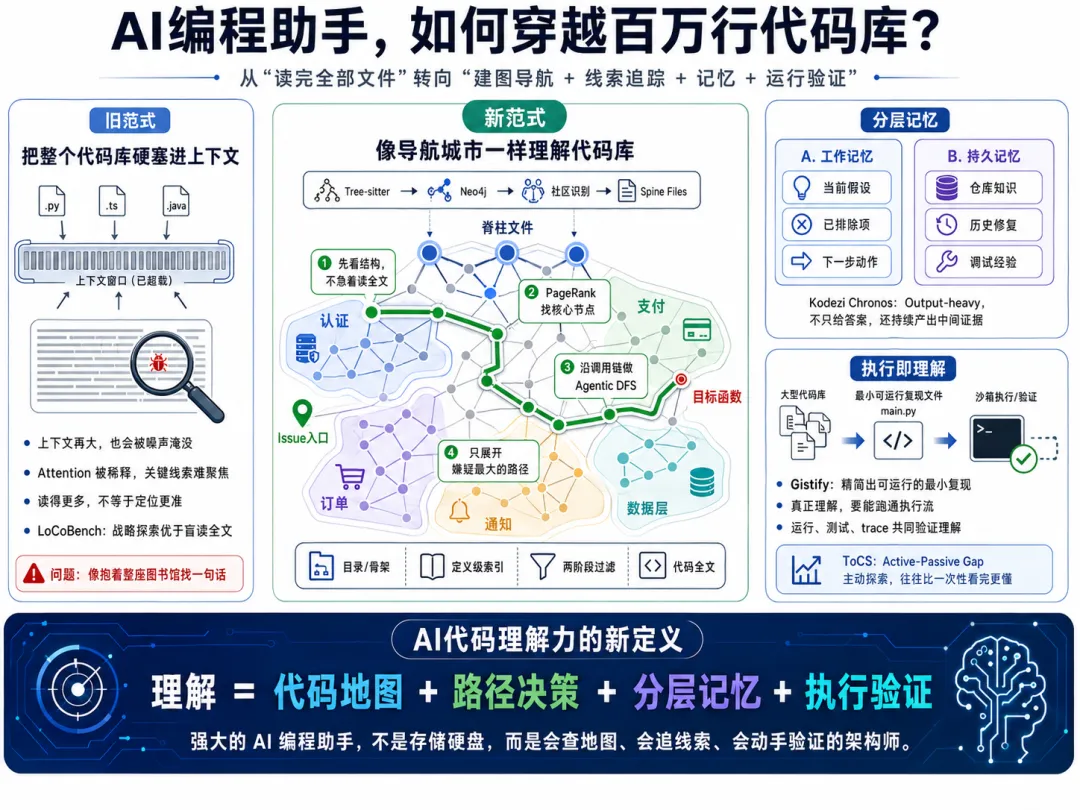
新一代 Agent 不再读代码库,而是先画地图
如果代码库是一座城市,旧式 AI 编程助手像一个外地游客,站在城市入口处拿着一本厚厚的黄页,试图从头读到尾。
新一代 Agent 更像出租车司机。它不需要背下每栋楼的每个房间,但它知道主干道在哪里,哪些路口最关键,哪个区域属于金融区,哪个区域属于老城区,A 点到 B 点应该走哪条路。
这就是图索引的价值。
以 Prometheus、Code-Lens AI 这类方案为代表,新范式会先把代码库转换成知识图谱:文件是节点,类是节点,函数是节点,调用关系、依赖关系、继承关系、文本说明都是边。静态代码不再是一堆散落的文件,而是一张可以查询、可以排序、可以遍历的城市地图。
Code-Lens AI 的做法很典型:它用 Tree-sitter 解析代码语法树,把结构化信息存入 Neo4j 图数据库,再用 Leiden 社区检测算法识别代码库中的“子系统”。这一步非常关键,因为大型仓库天然不是平的,它由认证、支付、任务调度、权限、存储、UI、测试框架等多个区域组成。
随后,PageRank 会在每个子系统里找出最重要的那几个文件。Code-Lens AI 把这些文件称为 Spine Files,也就是“脊柱文件”。
这个词很形象。
一个子系统可能有上百个文件,但真正支撑它骨架的,往往只有 5 到 6 个核心文件。它们可能不是最长的文件,也不是最近修改的文件,而是被最多模块依赖、连接最多路径、最能代表架构意图的文件。
过去 Agent 看到的是文件列表:
auth.ts、authService.ts、authUtils.ts、login.tsx、session.ts、token.ts、middleware.ts……
现在 Agent 看到的是结构:
“认证子系统的中心是 session 管理;token 刷新依赖 auth middleware;登录页面只是入口,真正的问题更可能在 refresh pipeline。”
这就是从 grep 到 graph 的跃迁。
grep 只能告诉你哪里出现了某个词。图能告诉你哪个文件处在交通枢纽上,哪个函数是事故高发路口,改一个工具函数会影响多少调用方。
企业级代码库真正需要的不是“全文检索”,而是“结构化导航”。
SWE-Adept:像侦探一样沿着嫌疑链走
有了地图之后,Agent 还需要会走路。
SWE-Adept 提出的 Agentic Traversal,本质上就是让 Agent 进行有策略的深度优先搜索。它不急着读全文,而是先读代码骨架。
这和人类高级工程师排查 bug 的方式非常像。
一个资深开发者接到问题,不会从仓库第一个文件开始读。他会先问:入口在哪?调用链怎么走?异常从哪里抛出?最近哪些模块改过?配置有没有绕路?测试有没有覆盖?
SWE-Adept 也是这样。
它先基于定义级索引查看类、函数、接口这些“骨架信息”,而不是把文件全文丢进上下文。然后,它顺着依赖关系和调用关系做 agent-directed DFS:从最可能相关的节点出发,沿着调用链向深处探索。
探索过程中,它会不断做过滤。
第一层过滤,是判断哪些文件可能和 issue 相关。第二层过滤,是在候选文件中定位真正需要阅读的代码块。只有到最后,它才加载相关代码全文。
这个流程像外科手术,而不是地毯式轰炸。
传统方式是:“把所有疑似文件都读进来,让模型自己判断。”
Agentic Traversal 是:“先根据结构判断嫌疑人,再沿着关系链追踪,最后只打开关键证据。”
这背后有一个朴素但重要的工程原则:上下文窗口应该留给高价值信息,而不是被无关代码填满。
大模型的上下文不是硬盘,而是工作台。你不会把整个仓库的所有零件都倒在工作台上;你会把当前手术需要的几把刀、几张片子、几个关键指标放上去。
记忆架构:AI 需要的不只是上下文,而是工作记忆和持久记忆
当 Agent 开始长时间探索代码库,另一个问题出现了:它怎么记住自己已经发现了什么?
这就涉及工作记忆和持久记忆的分工。
工作记忆,是当前任务中的临时状态。比如:这次 bug 可能和 refresh token 有关;已经排除了前端路由;当前重点怀疑 sessionStore 和 authMiddleware;下一步要检查调用链里的异常分支。
持久记忆,则是跨任务、跨会话沉淀下来的代码库知识。比如:这个项目的认证模块历史上多次出现 token race condition;某个老接口虽然标注 deprecated,但仍被移动端使用;支付模块不能直接改公共 rounding 函数,因为报表系统依赖它的旧行为。
Kodezi Chronos 这类 debugging-first 架构强调的,正是这种 repository-scale memory。它不是只依赖一次性上下文,而是把代码库、历史修复、调试过程、测试反馈组织成多层记忆,再通过图检索和向量检索动态取用。
这里还有一个容易被忽略的点:调试型 Agent 往往是 output-heavy 的。
普通聊天模型倾向于少量输出、快速回答。但调试 Agent 的“输出”不是最终答案,而是中间产物:假设、证据、排除项、补丁、测试结果、失败原因、下一轮修复计划。
这看起来啰嗦,却符合调试逻辑。
因为真实的软件修复不是一次生成代码,而是一个 fix-test-refine 循环。Agent 每跑一次测试,就要把结果写回记忆;每失败一次,就要更新假设;每定位一个新调用方,就要修正代码地图。
输出密集,并不是废话多,而是为了让 Agent 的推理轨迹可追踪、可复用、可纠错。
对企业来说,这比“生成一段看似正确的代码”重要得多。因为大项目里的 bug 往往不是缺一行代码,而是缺一个被验证过的因果链。
真正的理解,不是读懂代码,而是跑通代码
静态阅读仍然有天花板。
一个 Agent 可以看懂函数签名,可以沿着调用图走,也可以找到核心文件。但它是否真的理解了动态执行流?这件事不能只靠口头解释验证。
微软的 Gistify 给出了一个很有意思的新范式:要求模型从一个完整代码库中,提炼出一个单文件、最小化、可自包含的复现程序,并且这个文件必须复现原始入口命令的输出。
这是一道很狠的题。
因为你不能只说“我理解了”。你必须证明:哪些代码是必要的,哪些依赖可以删掉,哪些状态初始化不能漏,哪些执行路径必须保留。
这就像让一个人解释一台复杂机器的工作原理,最好的考核不是让他背说明书,而是让他用最少零件重新搭一台能跑的模型机。
Gistify 的核心洞察是:代码库理解不只是结构理解,还包括执行流理解。
静态图告诉你“谁连接了谁”。运行轨迹告诉你“真正执行时谁影响了谁”。
这也是为什么沙箱执行、测试反馈、trace 采集会越来越重要。未来的 AI 编程助手不会只在代码文本上推理,它会读日志、跑测试、插桩、比较输出、缩小复现范围。它理解代码的方式,会越来越接近人类工程师处理线上事故的方式。
读代码只是侦查,执行才是审讯。
Active-Passive Gap:为什么主动探索可能比一次性看完更深
Theory of Code Space 提到的 Active-Passive Gap,给这个趋势提供了更理论化的解释。
有些模型在被动接收所有文件时,表现并不如主动探索时好。原因在于,理解大型软件不是简单的信息摄入,而是一个构建“信念地图”的过程。
人类读代码也是这样。
你第一次进入陌生项目,不会因为拿到所有文件就立刻理解架构。你会形成假设:这个模块可能负责权限;这个类可能是入口;这个配置可能决定运行模式。然后你通过阅读、搜索、运行、测试不断修正假设。
主动探索的价值,就在于每一步都会改变下一步的问题。
如果模型只被动接收所有文件,它缺少这种“带着问题看证据”的过程。它看得很多,但不一定知道什么重要。
这解释了为什么未来的 AI 编程能力,不会只取决于底座模型有多大,而会越来越取决于 Agent Harness 的设计:工具怎么暴露,索引怎么构建,记忆怎么压缩,探索策略怎么决策,执行反馈怎么写回。
模型是大脑,但 Agent 架构是神经系统。
新定义:AI 理解代码库,不是存储,而是导航
所以,AI 编程助手到底如何理解百万行代码库?
答案不是“把百万行代码读完”。
答案是:它把代码库变成可导航的空间。
它用 Tree-sitter 和语法索引把文本变成结构;用 Neo4j、Leiden、PageRank 找到子系统和脊柱文件;用 Agentic DFS 沿着调用链追踪嫌疑路径;用工作记忆保存当前调查状态;用持久记忆沉淀历史经验;用测试、沙箱和最小复现验证自己是否真的理解了执行流。
这套新范式里,AI 编程助手不再像一个无限容量的硬盘,而更像一个架构师。
硬盘的能力是保存所有东西。架构师的能力是知道什么重要、从哪里切入、哪些路径不能碰、哪个改动会震动整栋楼。
百万行代码库的难点,从来不是“信息不够”,而是“结构太多、路径太深、噪声太大”。
真正强的 AI 编程 Agent,也不是那个能吞下最多上下文的模型,而是那个能在复杂系统里少走弯路、快速定位关键路径、用执行结果验证判断的导航者。
未来的代码助手,会越来越不像补全工具,越来越像一个带着地图、记忆和调试仪器的资深工程师。
它不需要记住城市里的每一块砖。
它只需要知道,火警响起时,该从哪条街冲进去。
