 夜雨聆风
夜雨聆风
Benchling AI白皮书:专用研发智能体与企业通用AI助手的应用差异辨析
1. 一段话总结
这份 Benchling AI 白皮书核心辨析了专用研发 R&D 智能体与企业通用 AI 助手的应用差异,指出生命科学研发领域存在研发数据割裂、知识固化痛点,衍生出重复实验、决策延迟、机构知识流失等问题,企业 AI 助手因无研发数据模型认知、仅依赖静态文本数据、溯源可信度不足三大短板无法适配科研需求;Benchling AI 专用研发智能体依托科学数据模型架构,具备结构化数据跨维度推理、溯源深度链接、科研专业适配、原生生成平台实体、无工作场景切换五大独有能力,有效规避科研场景AI 幻觉、溯源断层、落地最后一公里难题,同时以MCP 协议、开放 API、互操作性为三大支柱打造开放生态,明确二者可共存使用,且研发数据治理是企业 AI 战略的核心基础,专用智能体更契合合规科研全流程落地需求。
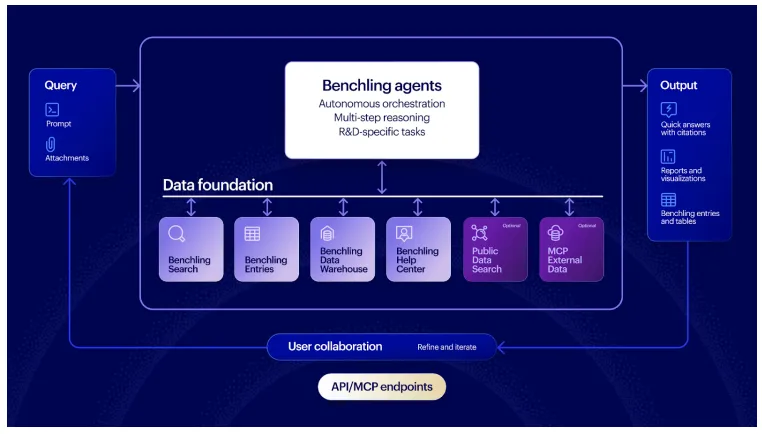
Benchling智能代理如何处理查询请求。与通用大语言模型不同,智能代理并非仅将你的提示词传递给单一模型。它们会制定执行方案、调取实时研发数据进行查询,并按照任务所需格式返回结果。
2. 思维导图
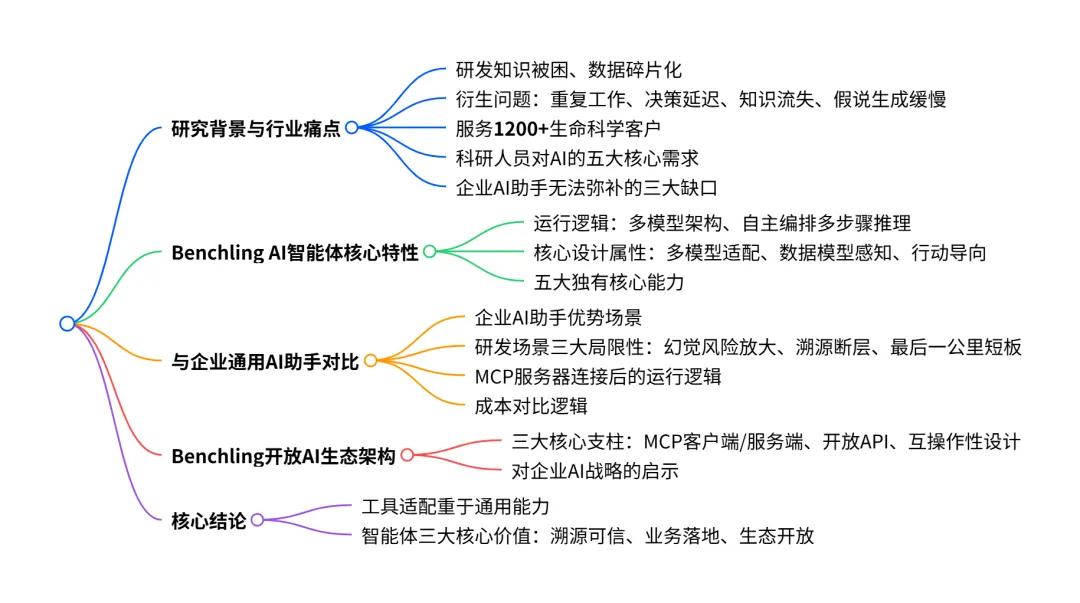
3. 详细总结
一、执行摘要核心
1.核心疑问:研发团队已有企业 AI 助手且可通过MCP 协议对接 Benchling,为何仍需专用Benchling AI 研发智能体?
2.核心结论:企业 AI 助手具备宽泛科研知识,适合文献综述、通用科学问答;Benchling AI 智能体可深度理解企业自有研发结构化数据,能追溯从实验假设到结果全链路科研记录,这是通用 AI 无法实现的。
3.共存定位:白皮书并非否定企业 AI 助手,二者可搭配使用,MCP 协议可实现两类工具互联互通。
4.三类接入方式能力差异(表格)
二、研发行业核心痛点:R&D 知识被禁锢
1.数据价值浪费:单个药物研发项目可产生数千次实验、数百次检测运行,海量结构化数据无法快速复用。
2.数据割裂的连锁代价:
○重复劳动:科研人员重复开展已有成败记录的实验
○决策延迟:跨实验数据分析耗时从 1 小时拉长至 1 周
○机构知识流失:员工离职带走实验决策背景与试错经验
○假说生成变慢:耗费大量时间整理数据,而非分析规划
3.科研人员对 AI 的真实需求:快速跨实验答疑、智能生成实验文档、识别数据异常规律、辅助科研假说生成、减少人工文档录入负担。
4.企业 AI 助手无法填补的三大缺口
○语境缺口:不懂企业自研的研发数据模型、字段阈值、批次关联关系,答案泛化甚至误导
○连通性缺口:仅能处理导出的静态数据快照,无法调用 Benchling 实时结构化数据与实体关联关系
○可信度缺口:无法溯源原始数据源,不符合GxP、21 CFR Part 11合规审计要求
三、Benchling AI 智能体差异化优势
1.底层架构:专为科研工作流定制智能体框架,结合 LLM + 科学语境层 + 结构化数据查询工具 + 多任务编排系统,基于真实科研记录生成答案,而非通用文本推理。
2.运行机制:接收科研指令后,自主编排多步骤推理,联动平台搜索、实验记录、数据仓库、公共科研数据,按需输出答案、报告、可视化图表或平台实体,全程支持科研人员迭代优化。
3.关键设计属性
○多模型设计:不按需分配最优模型,不同子任务匹配专属大模型,性能优于单一 LLM
○数据模型感知:可识别序列、实验、批次、笔记等实体关联关系,实现跨实验大规模数据合成
○行动导向型:不止问答,可直接在平台生成实验记录、结构化表格,需人工审核后纳入科研档案
4.五大独有交付能力
a.支持结构化研发数据推理,不止文档文本解读,可关联底层数据库、筛选阈值、关联批次数据
b.深度链接与语境导航,答案内嵌原始实体溯源链接,可一键核验,满足合规审计
c.保障科研专业性与质量,优先采信 PubMed 等权威文献、自带引用架构、适配科研专业提问逻辑
d.可生成 Benchling 原生实体而非纯文本,直接创建实验笔记、模板、数据表,保留审计追踪
e.无场景切换,内嵌科研工作平台,无需跳转外部工具,持续积累知识库提升 AI 精度
四、与企业通用 AI 助手详细对比
1.企业 AI 助手优势:擅长文献总结、科学概念解读、通用科研问答,无需调用企业专属实验数据的场景适配性强。
2.研发场景三大天花板短板:
○AI 幻觉风险放大:药物研发中易生成虚假实验数值、混淆相似实验载体,造成研发路线误判
○溯源断层:缺少数据引用、SQL 查询记录, regulated 环境下无法审计,不能用于正式科研决策
○最后一公里落地难:仅能文字建议,无法直接生成平台实验记录和结构化数据表,仍需人工复制粘贴。
3.MCP 服务器对接逻辑:企业 AI 通过 MCP 连接 Benchling 时,底层仍调用 Benchling 自研智能体,并非通用模型直接处理原始数据。
4.成本逻辑:通过外部 AI 助手调用 MCP 与平台原生使用智能体,计费消耗一致;直接调用 API 无智能体计费,但需企业自行投入大量工程开发复刻同等能力。
五、Benchling 开放 AI 生态架构
1.三大核心支柱:
○MCP 客户端 / 服务端:打通 Benchling 数据与任意 AI 工作流,可接入外部 AI 工具,也可引入外部科研数据至 Benchling AI
○开放 API:全平台数据开放可控,企业可自由提取、流转、定制开发,数据所有权归客户
○互操作性设计:不排他垄断,支持与各类 LLM、第三方智能体协同工作
2.AI 战略启示:AI 战略与研发数据战略必须一体化,结构化治理 Benchling 研发数据,可提升所有对接 AI 工具的能力,数据基建就是 AI 基建。
六、最终结论
1.通用能力≠场景适配性,企业 AI 不懂专属研发数据模型,无法替代专用智能体。
2.Benchling 智能体三大核心价值:数据溯源可信、可直接落地生成科研实体、生态开放不绑定厂商。
3.科研 AI 选型原则:按需匹配场景,通用 AI 做基础科普文献工作,专用研发智能体处理企业自有结构化实验数据与合规科研流程。
4. 关键问题与答案
问题 1:Benchling AI 专用研发智能体和企业通用 AI 助手的核心本质区别是什么?
答案:企业通用 AI 助手拥有宽泛的生物、化学、药物研发通识知识,适合通用科学问答、文献整理、科普解释等基础任务,但不理解企业专属的研发数据模型、实体关联关系与合规要求;Benchling AI 智能体是专为科研结构化数据打造,可深度解析 Benchling 平台内序列、实验、批次、笔记等关联数据,实现跨实验推理、溯源审计、原生生成科研实体,懂企业自有科研数据与业务流程,适配研发全流程合规落地。
问题 2:企业通用 AI 助手在生命科学 R&D 研发场景中,无法突破的核心局限性有哪些?
答案:一是AI 幻觉风险被放大,易生成虚假实验数据、混淆科研载体,误导药物研发方向,造成高额研发成本浪费;二是溯源断层,输出结果无法关联原始实验记录、无明确数据引用,无法满足 GxP、21 CFR Part 11 等合规审计要求;三是落地最后一公里缺失,仅能输出文字建议,无法直接创建平台实验笔记、结构化数据表,仍需科研人员手动搬运内容,无法融入科研工作流。
问题 3:企业通过 MCP 服务器将通用 AI 助手对接 Benchling 后,实际效果和成本有哪些关键点?
答案:①效果层面:外部 AI 看似对接了 Benchling 数据,底层实际调用的仍是 Benchling 自研 AI 智能体,具备同等科研推理能力,但会损失深度链接溯源、平台实体创建、界面无缝导航等完整功能;②成本层面:通过 MCP 调用与平台原生使用智能体的计费消耗完全一致,并无成本优势;③替代方案:若直接调用 Benchling 原生 API,虽无智能体计费,但需企业投入大量研发工程,自行复刻智能体的推理、溯源、科研适配能力,长期维护成本更高。

生物智能:在生物先进产业场景中构建“状态感知-实时认知-自主决策-精准执行-学习提升”的生物科学智能(Biology_and_AI);实现生物产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。

生物产业+物理AI=生物智能
产业智能官:Science_and_AI
加入知识星球“生物智能研究院”:生物产业OT技术(自动化+机器人+工艺+精益)和新一代IT技术(云计算+物联网+区块链+大数据+人工智能)深度融合,在场景中构建“状态感知-实时认知-自主决策-精准执行-学习提升”的生物科学智能;实现生物产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:Science_and_AI)发表的文章,除非确实无法确认,我们都会注明作者和来源,涉权请联系协商解决,联系、投稿邮箱:wolongzy@qq.com
