 夜雨聆风
夜雨聆风这个问题,Stanford University 和 Lambda Labs 的作者在论文《Personal AI, On Personal Devices》中,给了一个很直接的答案:个人 AI 不一定非要住在云上。它可以跑在你的设备上,而且在 8 个个人 AI 基准里,最好端侧方案只比最强云模型低 3.2 个百分点,同时把边际 API 成本降到约 1/800,端到端延迟降到约 1/4。
听起来有点反直觉。
过去两年,我们默认了一件事:聪明的 AI 必须在云端。你问它邮件、日程、代码、文件、隐私数据,它就把这些东西发给远处的一台机器。
方便吗?方便。
但问题也来了:贵,不离线,不可控,还要把最私人的上下文交出去。
OpenJarvis 想说一句:别急。今天的端侧模型,也许已经不只是“改改语气、补补句子”的玩具了。
不是把云模型搬下来,而是把系统拆开
为什么直接替换会失败?
论文先做了一个很扎心的实验。
把现有个人 AI 系统里的云模型,比如 Claude Opus 4.6,直接换成端侧模型 Qwen3.5-9B,会怎样?
答案是:准确率直接掉 25–39 个百分点。
这说明一件事:问题不只是模型小了。
真正的问题是,今天很多 Agent 系统是“整坨设计”的。提示词、工具描述、记忆配置、推理运行时,全都围着某个云模型调出来。你把模型一换,就像把赛车发动机换成电瓶车电机,方向盘还在,轮子还在,但整套传动不匹配了。
所以 OpenJarvis 没有说“我有一个更强的小模型”。
它说的是:个人 AI 应该被拆成可以优化的系统。
五个原语,才是关键
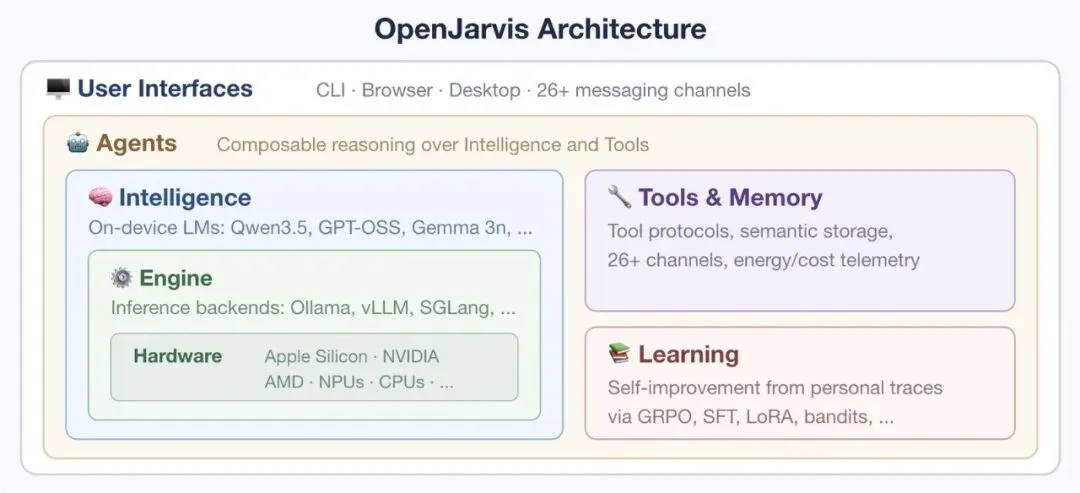
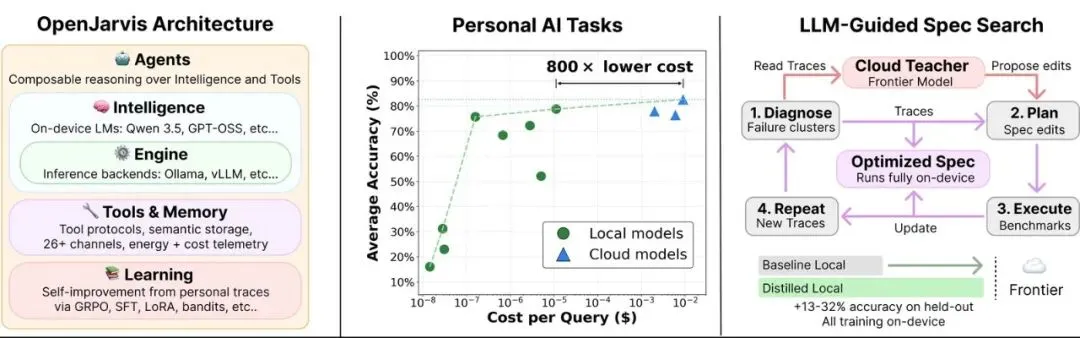
OpenJarvis 把个人 AI 拆成 5 个可组合原语:
- Intelligence:模型、权重、生成参数、量化格式。
- Engine:推理引擎,比如 Ollama、vLLM、SGLang、llama.cpp。
- Agents:推理循环,比如 ReAct、CodeAct、工具调用策略。
- Tools & Memory:外部工具、数据连接器、记忆系统、MCP 接口。
- Learning:从执行轨迹中学习,反过来修改前面那些配置。
这就像开饭店。
过去是一个大厨包办一切。现在是把菜单、厨具、后厨流程、供应链、复盘机制都拆出来。哪里不好吃,不是只骂厨师,而是看食材、锅、流程、火候到底哪个环节出了问题。
这才是 Agent 从 demo 走向日常系统的关键。
端侧 AI 最大的问题,不是智商,是适配
云模型为什么强?
云模型强,当然因为参数、数据、算力都大。
但论文里更有意思的点是:云模型还强在“系统被它驯服过”。
OpenClaw、Hermes Agent 这类个人 AI 栈,很多提示词、工具接口、记忆策略,本来就是围绕云模型设计的。云模型能容忍模糊工具描述,能扛住复杂上下文,能从不完美流程里猜出你的意思。
端侧模型没这么豪横。
它更像一个聪明但新来的实习生。你不能只说“把这个事处理了”。你要告诉它工具怎么用,信息去哪找,失败怎么重试,哪些步骤不能跳。
所以,端侧 AI 要成功,靠的不是一句“本地部署万岁”。
靠的是 Spec。
Spec 是个人 AI 的说明书
OpenJarvis 用一个声明式配置对象,把五个原语写成一份 Spec。
这份 Spec 可以版本化,可以分享,可以评测,也可以被优化器反复修改。
举个例子:同一个 Agent 逻辑和工具配置,可以分别跑在 Mac Mini、工作站、DGX Spark 上;同一个模型,也可以换不同推理引擎;同一个任务失败了,系统可以判断是模型理解错了、工具描述不清、记忆没取到,还是运行时太慢。
这一步很重要。
因为只要系统变成可描述的,才会变成可优化的。今天很多 Agent 不稳定,不是因为“AI 不行”,而是因为我们连系统哪里坏了都说不清。
说不清,就改不好。
真正厉害的是:让云模型教本地模型
LLM-guided Spec Search
OpenJarvis 最有传播价值的创新,是 LLM-guided spec search。
它不是让云模型永远帮你干活。
它是让云模型当一次老师。
流程大概是这样:本地 Agent 先跑任务,留下执行轨迹;云端强模型读取这些轨迹,诊断失败原因;然后它提出修改建议,可能改模型配置,可能改工具描述,可能改 Agent 流程,可能改推理引擎参数。
但每个修改都要过一道门:gate。
只有当这个修改能修复目标失败,并且不会让其他任务明显退化时,才被接受。默认容忍退化是 1%。
云模型只在搜索和教学阶段参与。优化后的 Spec,在推理阶段完全跑在设备端。
这就像请一个名师给你改学习方法。名师不替你考试,只帮你发现:你不是不会数学,你是审题、草稿、时间分配三件事一起坏了。
结果有多夸张?
3.2 个百分点,800 倍成本差
论文给出的核心结果很直接。
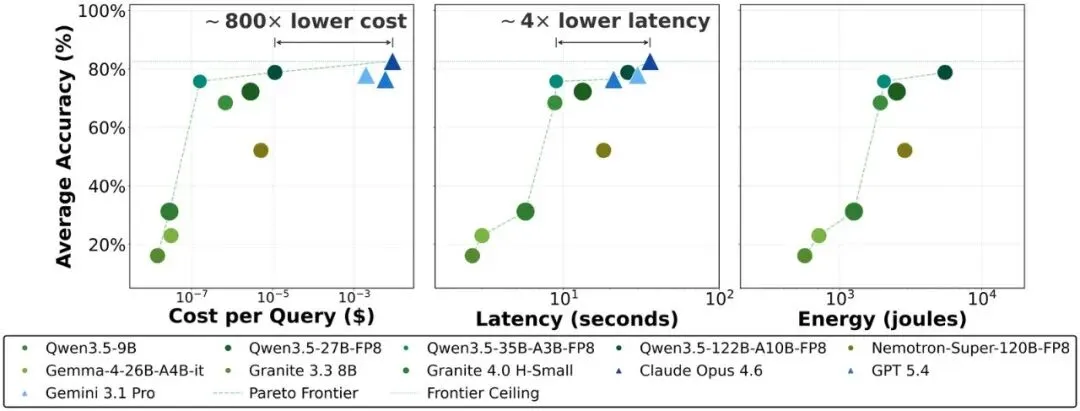
最好的单一本地配置 Qwen3.5-122B,平均准确率达到 80.3%;云端基线 Claude Opus 4.6 是 83.5%。差距只有 3.2 个百分点。
但成本差距不是 3.2%。
是约 800 倍。
论文按边际 API 成本计算,本地方案每次查询大约是千分之一美分量级,而 Claude Opus 4.6 约 0.009 美元/次。在完整 Agent 工作流里,本地配置还实现了约 4 倍端到端延迟优势。
当然,这不是说所有场景本地都赢。
论文也承认,单轮短 prompt 有时云服务的首 token 优化更强。但一旦进入个人 AI 的真实工作流——查文件、调工具、跑代码、读网页、写报告——网络、API、工具往返和系统调度都会变成成本。
这时候,本地就开始有优势了。
搜索优化带来 13–32 个百分点提升
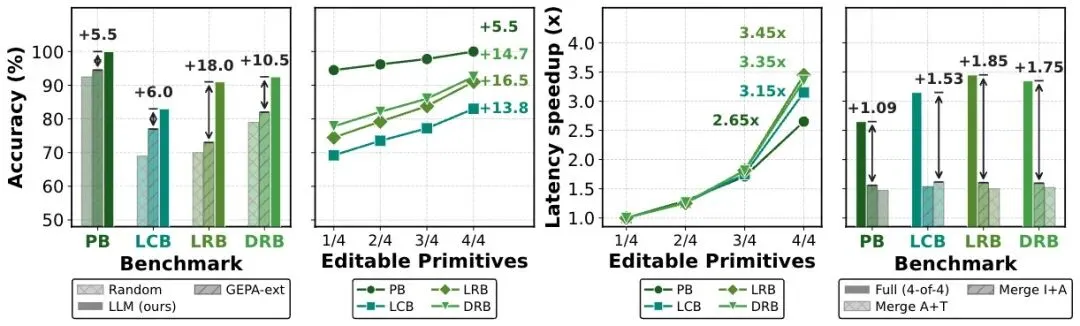
更关键的是,LLM-guided spec search 不是小修小补。
在全套 8 个 benchmark 上,不同学生模型平均提升 13.1 到 31.5 个百分点。
对于 Qwen3.5-9B,搜索优化后的 Spec 在三个任务上达到:
- PinchBench:100.0%
- LiveCodeBench:83.0%
- LiveResearchBench:91.0%
这组数字说明,很多端侧模型不是“没有能力”,而是缺一套能把能力释放出来的系统。
就像一个新人,不是不会干活,是没人给他流程、工具和复盘。
这篇论文真正的信号:个人 AI 会重新本地化
云端不会消失,但角色会变
我觉得这篇论文最值得写,不是因为它又刷了一个榜。
而是它给出了一个趋势:云模型会从执行者,变成教练。
过去,所有问题都交给云端做。未来,云端强模型可能更多用于搜索、蒸馏、诊断、优化和迁移;日常执行则尽量回到本地。
这对个人 AI 很关键。
因为个人 AI 和普通聊天机器人不一样。它要读你的邮件、日程、文件、聊天记录、浏览历史。它越有用,就越贴近隐私。越贴近隐私,就越不能无脑云端化。
所以端侧不是怀旧。
端侧是个人 AI 真正进入生活后的必然选择。
对开发者的启发
如果你今天在做 Agent,OpenJarvis 给的启发很朴素:别只卷模型,先把系统拆清楚。
到底是模型不行?工具描述不行?记忆召回不行?Agent 控制流不行?推理引擎不行?
这些问题不拆开,就只能靠玄学调 prompt。
而玄学调 prompt,是 Agent 工程里最贵的迷信。
真正能长期复利的,是把系统做成可测、可诊断、可替换、可学习。
最后说句实话
OpenJarvis 不是说“本地模型已经全面打败云模型”。
没有。
它说的是更重要的一句话:个人 AI 的未来,不应该只有云端一条路。
云端负责探索边界,本地负责日常执行;云端负责当老师,本地负责干活;云端负责大规模智能,本地负责私人上下文。
这套分工一旦成立,个人 AI 的商业逻辑也会变。
今天你为每次调用付钱。明天你可能为一个持续进化的本地系统付钱。
今天你租智能。明天你拥有智能。
这才是这篇论文最狠的地方。
不是模型多强。
是它把一个问题重新摆上桌面:你的个人 AI,凭什么一定要住在别人家的服务器上?
论文:Personal AI, On Personal Devices
链接:https://arxiv.org/abs/2605.17172
代码:https://github.com/openjarvis/openjarvis
官网:https://open-jarvis.github.io/OpenJarvis/
