 夜雨聆风
夜雨聆风当你花几百万买回来一堆 A100、H100 显卡,搭起了大模型训练集群,却发现训练速度始终上不去 —— 明明显卡利用率已经拉满,可多卡之间的梯度同步却总是慢半拍?
很多人第一反应是 “显卡不够”,于是继续加卡,结果发现集群越大,这个瓶颈越明显。
问题到底出在哪?
答案很简单:你可能还在用普通的以太网交换机,跑着传统的 TCP/IP 协议。在 AI 训练的海量数据交互面前,这套几十年前的 “老网络”,早就已经力不从心了。
而真正能释放 AI 算力的,是一项叫做RoCE的网络技术。今天我们就来扒一扒,这个被称为 “智算集群标配” 的技术,到底给网络做了哪些升级,又要花多少钱才能用上?
普通网络跑 AI,到底卡在哪了?
要理解 RoCE 的价值,我们得先搞明白,普通的以太网网络,在 AI 场景下到底差在哪。
传统的 TCP/IP 网络,我们用了几十年,它的工作流程是这样的:
当服务器 A 要给服务器 B 发数据的时候:
1. 应用把数据交给操作系统内核 2. 内核处理 TCP/IP 协议,打包、校验 3. 把数据拷贝到网卡的缓冲区 4. 网卡把数据发出去 5. 接收端反过来,网卡把数据拷贝到内核,内核再拷贝到应用的内存里
整个过程,光是数据拷贝就有4 次,而且每一步都要 CPU 来参与处理协议栈。
这在平时上网、存文件的时候没问题,可到了 AI 训练场景,这就成了致命的瓶颈:
• 延迟太高:大模型训练的时候,成千上百张 GPU 要频繁同步梯度,每一次同步都要等网络传输。TCP/IP 的延迟动辄几十微秒,累积起来,训练时间直接翻倍。 • CPU 占用爆炸:为了处理网络协议,CPU 要拿出 30% 甚至更多的性能来跑网络,本来这些 CPU 可以用来做数据预处理,现在全浪费在网络上了。 • 丢包和抖动:普通以太网是 “尽力而为” 的网络,丢包了就重传,这会导致网络延迟忽高忽低,GPU 经常要停下来等数据,利用率上不去。
举个例子,训练一个 70B 参数的大模型,用普通的 TCP/IP 网络,可能需要上百天才能训完,而用 RoCE 网络,时间直接砍半,这就是差距。
RoCE 到底是什么?它做了什么升级?
RoCE 的全称是 RDMA over Converged Ethernet,翻译过来就是 “融合以太网上的远程直接内存访问”。
听起来很绕?其实用一句话就能说清楚:它让网卡直接读写另一台机器的内存,全程不需要 CPU 和操作系统内核插手。
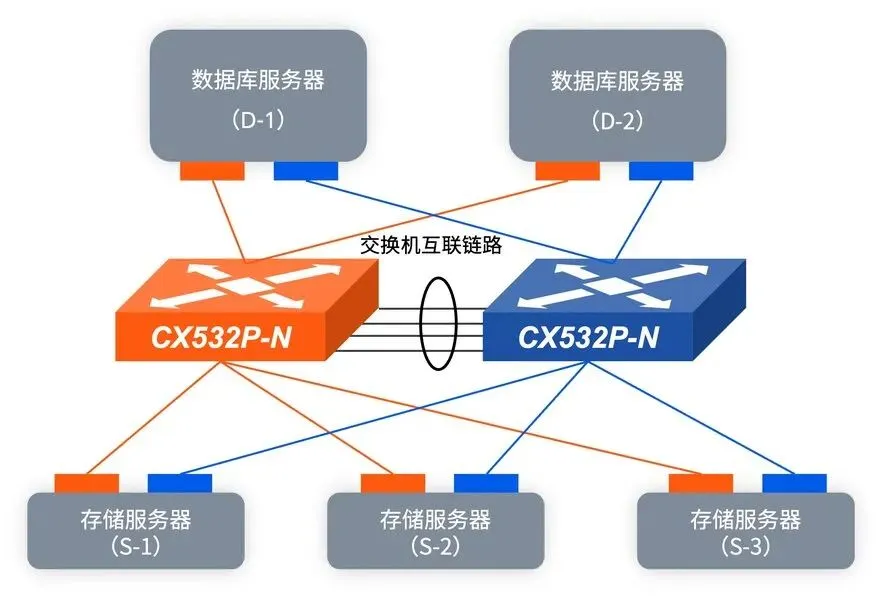
RoCE 网络架构,服务器之间可以直接通过网卡实现内存级互通
就像原来你要给邻居送东西,得先把东西交给物业,物业再交给保安,保安再送到邻居家,邻居还要下楼去拿 —— 这就是 TCP/IP,中间绕了好多人,还要每个人都签字确认。
而 RoCE 呢?你直接拿着钥匙打开邻居家的门,把东西放进他家的柜子里,转身就走 —— 全程不需要任何人帮忙,也不需要邻居醒过来签字。
这就是所谓的 \\“零拷贝”和“内核旁路”\\,数据从一块内存直接到另一块内存,没有中间的拷贝,也没有 CPU 的参与。
从 v1 到 v2,RoCE 的进化之路
RoCE 并不是一开始就完美的,它也经历了两代升级:
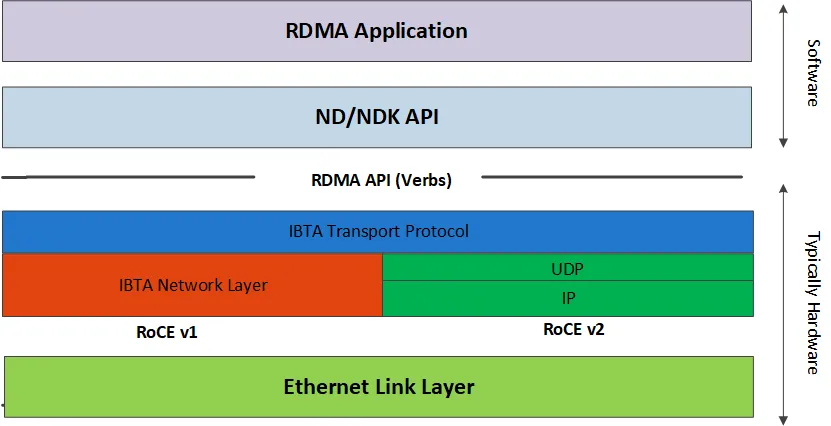
RoCE v1 与 v2 的协议栈对比
• RoCE v1:最早的版本,工作在链路层,只能在同一个 VLAN 里通信,不能跨路由器,扩展性很差,只能用在小集群里。 • RoCE v2:现在的主流版本,它把 RDMA 的报文封装在了 UDP/IP 包里,这样就能支持三层路由了,跨机架、跨数据中心都能跑,扩展性一下就上来了,现在的大集群用的都是 v2。
不过要注意,RoCE 需要一个无损网络的环境,因为 RDMA 是没有重传机制的,丢包了就直接出错了。所以交换机需要支持 PFC(优先级流量控制)和 ECN(显式拥塞通知),这样才能保证数据不丢包,这也是为什么普通的傻瓜交换机不能跑 RoCE 的原因。
性能到底强在哪?实测数据说话
说了这么多,RoCE 到底比 TCP/IP 强多少?我们来看一组真实的实测数据:
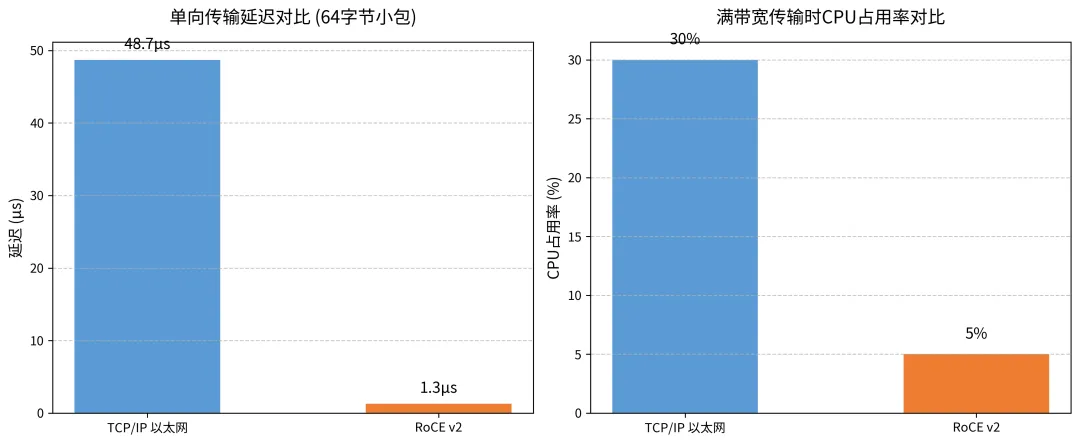
RoCE 与 TCP/IP 的性能实测对比
在同样的 100G 网络链路下,测试 64 字节的小包(AI 训练里的梯度包大多是这种小包):
• 延迟:TCP/IP 的单向延迟是 48.7 微秒,而 RoCE 只有 1.3 微秒,提升了 37 倍! • CPU 占用:满带宽传输的时候,TCP/IP 要占用 30% 的 CPU 资源,而 RoCE 只需要不到 5%,剩下的 25% 的 CPU,全给你省下来做别的事。
更重要的是,RoCE 的延迟非常稳定,p99.9 的延迟也只有 3.2 微秒,而 TCP/IP 的 p99.9 延迟高达 142 微秒,差了 40 多倍。这意味着什么?意味着 GPU 再也不用停下来等数据了,利用率直接拉满。
有测试显示,在千亿参数大模型的分布式训练中,RoCE 网络可以把整体的训练效率提升 40% 以上,原来需要 100 天的训练任务,现在只需要 60 天就能完成,这对于 AI 公司来说,就是时间就是金钱,早一天训完,就能早一天上线产品。
核心参数硬刚:普通交换机 VS RoCE无损交换机
很多人分不清普通数据中心交换机和专业RoCE交换机的本质区别,只看端口速率、交换容量等基础参数,误以为“都是100G交换机,性能差不多”。实际上,二者的核心差距不在于基础硬件规格,而在于无损网络能力、协议支持、时延、集群适配性四大核心维度,这也是普通交换机跑AI训练必翻车的关键。
下面整理了行业通用的同规格(25G/100G数据中心机型)参数对比,直观看清差距:
可以清晰看出,普通交换机的短板是底层机制性缺陷,无法通过调试、升级固件弥补;而RoCE交换机是从芯片、固件、调度算法全维度适配AI算力场景,也是智算集群的刚需硬件。
国产RoCE交换机实拍:主流机型外观&硬件优势
目前国内智算中心已大规模普及国产自研RoCE交换机,替代进口品牌,兼顾高性能、低成本、信创适配,主流机型涵盖25G/100G/400G全速率档位,完全满足中小集群到万卡超大集群的组网需求。

国产主流RoCE无损交换机(25G/100G智算机型)
国产RoCE交换机核心硬件亮点十分突出:搭载5nm高性能交换芯片,实现纳秒级转发时延,原生内置PFC/ECN无损网络能力;采用高密度端口设计,支持48口25G+8口100G、32口100G等主流规格,部分高端机型支持400G/800G超高速端口;同时配备模块化热插拔风扇、双冗余电源,整机散热、稳定性适配7×24小时不间断AI训练场景,完全对标进口Mellanox、英伟达RoCE交换机,且性价比更高、售后适配性更强。
升级 RoCE,要花多少钱?价格对比来了
很多人会问,这么好的技术,是不是很贵?毕竟以前的高性能网络,比如 InfiniBand(IB),那价格可是天价。
其实 RoCE 的一大优势,就是它的成本非常亲民,因为它是基于以太网的,很多硬件都可以复用。我们来做一个详细的价格对比,看看升级 RoCE 到底要多花多少钱:

主流的 Mellanox RoCE 交换机,兼顾性能与成本
可以看到,RoCE 的硬件成本,比普通的以太网方案贵了一倍左右,但是和传统的 IB 网络比起来,那可就便宜太多了 ——IB 网络的成本是 RoCE 的 2-4 倍,而且 IB 的网卡、交换机、线缆都是专用的,完全不能复用。
举个例子,搭一个 32 节点的 AI 集群,用 IB 网络的话,光是网络部分就要花几十万,而用 RoCE 的话,十几万就能搞定,性能却只差了一点点。
而且更重要的是,RoCE 的光模块、线缆,和普通以太网的完全通用,你原来的网线、光模块,只要是符合规格的,都能直接用,不需要重新买,这又省了一大笔钱。
分场景选型指南:不同业务对应的RoCE交换机推荐
很多用户落地RoCE网络时容易踩坑:盲目采购高端800G机型造成预算浪费,或是选用入门机型承载大模型训练,导致性能瓶颈。RoCE交换机选型核心原则是场景匹配、带宽适配、成本可控、兼顾扩容。
结合AI算力中心、高性能计算、分布式存储、商用推理等主流场景,整理出分场景精准选型方案,涵盖国产信创、进口高端全品类,附具体机型、配置标准和适配理由,直接落地可用。
场景一:中小规模AI训练集群(8-32卡)
适用场景:中小企业、科研实验室、垂直行业小模型训练、算法迭代测试集群,预算有限、组网规模小,无需超大带宽,但需稳定无损传输。
选型核心要求:25G/100G混合端口、基础PFC/ECN无损能力、低时延、高性价比、运维简单,无需三层复杂组网。
推荐机型
• 国产优选&参考单价:锐捷 RG-S6980(约2.8-3.2万元)、华为 CE6857(48×25G+6×100G,约2.0-2.2万元),性价比突出,适配小规模算力组网预算。 • 进口优选&参考单价:Mellanox SN2100(48×25G+8×100G,约4.5-5万元),性能稳定但价格显著高于国产机型。
选型理由:这类盒式交换机性价比极高,完美适配中小集群梯度同步需求,纳秒级稳定时延,杜绝小规模集群常见的轻微拥塞丢包问题。设备体积小、部署简单,兼容现有以太网运维体系,无需重构网络架构,相比IB组网可节省60%以上硬件成本,是中小AI集群的性价比天花板。
场景二:中大型大模型训练集群(32-512卡)
适用场景:企业自研大模型、行业通用大模型训练、中等规模智算中心,高并发梯度传输、多节点协同频繁,对时延抖动、无损稳定性要求极高。
选型核心要求:全100G端口、增强版Headroom缓存、智能拥塞调度、高精度PFC防死锁、支持三层RoCEv2组网,保障多机架集群无抖动传输。
推荐机型
• 国产优选&参考单价:星融元 CX-N100(全100G端口,约4.8-5.5万元)、新华三 S12500X-AI 系列(中端款约5.2-6万元),性能对标进口主流机型,成本更低。 • 进口优选&参考单价:NVIDIA SN2410、SN2700 100G高密度无损交换机(约8-10万元/台),适合预算充足、追求极致稳定性的商用集群。
选型理由:专属AI优化芯片,针对大模型小包梯度传输做专项优化,可有效规避多卡同步时延累积问题。增强型缓存队列可应对高并发拥塞场景,p99.9时延稳定可控,能将大模型训练效率稳定提升35%-45%,适配绝大多数商用大模型训练场景。
场景三:万卡级超大智算集群(512卡以上)
适用场景:头部科技公司超大规模通用大模型、国家级智算中心、超算HPC场景,上万GPU协同训练,跨机架、跨机房组网,极致低时延、零丢包、高扩展性是核心刚需。
选型核心要求:400G/800G超高速端口、无损全网优化、分布式负载均衡、集群级拥塞管控、支持十万级端口扩容。
推荐机型
• 国产优选&参考单价:锐捷 RG-S6990(64×800G,约22-25万元)、华为 CE8850 400G/800G智算专用交换机(约18-22万元),国产高端顶配,大幅节省超大集群组网成本。 • 进口优选&参考单价:NVIDIA Spectrum-X SN4700 800G高端RoCE交换机(约35-40万元/台),顶级性能,头部超算集群专用。
选型理由:当前顶级AI组网硬件,搭载自研智算专用芯片,支持AILB智能负载均衡算法,可解决万卡集群流量倾斜、拥塞抖动难题。三层大网架构支持无限扩容,完全对标IB超算网络性能,同时保留以太网通用、低成本、易运维的优势,是目前超大智算集群的主流标配。
场景四:AI推理+分布式存储集群
适用场景:线上大模型推理服务、Ceph/NVMeoF分布式存储、大数据算力调度,核心需求是高吞吐、低IO延迟、数据读写零丢包。
选型核心要求:基础RoCEv2无损能力、高带宽吞吐、多租户隔离、适配存储协议卸载,无需极致低时延,侧重稳定性和吞吐效率。
推荐机型
• 国产高性价比款&参考单价:盛科、智邦25G/100G通用RoCE交换机(1.5-2万元/台),极致性价比,适配常态化线上业务。 • 通用稳妥款&参考单价:华为 CE6820(约1.8-2.1万元)、Mellanox SN2010(约3.8-4.2万元),运维成熟、故障率低。
选型理由:推理和存储场景对毫秒级时延不敏感,但对吞吐稳定性、IO可靠性要求极高。该类机型可通过RDMA零拷贝大幅降低存储读写延迟,提升集群IOPS 40%以上,同时适配线上业务多租户隔离需求,性价比拉满,完全满足常态化线上业务运行需求。
场景五:信创国产化专属场景
适用场景:政企、科研、国资项目等要求100%信创适配的AI算力集群,需纯国产芯片、国产固件、无进口组件。
参考单价:全栈国产信创RoCE交换机(25G/100G机型1.8-5.5万元,400G/800G高端机型18-25万元)
选型优势:硬件、芯片、固件全栈国产化,适配信创验收标准,同时完整保留PFC/ECN无损、RoCEv2、硬件协议卸载等核心能力,性能可完全替代进口机型,且售后本地化、定制化适配更强,是政企AI项目唯一合规选型。
场景选型总结表
现在的 AI 集群,都在用什么?
现在,国内国外的大模型公司,几乎都把 RoCE 当成了智算集群的标配。
比如字节跳动的万卡集群,阿里云的智算平台,还有腾讯、百度的大模型训练集群,用的都是 RoCE 网络。为什么?因为 IB 太贵了, scaling 到上万卡的时候,成本根本扛不住,而 RoCE 兼顾了性能和成本,是目前最优的解。
甚至英伟达自己,现在也在大力推 RoCE,他们的 Spectrum-X 平台,就是专门为 AI 训练设计的 RoCE 网络方案,支持 800G 的端口,能支持几十万卡的超大集群。
这说明什么?RoCE 已经不是什么小众的黑科技了,它已经成了 AI 时代的网络标准。如果你现在还在用普通的交换机跑 AI,那你就是在用十年前的技术,跑今天的算力,你的 GPU 的性能,至少有 30% 被网络给浪费了。
写在最后
AI 的发展,从来都不是只靠显卡的。算力的提升,必须要有网络的配合,不然再多的 GPU,也只是一堆孤立的卡片,没法协同工作。
普通的以太网交换机,在过去的几十年里,支撑了互联网的发展,但是在 AI 时代,它已经不够用了。RoCE 的出现,不是要推翻原来的以太网,而是在以太网的基础上,做了一次升级,让它能跟上 AI 的脚步。
如果你正在搭 AI 集群,如果你发现你的训练速度上不去,如果你觉得 GPU 的利用率不够高,不妨看看你的网络 —— 是不是还在用普通的交换机?
别再让老旧的网络,拖了 AI 的后腿了。
“ 云淡风轻、乘风破浪”
Dear friend,欢迎关注、点赞、交流!
