 夜雨聆风
夜雨聆风背景
vLLM | SGLang | |
|---|---|---|
Server参数 |
|
|
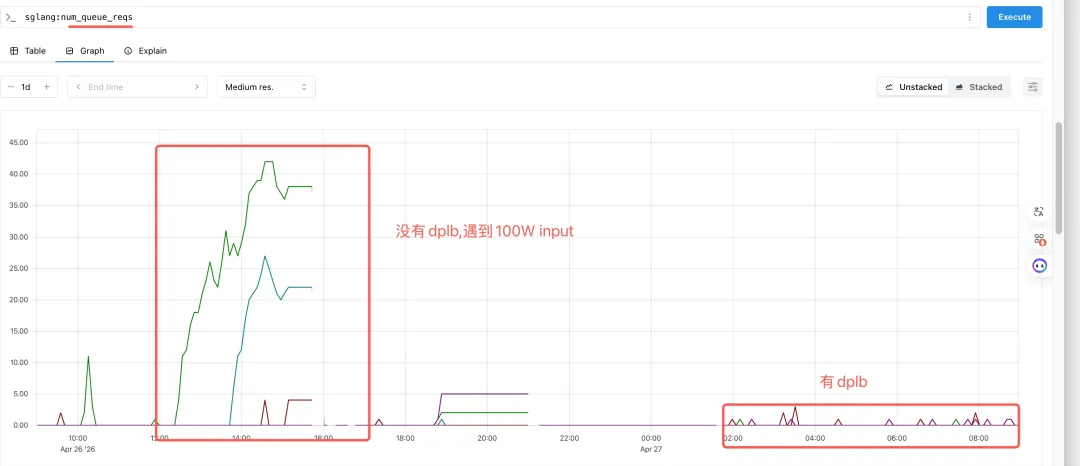
调度粒度 | queue-aware | queue-aware、token-aware |
vLLM DPLB: 三种部署模式
Internal
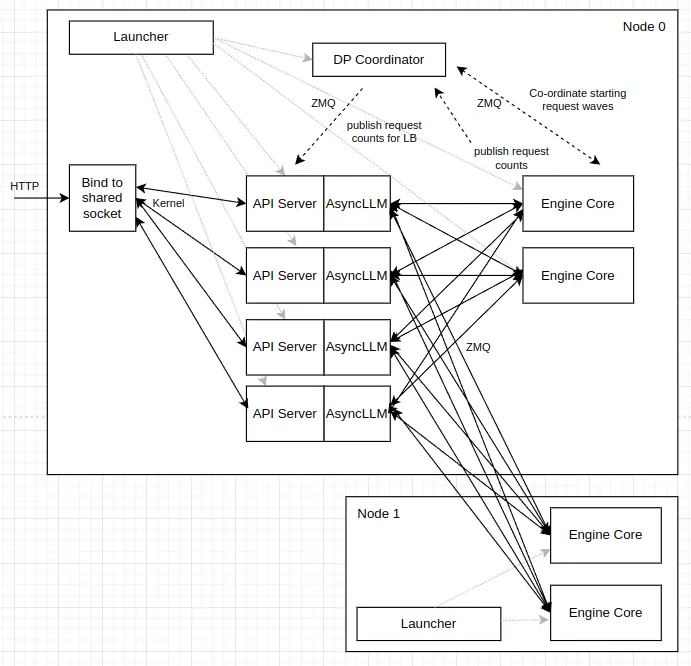
图1: Internal
# Node 0 (with ip address 10.99.48.128)vllm serve $MODEL --data-parallel-size 4 --data-parallel-size-local 2 \--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345# Node 1vllm serve $MODEL --headless --data-parallel-size 4 --data-parallel-size-local 2 \--data-parallel-start-rank 2 \--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345
如图,DP=4(EngineCore 共 4:Node0 两个 + Node1 两个);
API Server / AsyncLLM 也是 4 组(Internal 默认 api_server_count = data_parallel_size)
EngineCore ──上报 [waiting, running](发现有变化时)──→ DPCoordinator(汇聚)←──约每 100ms 广播 stats──→ API 侧更新 lb_engines(不选 rank)
Coordinator 与 AsyncLLM 的交互 → stats 下行广播(给 DPLB 用)。
Coordinator 与 Engine Core 的交互 → stats 上行上报(虚线
publish request counts) + 同一条协调链路上的 MoE wave(见下)
HTTP →(Kernel 分到某一 API 进程)→ API Server / AsyncLLM→ DPLBAsyncMPClient 选 rank(waiting×4 + running)→ ZMQ → EngineCore(DP rank k) (k可在 Node0 或 Node1)
ZMQ分发完,KV 绑在该 rank。
3. MoE控制路径
WAVE
在分布式数据并行场景下,多个EngineCore进程需要协同处理一批请求。每一批请求被称为一个"wave"(波次),每个wave代表一组需要同步处理的请求,所有进程必须在同一个wave上协同工作,以保证状态一致。
https://zhuanlan.zhihu.com/p/1927317160889386326
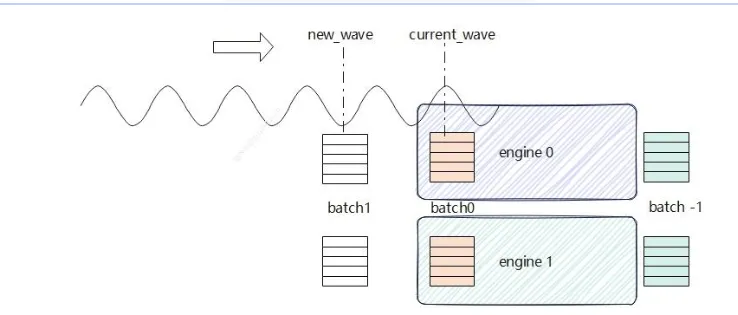
图2: https://zhuanlan.zhihu.com/p/1927317160889386326
EP Collective
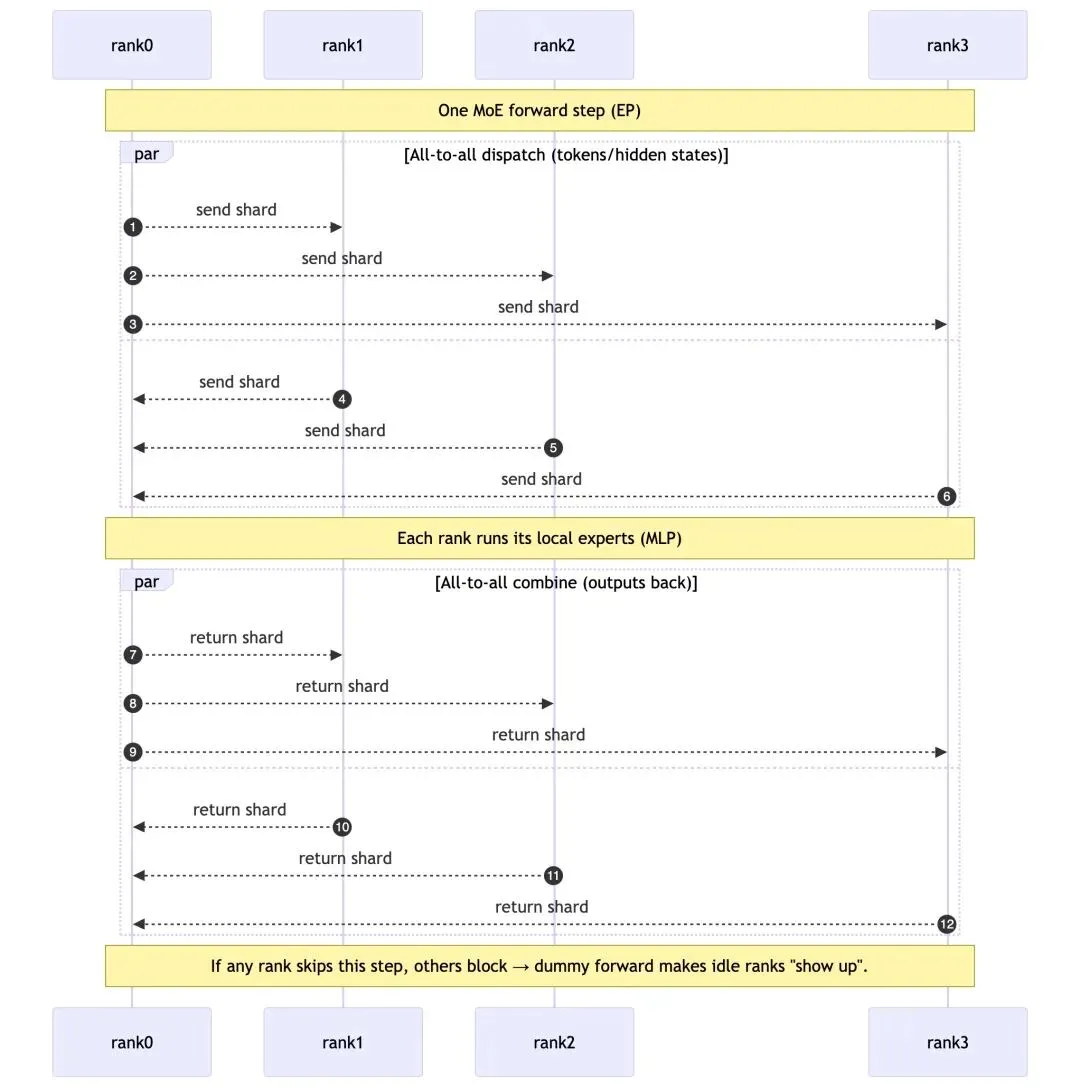
EngineCore(每个 DP rank) ──(collective 判断全局是否空闲)──→ wave / running_state 变化API/AsyncLLM ── FIRST_REQ (只有在全局 paused 时) ──→ DPCoordinatorDPCoordinator ── START_DP_WAVE(wave++) ──→ 所有 EngineCore(一起进入 running)
Dummy怎么来的?
Dummy forward会污染KV cache吗?
# vllm/vllm/v1/worker/gpu_model_runner.py# Dummy runs have no real slot assignments — fill with -1 so# concat_and_cache kernels skip the KV write.... sm.fill_(-1)
Hybrid和External
Hybrid
# Node 0--data-parallel-size 4 \--data-parallel-hybrid-lb \--data-parallel-size-local 2 \--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345# Node 1--data-parallel-size 4 \--data-parallel-hybrid-lb \--data-parallel-size-local 2 \--data-parallel-start-rank 2 \--data-parallel-address 10.99.48.128 --data-parallel-rpc-port 13345 \
External
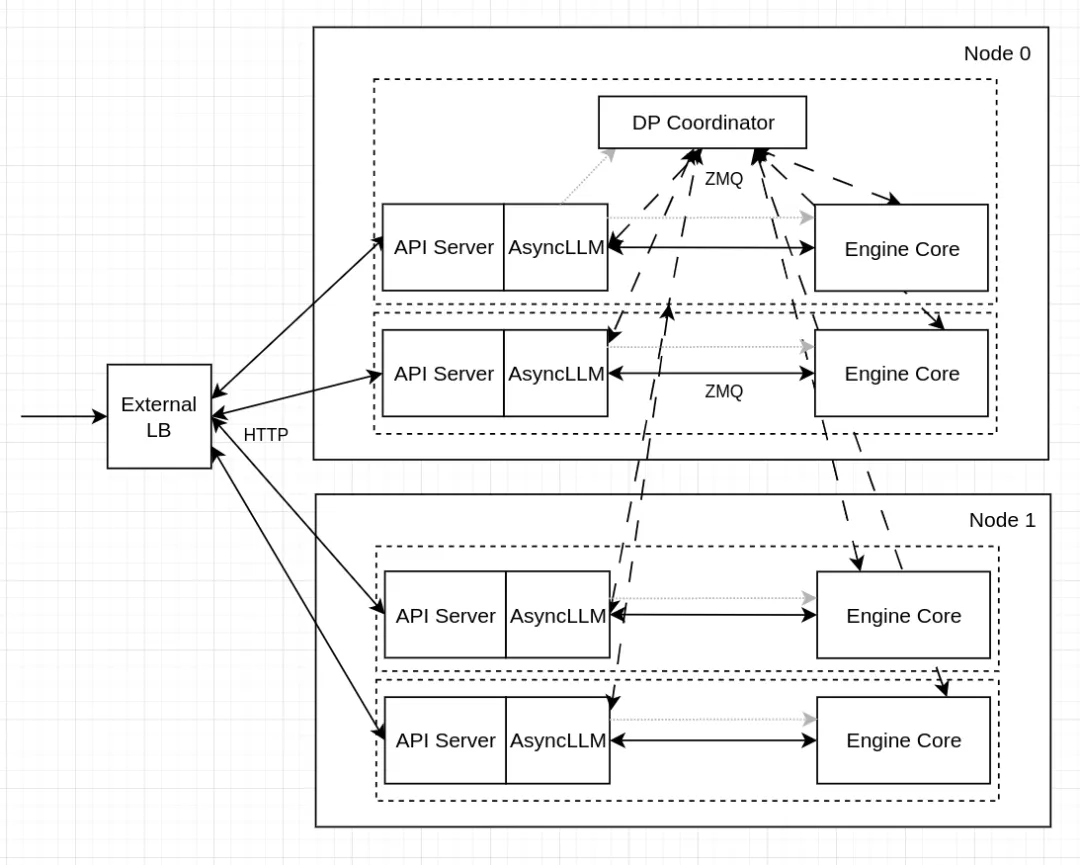
图3: External
请求路径:
Client → External LB → 某个 rank 的 API endpoint → AsyncLLM → 本实例的 EngineCore关键点:“选哪个 rank”由 External LB 决定(基于你自己的策略/监控)。
stats路径:
2种command写法:
CUDA_VISIBLE_DEVICES=0 vllm serve $MODEL --data-parallel-size 4 --data-parallel-rank 0 --port 8000# ... rank 1/2/3 同理
vllm serve $MODEL \--data-parallel-size 4 \--data-parallel-rank 0 \--data-parallel-external-lb \--port 8000
SGLang DPLB: 算法枚举
--load-balance-method | 含义 |
|---|---|
| 轮询 DP worker,跳过 unhealthy |
| bootstrap_room % dp_size 固定映射(PD prefill) |
| 选 running+waiting请求数最少(argmin) 的 rank (不像vLLM有做加权) |
| 选 KV 已用 token (=log中的full token) + waiting 里 |
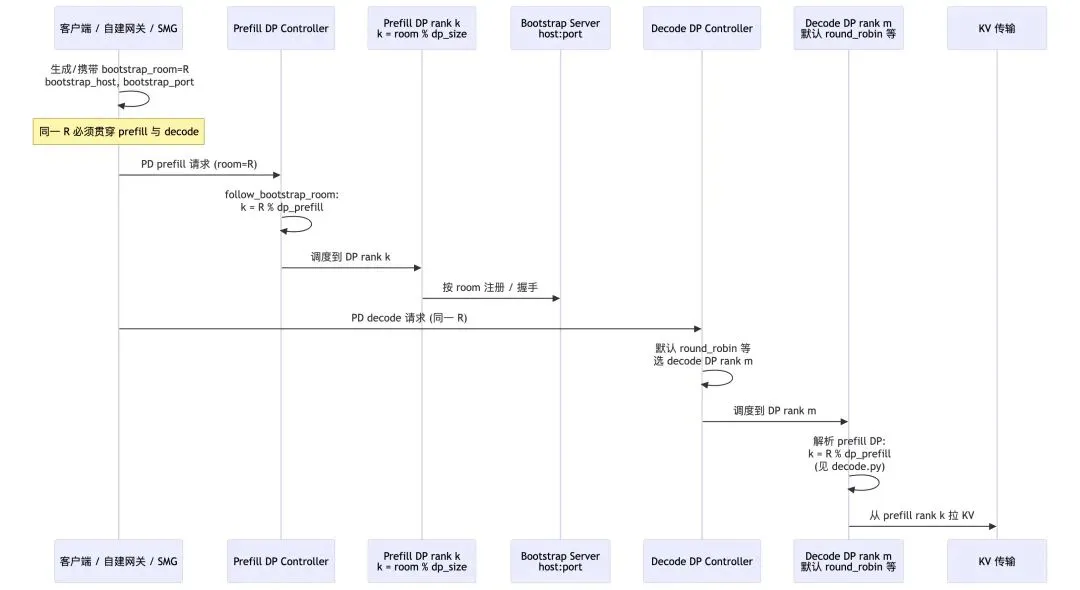
这里dp_prefill等同于dp_size 1. Router/客户端 给这条请求一个 R(bootstrap_room),prefill、decode 共用。2. Prefill DP Controller(follow)k = R % dp → 请求进 Prefill DP rank k,KV 写在这里。3. Decode DP Controller(默认 round_robin)请求进 Decode DP rank m(轮询,和 R 无关,只是分 decode 算力)。4. Decode 拉 KV 时再算一遍 k = R % dp → 去 Prefill rank k 取 KV(图上「见 decode.py」)。
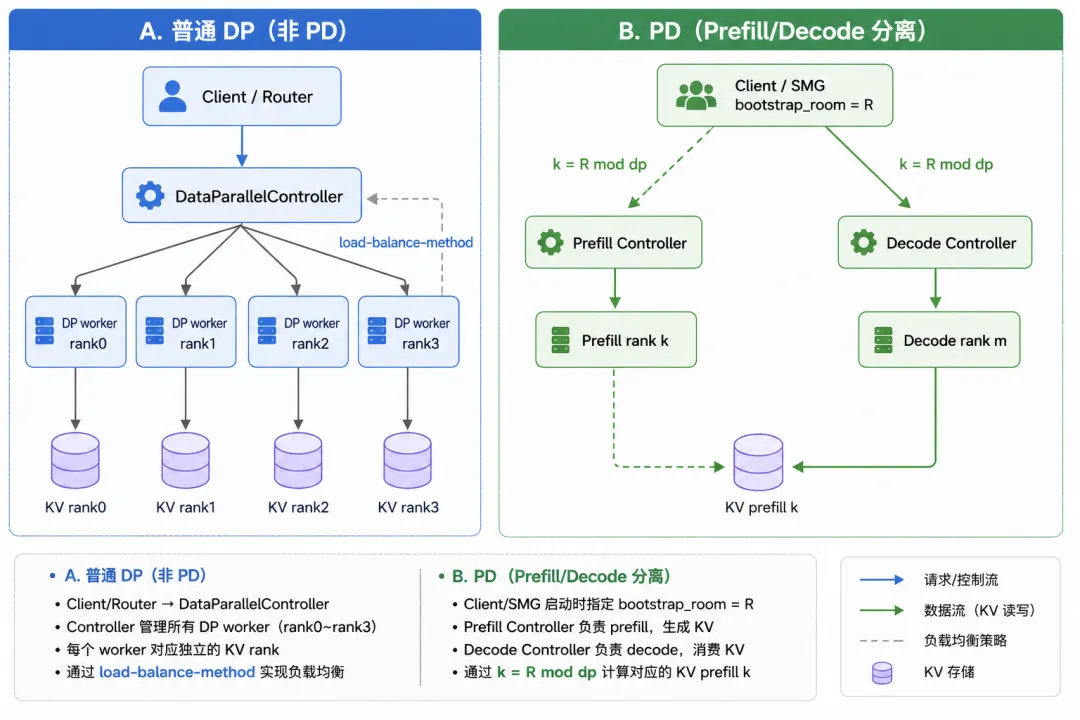
建议
References
[1] LLM推理数据并行负载均衡(DPLB)浅析
[2] vLLM DP特性与演进方案分析
