 夜雨聆风
夜雨聆风lm · 2026-06-05
AI 从炫技走到验收日
从 ChatGPT 记忆到 Broadcom 盘前下跌,今天的共同变化是 AI 不再只讲能力,产品和市场都在追问能不能被检查、被审计、被兑现。
今天两份简报放在一起看,有个别扭的画面。
OpenAI 给 ChatGPT 做更强的记忆整理,Anthropic 公开说 Claude 已经参与写入超过 80% 合入代码库的代码,Google 把多模态模型压到 16GB 机器也能跑。按理说,AI 产品侧的好消息不少。
但市场那边不太配合。Broadcom 的 AI 半导体收入同比增长 143%,Q3 还预计更高,盘前照样一度大跌。A 股科创 50 逆势涨,存储、PCB、机器人还有强点,可全市场超过 4000 只个股下跌。美股道指创纪录,纳斯达克 100 被芯片股拖住。
我觉得今天值得写的,不是“AI 还火不火”。这个问题太粗了。更像是 AI 终于从演示台下来,走进验收环节。产品要交使用账,市场要交收入账,风险要交审计账。
产品开始有账本
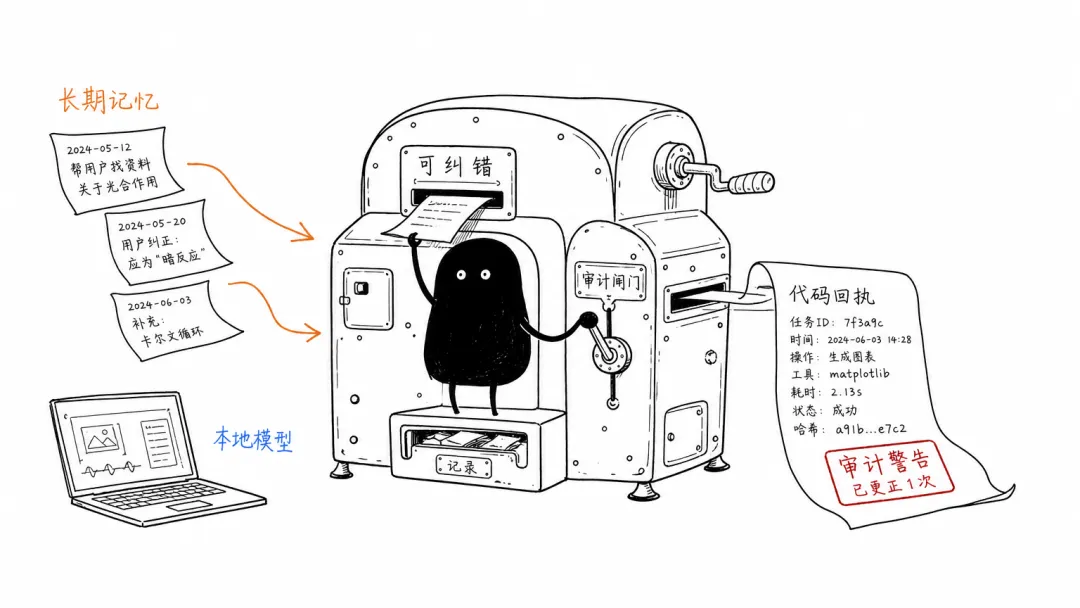
ChatGPT 的 Dreaming 处理的是长期使用里最麻烦的东西:记忆会过期,会记错,会越积越多。
对我这种把 Vault 当长期工作台的人,这个变化很实在。单轮回答好不好,我很快能看出来;长期记忆好不好,要过几周才暴露。它记住错的偏好,沿着旧结论继续做,影响会比一次回答错误更隐蔽。
所以记忆不是“多存一点上下文”就完了。用户要能看见它记了什么,能纠正,能删除,也能知道它什么时候拿旧信息做判断。
Anthropic 的数据更刺激:截至 2026 年 5 月,Claude 参与写入了超过 80% 合并进代码库的代码,典型工程师日合并代码量约为 2024 年的 8 倍。这个数字听着像胜利,也像提醒。代码越来越容易生成,评审、测试、权限和回滚就不能靠感觉。
Google 的 Gemma 4 12B 则把另一件事推到桌面上:本地多模态 agent 会更便宜,隐私数据和离线自动化更容易做。可越靠近本机文件、摄像头、麦克风和内部知识库,越需要知道谁在读、读了什么、什么时候停止。
AI 公司联名支持合成 DNA/RNA 订单筛查,放在这组新闻里一点也不突兀。模型能力接近现实世界流程时,闸门会提前出现。
市场也在要回执
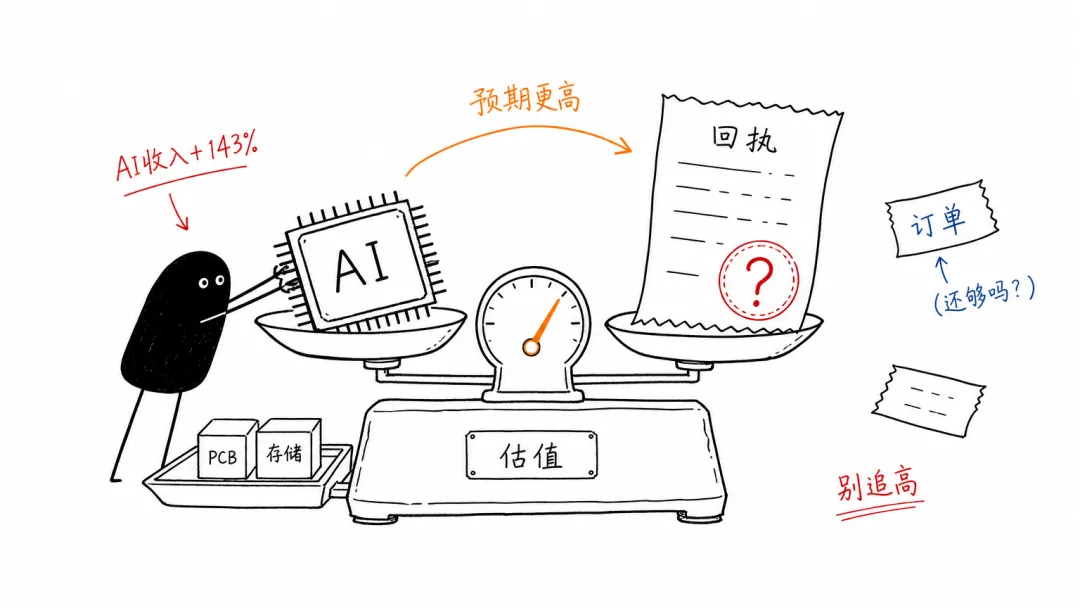
Broadcom 是今天最好的反面教材。
它不是没增长。AI 半导体收入同比增长 143%,还预计 Q3 AI 半导体收入同比增长超过 200%。这种数字放在别的行业,已经足够吓人。但股价反应说明一件事:市场已经把很高的 AI 增长写进价格里了。
好业绩不一定带来好交易。投资者会继续问:客户是不是太集中,资本开支还能撑多久,毛利率会不会被供应链和竞争挤压,下一季能不能继续超过已经很高的预期。
A 股也类似。科创 50 能逆势涨,说明硬科技没有散;存储芯片、PCB、电子化学品和机器人还在被资金盯着。但超 4000 只个股下跌,也说明钱并不宽松。资金不是在买“所有科技”,而是在少数有订单、有价格、有业绩想象的方向里挤来挤去。
美股更明显。道指和小盘股修复,说明风险偏好没有消失;纳斯达克 100 被芯片股拖住,说明 AI 权重股不能再只靠“还在增长”四个字继续抬估值。
做产品和看资产,问题变成同一个
产品侧和市场侧看起来离得很远,其实都在逼 AI 留下可检查的回执。
做 AI 产品,别只问模型能不能做。还要问它做完以后能不能被看见,错了能不能撤回,越权了谁能拦住,用户怎么知道它用了哪段记忆、哪份文件、哪个工具。
看科技资产,也别把高增长自动翻译成高赔率。Broadcom 的盘前反应已经说明,高预期本身会变成负债。收入增长、订单兑现、估值消化、宏观利率,少一个环节都可能让股价先冷下来。
这对个人开发者也有提醒。现在做 agent 原型比以前容易,本地模型也更可用,但越容易接进真实文件和真实流程,越不能只做漂亮 demo。一个能长期用的 agent,应该有记忆列表、权限边界、运行记录、失败回放和人工接管入口。没有这些东西,用户一开始会觉得新鲜,用久了会害怕。
明天我会盯几件具体事:Broadcom 的下跌会不会继续压半导体,A 股存储和 PCB 能不能从一日强点变成连续强点,美债收益率和油价会不会重新压住成长股,AI 生物安全筛查这类现实闸门会不会出现更明确的制度动作。
今天的结论可以很朴素:AI 仍然是最重要的科技变量之一,但它开始被要求交作业了。产品交给用户验收,收入交给市场验收,风险交给监管和审计验收。
以上只是信息整理和个人观察,不构成投资建议。涉及具体资产时,仍然要看自己的风险承受能力、持仓周期和资金安排。
