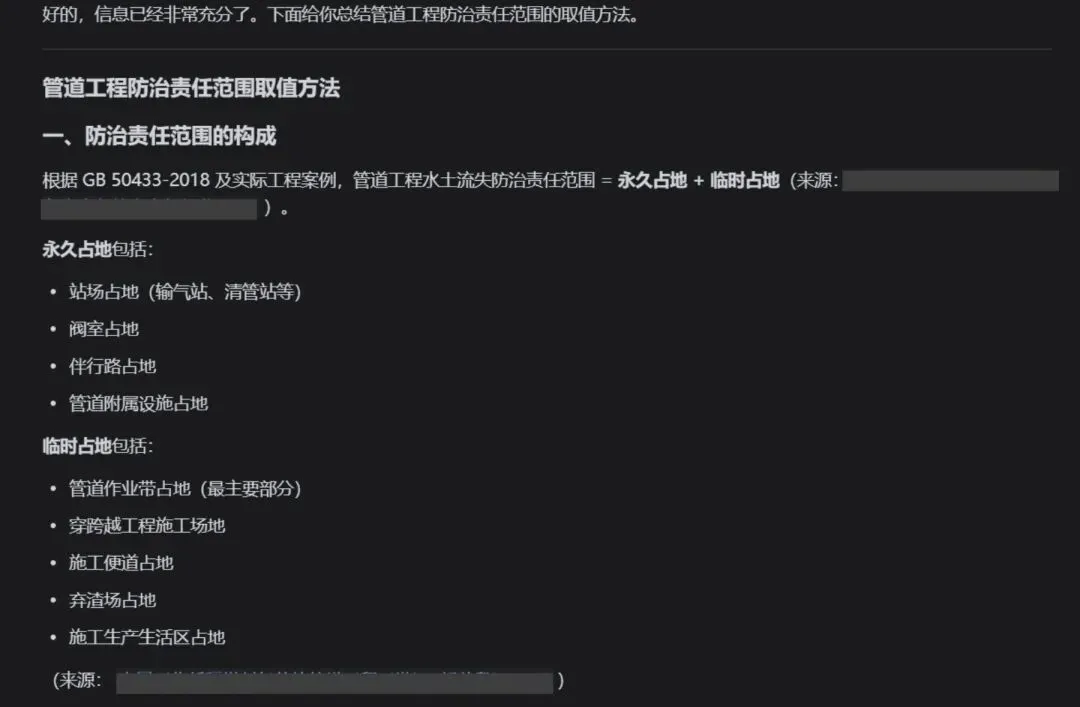
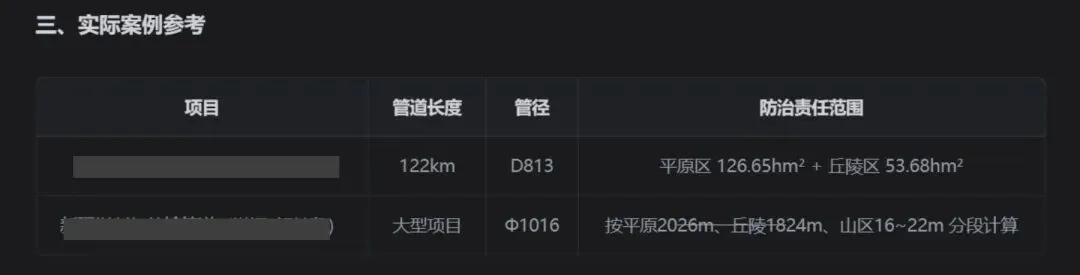
 夜雨聆风
夜雨聆风
点击蓝字 关注我们

今天分享一下一些朋友咨询的:
如何把“规范,相关文件,和大量已经过审的典型报告”,
形成一个向量的数据库。
有着非常暴躁的检索性能和识别模式。
一 是为了解决自己脑袋里经验,概念不够的问题:通过向量数据库索引出同类项目的报告切片,场景,工况来辅助我们和AI一起判断。
二,更加精确的让AI自动套模板,解放工程师双手。
本文共分7节,
第六节为实操。其余均为概念科普。

一,什么是向量
向量 = 文本 / 图片 / 文件的数字指纹。
我们的自然语言(水保报告文字、措施描述、模数说明)人类看得懂,
但是AI 看不懂,需要 嵌入模型(Embedding),
让模型把一句话、一段报告转成一串固定长度浮点数字:
例:
临时堆土场布设袋装土拦挡+排水沟 →(0.21,0.75,-0.33……)
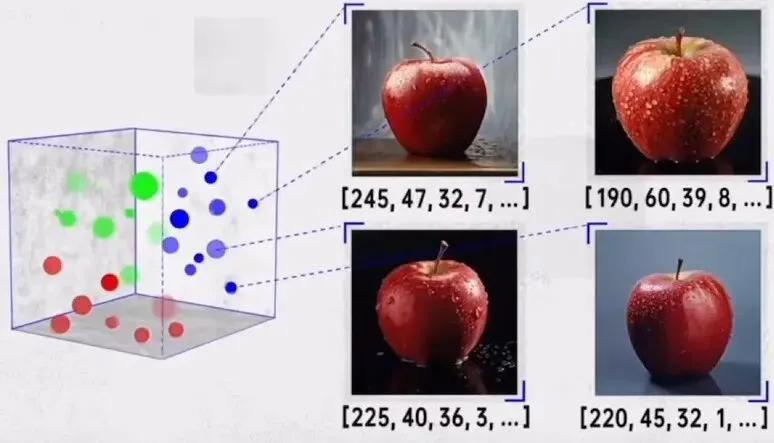
这串数组就是特征向量,维度常见 384/512/768/1024 维。
语义越相近,向量在数学空间里距离越近:
“弃渣场边坡防护” 和 “排土场护坡” 向量距离近
“光伏板覆土绿化” 和 “公路路基开挖” 向量距离远
“水土保持”和“水保”向量距离近
“防洪评价”和“表土剥离”向量距离远
等等。。。
二、普通数据库 vs 向量数据库
MySQL/Excel(传统标量库)只能精准关键词匹配:搜「弃渣场稳定性」,只命中含这五个字的文档,同义词、近义词搜不到;水保里想找同类措施、相似项目很难。
向量数据库存海量向量数组,支持相似度检索:不用精准关键词,输入项目概况,自动在 建造者投喂的报告向量里找出行文、工况最像的几份方案。
当数据量上去之后,精度就会越来越高,恰是炼丹。笔者第一期投喂大概50份合规报告,后续或许会视实战效果大量投入。
三:向量数据库三大核心功能
向量入库(Insert)
笔者第一批把所有规范,和 50 份已经过审的报告分段切片→Embedding 转向量→存入库,附带元数据(标签)。
规范(GB标签)项目类型 、行政区、占地、批复年份、水土保持区划、评审意见。
后续使用,可以先筛「XX市 + 矿山项目/道路项目/灌区项目等」再做向量检索,缩小范围,就可以精准定位。
2. 相似度查询(ANN 近似最近邻检索,最核心)
只要我们输入新项目描述→AI就会自动调动数据库转查询向量→引擎快速在库中找空间距离最近的 N 条向量,然后返回对应原文 + 附件。
如:新项目占地 23hm²、丘陵地貌采石场,一键调出库内 10~50 个同地貌采石场方案。结合规范交给AI分析。
3. 过滤、更新、删除
可以通过元数据过滤:只查湖北省已批复方案、2022 年后新版规范编制报告,剔除作废旧报告向量。
四、关键技术名词(精简版)
1. BGE-small-zh
国内 BAAI 开源中文 Embedding 嵌入模型,负责把自然文本换算成固定512 维稠密数字向量,能理解词语语义、专业同义词,是中文知识库主流向量化模型。
2. 稠密向量(512 维 Embedding)
将一段文字压缩为 512 个连续数字,语义相近的文本,对应的数字数组距离更近;是 FAISS 做相似度检索的底层数据。
3. FAISS IndexFlatIP Meta
开源向量检索框架里的精准全量索引类型,生成index.faiss文件,基于内积距离计算向量相似度,全量精准比对,实现毫秒级语义检索。
4. 文本块(Chunk)
原始 PDF 文档按固定字数(本例约 500 字)拆分后的小段文本,是 Embedding 向量化的最小单位,全库合计 24402 个文本块。
5 语义相似度检索
依托向量数值远近判断含义相似度,不依赖字面关键词一致,同义、换句式的专业提问也能命中原文,检索相关度 0.84~0.91。
五、轻量级数据库的落地体量和需求文本书
例如一个单份报告,会拆分 50~100 个文本片段,50 本≈2500~5000 条向量;
Chroma、FAISS、Qdrant 轻量化库完全本地免费部署,不需要云服务器,不咋地的电脑就能跑。
笔者第一轮,进行数据清洗,剔除一些垃圾报告。
放50个文件看看效果(新旧规范,各类项目报告书)。
如果效果不错,我将投入投入更多个过审的报告。
六,建库和实操

建库:


只需要对着AI编程环境提出需求就行。非常简单。
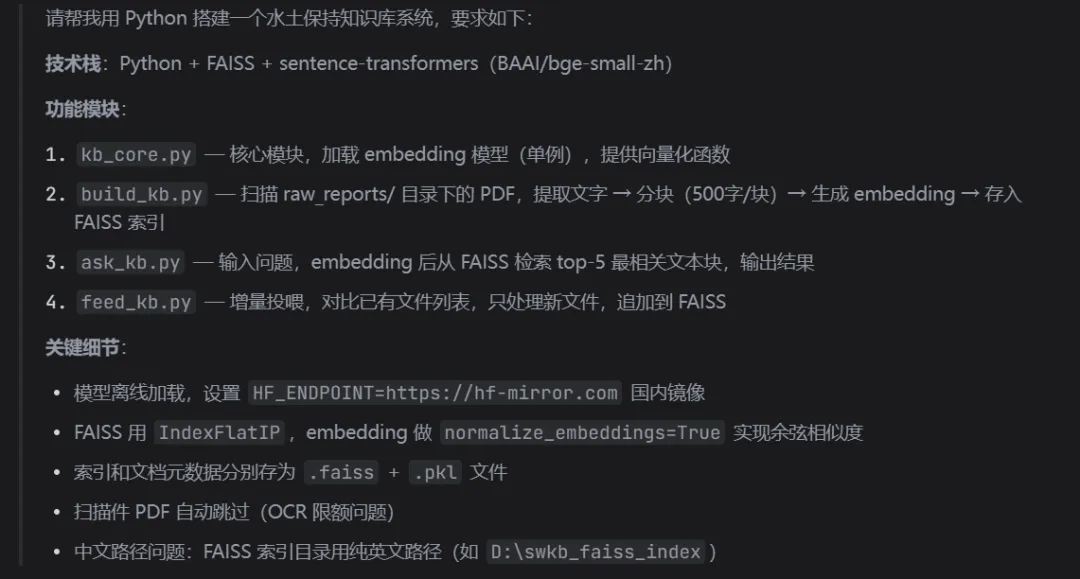
提示词如上,截图提取文字,丢给AI环境即可。
等AI给你写完,就封装成一个skill或者MCP,注册在AI环境里。
注意:必须用全英文的文件夹地址存放生成的数据库索引文件,不然会出现莫名其妙的错误。


最终会生成这三个文件:
index.faiss
FAISS 索引实体文件,只存储全部文本的 512 维向量数据,检索时用来快速匹配和问题语义最贴近的文本序号。
documents.pkl
Python pickle 序列化文件,存储被切分后的原文文本块;FAISS 搜到序号后,从此文件取出对应正文。
metadatas.pkl
pickle 打包文件,存储每条文本的元数据:所属 PDF 文件名、页码、文档路径、标签等溯源信息。
三个文件接入大模型后,就可以实现
AI 提问→问题转向量→FAISS 检索原文→参考原文生成专业答案。

实操逻辑:


例如,随便问一个比较抽象的问题:

(错别字很多哈,别介意,天天用电脑,实际生活中除了名字其余字都写不利索了,还好AI不傻)
AI在数据库中基本上快速遍历了所有报告和相关规范:
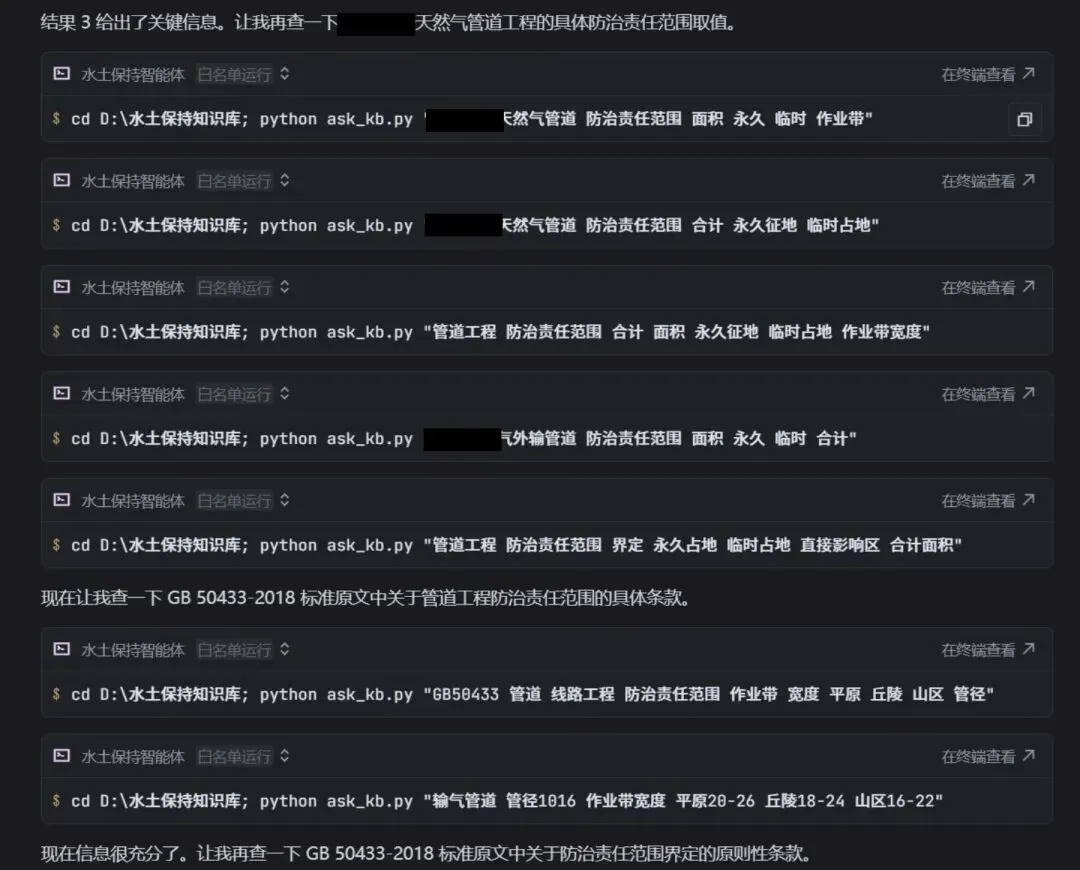
检索速度非常快,然后得出结论:


AI肯定还是看的懂了。
借助DS超长的上下文,这个回答大家觉得这个结论是否中肯呢?

后续操作


利用向量数据库的目的就是让AI不去凭空造内容,
让AI 只做三件事:
填空、替换计算参数、思考选用语料和措辞。
我们选用一个成熟的模板 + 向量库检索取值/核对规范 + AI自主分析。
写完之后进行AI自检,迭代个几轮。
就能彻底杜绝 AI 乱写,规范乱套、结构跑偏。
七 结语
不需要斥资自己训练什么小模型,
或许这才是降本增效的最优解,
工程师只用去聚焦更核心的部分,
对重复无聊的复制粘贴说拜拜。
大单位把自己做过的项目,例如存在NAS里的,进行向量化。
管理者在电脑上搞个权限,就可以给下面员工有限调用这个SKILL。
而不是费尽心思去硬盘里检索,死脑细胞找模板协调下方。
小单位或个人,则可以等笔者后面分享。
当然,想用这种方法试着写更复杂的也不是不行。
只是还有非常多的缺陷需要优化。
因为这个数据库和建库工序,是非常初级的:
切片暂时没标准、检索质量不稳定、质量很靠运气
文本相似≠工程相似、工况可能错配、隐性技术漏洞
元数据简陋、精准度上限很低
无数据没清洗、脏数据多。
模板同质化、无适配性、新型项目无法写
虽然有规范规定计算逻辑、但是无法校验公式、核心工作量未解放。
后续有时间,出个优化过后这些问题的高级版。

(摄影,周南 青藏高原表土调查 )
有许多粉丝朋友觉得作者懂很多。
其实不是的。。。
朋友们问的问题都太震撼了,我时常感觉脑袋宕机。
什么表土都被挖走几年了补方案,怎么做表土调查。。。
这种怎么造,怎么拍脑袋,或者商务,自己老板去解决的问题,
就别来咨询笔者了。
对一些AI概念不清楚的,可以选择性看看前面的教程。
说不定会有一定的化学反应。
轻量化 AI 协同办公教程:从零搭建环境|IDE+Python+DS+CAD
