 夜雨聆风
夜雨聆风最近发现了一个让我眼前一亮的开源项目。
Soul App 联合西北工业大学 ASLP 语音实验室、月步 AI,把内部打磨的多说话人语音转录模型对外开放了,项目叫 SoulX-Transcriber。
这个发布节点很有意思。Soul App 本身是个以语音社交为核心的产品,多人对话场景是它的日常,这个模型不是实验室里凭空搭出来的,是真实业务里跑出来的。

一个模型,把三件事同时搞定
多说话人转录这件事,之前一直是这么干的:先用说话人分割(Diarization)把"谁说了哪段"分清楚,再把每段单独扔给语音识别(ASR)转成文字,最后把两段结果拼起来。
看起来合理,问题在于误差会叠加。前面分割错了,后面识别再准也没用。更麻烦的是,两个模型是独立训练的,它们根本不知道彼此的存在,合并出来的稿子经常对不上。
SoulX-Transcriber 的思路是:这三件事——谁说的、什么时候说的、说了什么——放进一个模型里联合训练,一次推理直接输出。
说话人身份、时间戳、转录文字,三路输出同时给你,而且互相是对齐的。
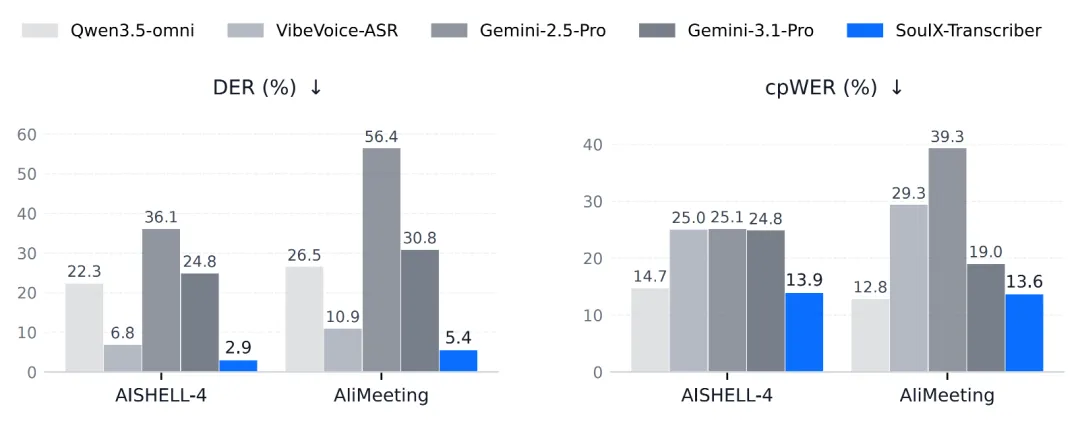
在 AISHELL-4 这个多说话人中文基准测试上,SoulX-Transcriber 的说话人错误率(DER)打到了 **2.89%**。
对比一下同场景的竞争对手:
Gemini 2.5 Pro:36.07% Gemini 3.1 Pro Preview:24.84% Qwen3.5-omni:22.33%
差距不是一点点,是一个量级。
Gemini 2.5 Pro 在识别文字内容上不差,但多说话人场景里分不清"这句话是谁说的",DER 飙到 36%。SoulX-Transcriber 在同一个测试集上把这个数字压到了 2.89。
AliMeeting 基准上也是一样,DER 5.39%,对比 Gemini 2.5 Pro 的 56.39%。
开会录音扔进去,出来的稿子里,说话人标签的准确率已经到了工业可用的程度。
训练数据怎么来的
这是我觉得这个项目设计得比较想清楚的地方。
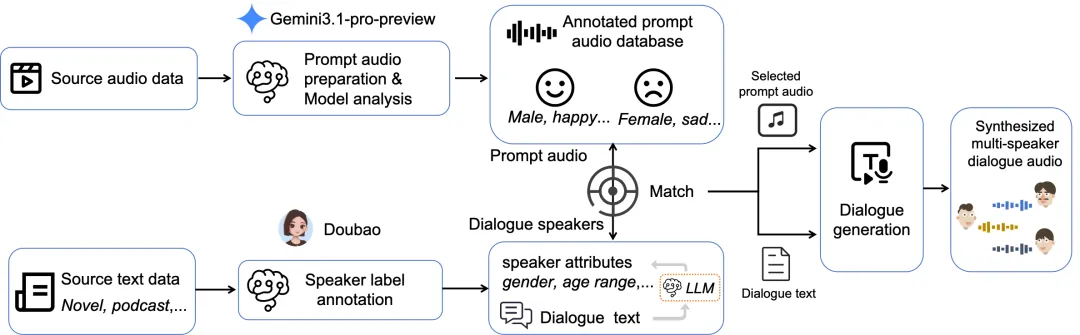
多说话人模型最难的不是架构,是训练数据。真实的多人对话录音很难大量获取,标注成本又高。
他们做了一套对话模拟生成流水线:先从播客、小说里收集多说话人对话文本,用 LLM 打上说话人标签;再从影视剧音频里切出 3–10 秒的参考音频片段,每个片段用 Gemini 标注性别、年龄、语速、音色、情绪等多个维度;生成对话时,根据角色特征自动匹配最合适的参考音频,用 TTS 合成出来。
最后出来的不是随便拼的假数据,是特征匹配的、上下文连贯的模拟对话音频。
说白了,他们把"怎么造好的训练数据"这个问题也一起解了。
快速上手
模型基于 Qwen3-Omni-30B-A3B-Instruct,推理用 vllm-omni,权重放在 HuggingFace 和 ModelScope 都有。
环境配置:
git clone https://github.com/Soul-AILab/SoulX-Transcriber.git
cd SoulX-Transcriber
conda create -n soulx_transcriber python=3.12 -y
conda activate soulx_transcriber
pip install ms-swift
推理:
# 先下好模型权重
source your_env_path/vllm_omni/bin/activate
bash ./inference.sh
vllm-omni 的安装步骤稍微长一点,README 里有完整命令,跟着走就行。需要一台有 GPU 的机器,30B 的模型对显存有要求,跑之前确认一下。
说在最后
如果你在做会议纪要、访谈转录、播客切片、电话质检这类场景,目前市面上的工具最大的痛点就是说话人混乱——识别率不差,但不知道这句话是谁说的。
SoulX-Transcriber 把这个问题在精度上推到了一个新台阶。
Soul App 有真实的语音社交业务做支撑,西工大 ASLP 实验室是国内语音方向的顶级团队,这个合作出来的东西可信度够高,不是玩具级的。
项目地址:https://github.com/Soul-AILab/SoulX-Transcriber Demo 页面:https://soul-ailab.github.io/soulx-transcriber/ HuggingFace:https://huggingface.co/Soul-AILab/SoulX-Transcriber
