 夜雨聆风
夜雨聆风OpenAI 给 ChatGPT 的记忆系统起了一个很有画面感的名字:Dreaming,做梦。
这不是说模型真的拥有梦境,也不是一层玄学包装。按 OpenAI 的说法,Dreaming 是一个后台记忆综合系统:它会在聊天之外,整理用户过去的对话、偏好、项目和约束,让下一次对话不必每次都从零开始。
换句话说,ChatGPT 的记忆正在从“用户让我记住什么”,变成“系统在后台持续整理我该知道什么”。这一步,比看上去重要得多。

以前的记忆,像一张便签
ChatGPT 的 memory 最早在 2024 年 4 月上线,当时叫 saved memories。用户可以明确告诉它:“记住我七月要去新加坡”“记住我不吃香菜”“记住我正在做某个项目”。
这个设计很直观,也很容易理解:模型旁边放了一张便签纸。你说“记住”,它就写上去;下次再问,它把便签拿出来参考。
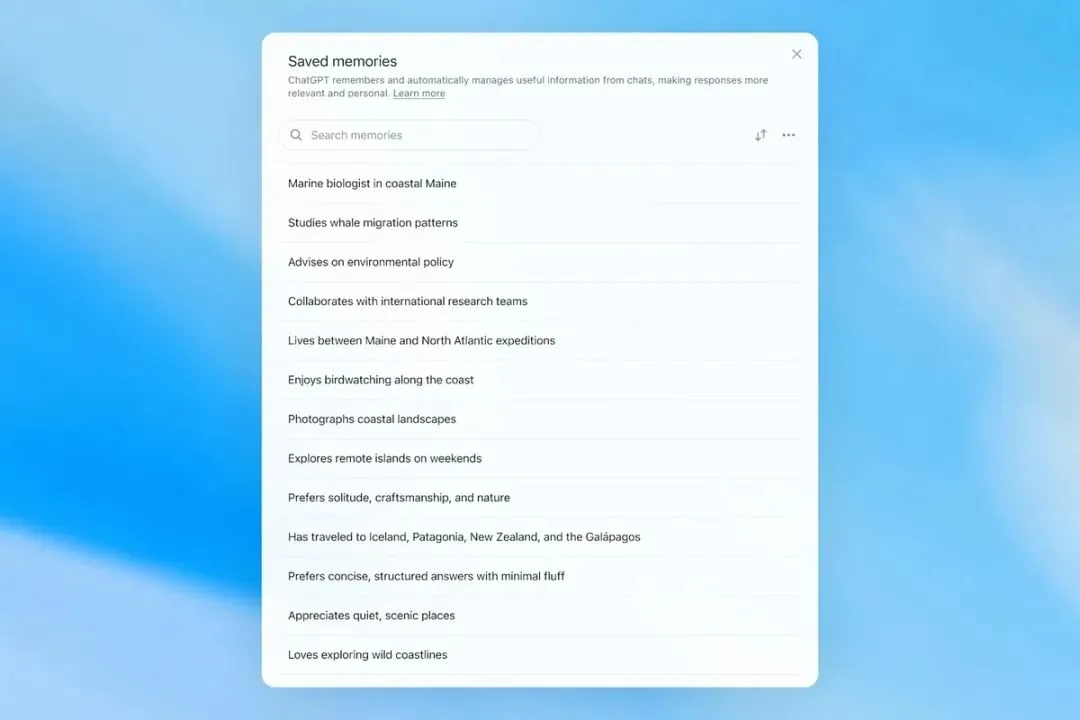
Saved memories 页面
问题也很明显。第一,很多重要信息并不会以“请记住”的形式出现。人和助理交流时,不会每说一句都附带一句“请写进档案”。第二,便签会过期。你七月要去新加坡,八月以后就不应该再被当成未来计划。第三,便签之间会打架。你可能先说自己在练马拉松,后来又说脚踝受伤,如果系统只是把两条都存着,下一次建议就可能变得很怪。
OpenAI 自己也承认,saved memories 容易变旧,最终变得不正确或不相关。真正的问题不是“能不能记”,而是“记忆会不会自己更新”。
Dreaming:后台整理你的上下文
2025 年,ChatGPT 的 memory 加入第一版 Dreaming。它不再只看 saved memories 列表,而是可以参考更广的聊天历史,在后台自动整理用户上下文。
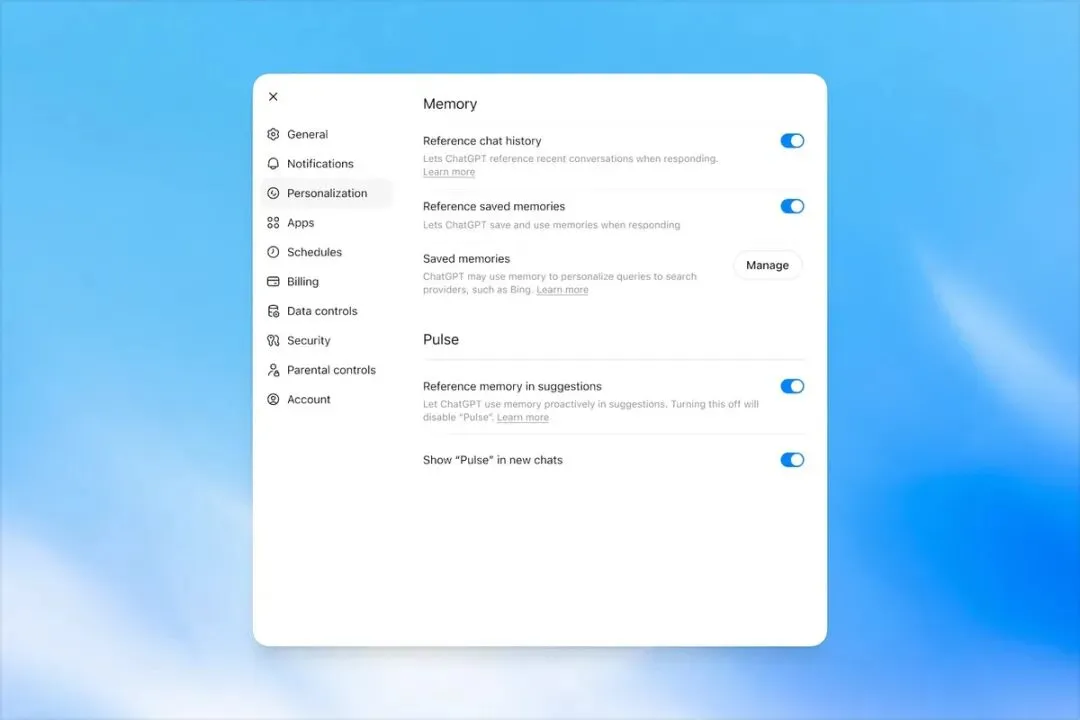
Memory settings 页面
到了 2026 年 6 月,OpenAI 宣布推出更强、更省算力的 Dreaming V3,并把它作为新的 memory architecture。官方给出的目标是三个词:freshness、continuity、relevance。翻译过来是:记得新、接得上、用得准。
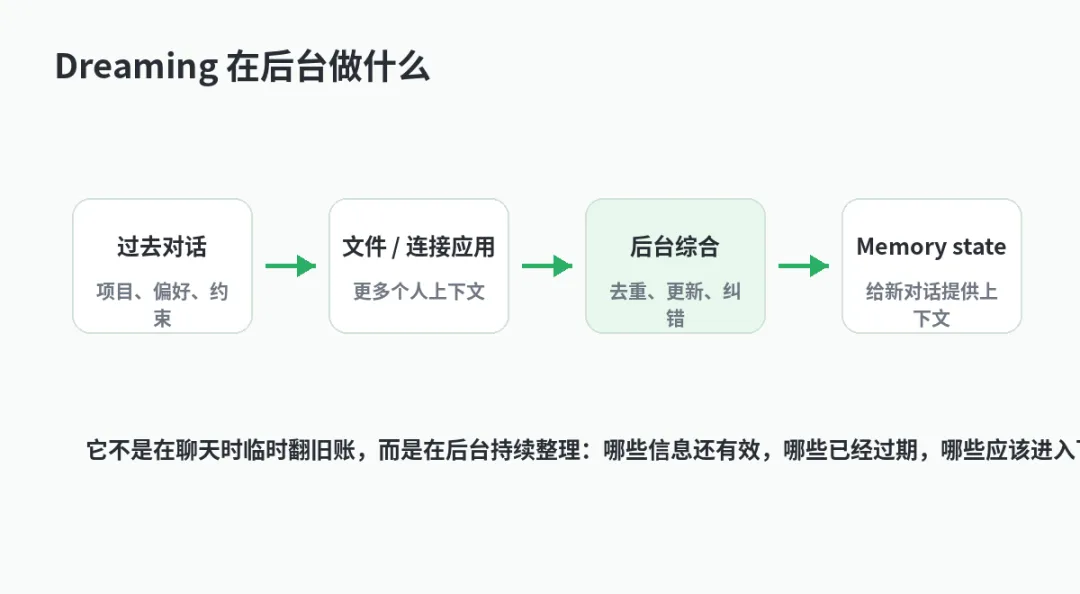
这套系统的关键变化,是记忆不再只发生在一段对话里。用户没有显式说“记住这个”,系统也可以从多次对话中综合出稳定信息:你正在做什么项目、偏好什么风格、有哪些限制、哪些事情已经过去。
一个典型例子是设备采购。没有记忆时,用户问“我的水下摄影设备要买什么 TTL 配件”,模型只能泛泛讲相机、潜水壳、闪光灯、触发器之间的兼容关系。有记忆时,模型会知道用户具体用的是 Sony A1 II、Nauticam NA-A1II、Backscatter Mini Flash 3 和 Inon Z-330,于是直接给出对应配件建议。
这就是 memory 的价值:它不是让回答多一点“亲切感”,而是把泛泛而谈变成具体决策。
怎么判断记忆有没有变好
这套记忆系统主要看三个指标。它们也基本概括了长期 AI 助理该具备的能力。

第一,带上有用上下文。你不需要在每个新会话里重新介绍自己。尤其是长期项目,比如代码工程、旅行计划、论文写作、公司调研,真正麻烦的不是单次回答,而是每次都要把背景再讲一遍。
第二,遵守偏好和约束。比如你是素食者、讨厌拥挤餐厅、喜欢安静晚餐、做方案时偏好表格还是短段落。这些信息不是知识题,但会直接影响建议质量。
第三,跟上时间。时间是旧 memory 最大的敌人。“我下周六办生日派对”在下周五是未来计划,在周日就应该变成已经发生的事。“我七月去新加坡”旅行结束后,也不该永远停留在“即将出发”。
这三个目标放在一起看,Dreaming 要解决的不是一个功能问题,而是一个状态维护问题。它要维护一个不断变化的“用户模型”。
为什么现在连免费用户也要上
这次更新还有一个很实际的信号:Dreaming 不再只是付费用户的小范围体验。OpenAI 表示,美国 Plus 和 Pro 用户已经开始获得新系统,未来几周会扩展到更多国家,并逐步面向 Free 和 Go 用户开放。
原因很直接:算力成本降下来了。OpenAI 称,最近的改进让向免费用户服务 Dreaming 所需的计算量降低了大约 5 倍。同时,Plus 和 Pro 用户的 memory capacity 翻倍。
这个细节很重要。记忆系统不是简单多存几行文本,它需要读取、筛选、综合、更新,还要在新对话中判断哪些上下文该带进来。用户规模一旦到数亿,记忆就会变成一项昂贵的基础设施。
所以 Dreaming V3 的意义不只是“更聪明”,也是“更便宜”。只有当后台记忆综合的成本足够低,AI 助理才可能变成默认体验,而不是少数高端用户的特权。
从聊天工具到个人上下文系统
过去两年,大模型的竞争主要发生在单次对话里:谁推理更强,谁写代码更好,谁上下文窗口更长,谁幻觉更少。
但真正的私人助理,不只看单次回答。一个助理最大的价值,往往来自它知道你是谁、正在做什么、哪些东西不用重复讲、哪些偏好不能踩。
这也是为什么 memory 会越来越重要。没有记忆的 AI 像一个非常聪明但每天失忆的实习生;有了可更新、可纠错、可控制的记忆,它才开始像一个能长期协作的伙伴。
Dreaming 把这件事推进了一步。它把记忆从“显式保存的条目”,变成“后台持续运行的上下文综合”。这意味着 ChatGPT 不只是回答用户的问题,而是在慢慢维护一个关于用户的工作图谱。
AI 助理的分水岭,不是它更会说话,而是它能否长期、准确、可控地理解一个人。
更强记忆,也带来更复杂的隐私边界
记忆越像助理,隐私问题就越不能轻描淡写。OpenAI 这次也同步强调了 memory summary 和 sources。
Memory summary 是一个摘要页面,用户可以看到 ChatGPT 认为自己知道你的哪些重点信息,也可以添加、更新,或者告诉它某些话题什么时候该提、什么时候别提。Sources 则会在回答下方显示用于个性化的来源,比如 custom instructions、过去聊天、文件和 memories。
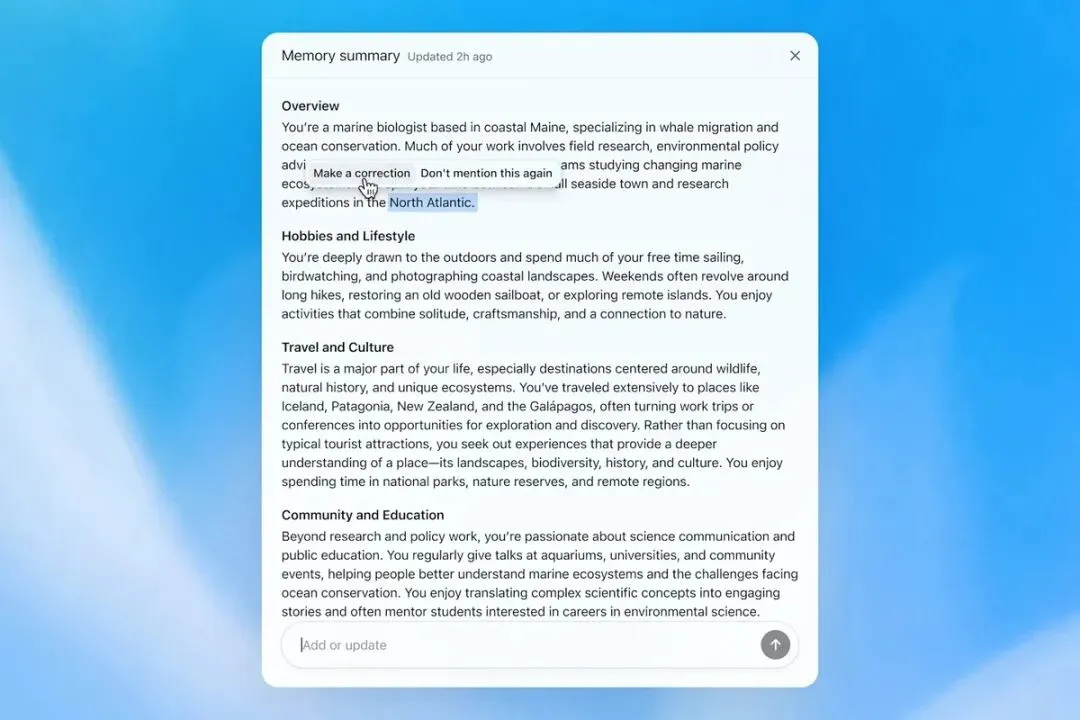
Memory summary 页面
但这里有几个细节必须看清。第一,memory summary 不包含所有记忆,它只是高层摘要。第二,sources 也不保证展示所有影响回答的因素。第三,“Don’t mention this again”只是减少未来提及,不等于删除信息。
如果你真的想彻底删除某个信息,OpenAI Help Center 的说法是,要从每一个来源删除:过去聊天、归档聊天、文件、memory summary,以及可能包含该信息的 connected apps。这个过程显然比“删掉一条记忆”复杂得多。
Temporary Chat 仍然是最简单的隔离方式:它不使用现有 memories,也不创建新的 memories。对于敏感话题,这个选项会越来越重要。
“忘得对”会和“记得准”一样重要
很多人讨论 AI memory 时,只关注“记住更多”。但真正成熟的记忆系统,重点未必是更多,而是更准确、更及时、更可解释。
错误的记忆比没有记忆更麻烦。没有记忆时,模型最多回答泛泛;错误记忆会让它自信地给出不适合你的建议。过期记忆同样危险,因为它把过去的状态伪装成现在的现实。
所以 Dreaming 的关键不是让 ChatGPT 变成一本越来越厚的个人档案,而是让它学会动态整理:哪些信息该提升权重,哪些已经过期,哪些互相矛盾需要澄清,哪些敏感内容不该主动提起。
这也是未来 AI 产品的一条主线:模型能力之外,谁能把“长期上下文”做得更可靠,谁就更接近真正的个人助理。
结尾:AI 开始有了“第二天”
过去的 ChatGPT 更像一次性工具。你打开一个窗口,问一个问题,得到一个答案,然后结束。
Dreaming 代表的方向是:AI 开始拥有跨会话的连续性。今天说过的话,明天可能还在;上个月的项目背景,下个月还能接上;已经过期的计划,也应该被系统主动更新。
这就是“做梦”这个名字有意思的地方。人做梦不是为了回答问题,而是在睡眠中整理白天的经验。OpenAI 借用这个词,指向的正是同一件事:模型在对话之外整理上下文,让下一次醒来时更懂你。
当然,这也意味着我们需要新的使用习惯:什么该让 AI 记住,什么该临时聊,什么必须删除,什么只是别再提。
AI 记忆进入后台时代以后,真正重要的问题会变成:它不只要记得准,还要忘得对。
如果这篇文章对你有帮助,点个赞、转发给朋友,是最直接的支持。
