 夜雨聆风
夜雨聆风
前两天在一个做企业 AI 落地的群里,有人甩出一个问题,底下一串"+1":
"我们想把公司这些年攒的合同、报告、扫描件都喂给 AI 做个问答系统。结果卡在第一步——光是把 PDF 变成 AI 能读的文字,就冒出来 MinerU、Docling、Marker、liteparse 一大堆工具,到底该用哪个?"
问得特别实在。这其实是现在每一个想用 AI 处理文档的团队,绕不开的第一道坎。
我把 2026 上半年最火的几个开源文档解析工具,连同它们的公开实测数据、官方设计思路、企业落地反馈,全扒了一遍。先把结论抛给你:这里没有"哪个最好",只有"哪个适合你的场景"。而很多人第一步就选错,根本原因是——把"给知识库入库"的需求,和"给 AI agent 迭代扫"的需求,当成了同一件事。
这篇大概 3000 字,帮你把 5 个主流工具按企业真实场景分好类,附一张选型对照表和一个决策树。看完你大概率不会再装错。
先说清楚:这不是我逐个在生产环境跑了一个月的横评——那得花好几周。这是我把它们的实测、文档、落地案例吃透后,按选型逻辑给你理清楚。真要上生产,文末我给了怎么自己花半天快速验证。
一、为什么"文档解析"是喂 AI 的第一道坎
你可能会想:不就是把 PDF 转成文字吗,有那么复杂?
有。而且这一步直接决定了你后面所有 AI 效果的天花板。
道理很简单:垃圾进,垃圾出。一份排版复杂的财报,如果解析时把三栏排版串成了一锅粥、把表格拆得七零八落、把公式变成乱码,那不管你后面用多强的大模型,它读到的都是一堆烂数据,问什么都答不准。
而真实世界的企业文档,恰恰全是"难啃"的:合同有盖章和手写批注,财报有大量跨页表格,论文有公式,扫描件还是图片不是文字……把这些准确、有结构地变成 AI 能消化的内容,就是文档解析工具在干的活。
理解了这层,再看工具就清楚了。这些工具其实分成两个流派,搞混它们,就是大多数人选错的根源。
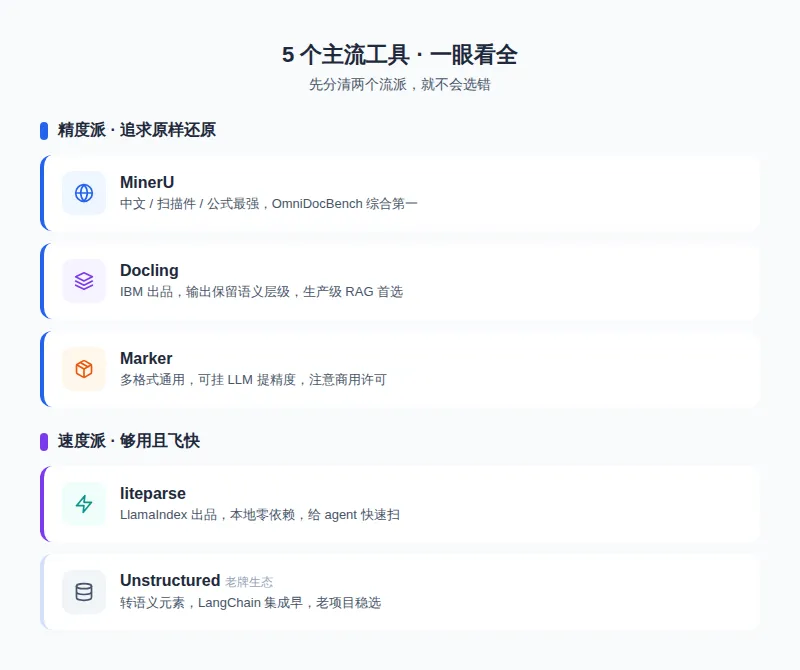
两种范式:精度派 vs 速度派
精度派(MinerU、Docling、Marker):用重型模型,追求把文档"原样还原"——版式、表格、公式、阅读顺序,能多准就多准。
速度派(liteparse 是代表):故意不追求最高精度,主打一个"够用且快"。
打个比方你就懂了:
精度派像请了个专业速记员,逐字逐句一丝不苟地誊抄整本书——慢,但你拿到的是完整准确的副本。 速度派像你自己先快速翻一遍,抓住重点和关键页,需要细节时再回头精读那几页——糙,但快得多。
到底该请速记员,还是自己快速翻?取决于你拿这些文字干嘛。 这就引出了下面的选型逻辑。
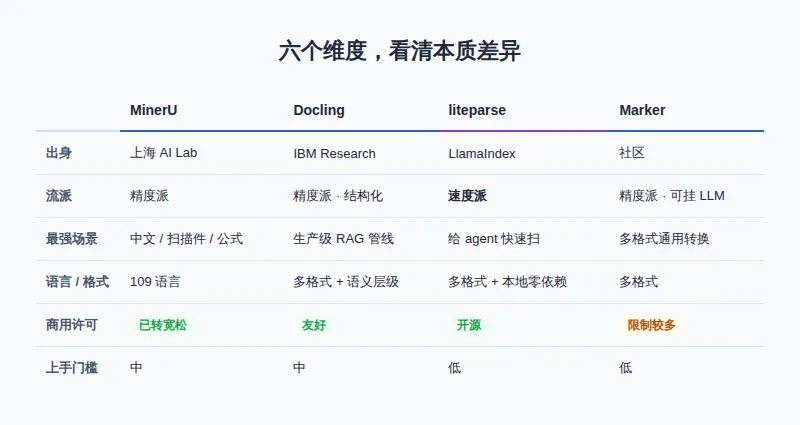
先上一张总览,6 个维度看清这几个工具的本质差异(这张表也是你后面对照的兜底):
二、按企业场景,对号入座
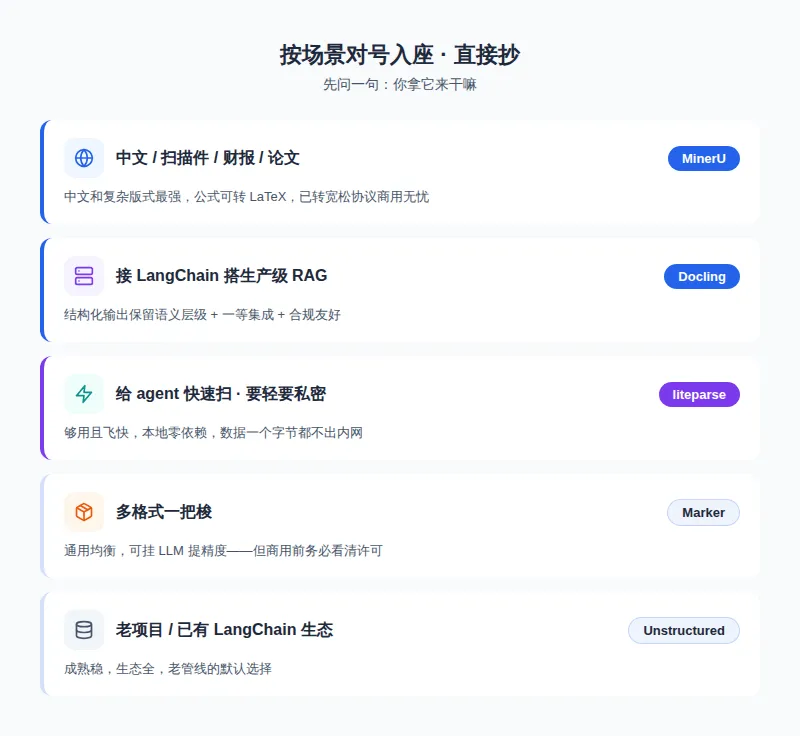
下面四个场景,对应企业里最常见的四类需求。看你的活儿落在哪个,直接选对应的主角。
场景 A:大量中文文档、扫描件、带公式表格 → MinerU
如果你要处理的是中文合同、财报、研报、学术论文、扫描件这类"又中文又复杂"的文档,MinerU 基本是目前的第一选择。
它是上海 AI Lab(opendatalab)开源的,GitHub 星标在这几个里最多,不是没道理:
在权威的 OmniDocBench 评测里,它综合排第一,中文文本识别的错误率(0.215)和英文(0.061)都是最低的一档; 公式能直接转成 LaTeX,跨页大表格、页眉页脚清理、旋转版式这些"中文文档老大难",它处理得最好; 支持 109 种语言; 还有一个企业最关心的点:它在 3.1 版本把许可证从有"传染性"的 AGPLv3,换成了基于 Apache 2.0 的宽松协议,明确允许商用。这一步直接扫清了很多公司不敢用的顾虑。
一句话:中文为主、版式复杂、还要商用——闭眼选它。
场景 B:要接进 LangChain / LlamaIndex 搭生产级 RAG → Docling
如果你的目标是搭一套正经的、要长期跑在生产环境的企业知识库问答系统,而且技术栈已经在用 LangChain 或 LlamaIndex,那 Docling 更顺手。
它是 IBM Research 出品、现在挂在 LF AI & Data 基金会下,定位就是"为生产 RAG 而生":
它不只是吐出一堆文字,而是输出一个保留了语义层级的结构化文档——标题、章节、表格的从属关系都在,这对后面做精准检索特别关键; 支持 PDF、Word、PPT、Excel、HTML 甚至音频; 和主流 AI 框架是一等公民级的集成,接起来不折腾; 适合气隙(断网)环境,数据不出内网,合规友好。
一句话:要搭企业级、长期维护的 RAG 系统,且重视结构和合规——选它。
场景 C:给 AI agent 用、要快要轻、数据不能外传 → liteparse
这个是今天的新秀,也是最容易被"精度派"思维带偏的一个。它是 LlamaIndex 刚推出的,这两周在 GitHub 爆涨。
它的特别之处,全在设计哲学上——也是我觉得这篇里最值得你记住的一个判断:
不是每份文档都需要被最高精度地解析。AI agent 本身是迭代的:它先拿到粗糙但飞快的文本,扫一遍、判断哪几页相关,再回头对那几页做深度解析。真正的瓶颈往往不是解析质量,而是解析速度。
一个能在 100 毫秒内拿到"糙但够用"文本的 agent,可以快速扫几十份文档、锁定关键页,再选择性深挖——整体效率反而碾压"每份都死磕精度"的方案。
落到工程上,liteparse 也很对企业胃口:
- 零 Python 依赖
,CLI + TypeScript 原生,完全本地运行,一个字节都不传云端; 用"空间文本解析"保留原始排版(靠缩进和空白还原布局),还带位置坐标; 隐私敏感、断网环境、想省掉按页计费的云 API 成本——它都很合适。
一句话:给 agent 当"快速侦察兵"、看重速度和隐私——选它。别拿评测精度去苛求它,那不是它的赛道。
场景 D:多种格式一把梭、想一个工具全搞定 → Marker(附老牌 Unstructured)
如果你的文档格式很杂,又不想为不同格式配不同工具,想要"一个工具通吃",Marker 是个均衡选择。它结构还原和图表处理都不错,还有个 --use_llm 开关,能临时挂上大模型把精度拉到很高。
但有个坑必须提醒:Marker 的许可证限制比别家多,商用前一定先把授权条款看清楚,别等系统跑起来了才发现踩了红线。
另外,老牌的 Unstructured(14.6k 星)也值得知道:它把文档转成带语义标签的元素,和 LangChain 集成早、生态成熟,是不少老项目的默认选择。
三、一张表 + 一个反共识,帮你避开最大的坑
把上面的浓缩成一张速查表:
然后是这篇最想让你记住的一句反共识判断:
解析精度不是越高越好,要看下游是谁在用。 给知识库入库、要长期反复检索的,精度值得死磕;给 agent 临时扫一遍找线索的,精度够用就行,硬上重型工具只会白白慢 10 倍。把这两件事分清楚,你就赢过了一半的团队。
还有一个企业最容易栽的坑:"开源"不等于"能免费商用"。 像早期 MinerU 用的 AGPLv3、以及 Marker 的某些限制,都可能让你的商业产品踩雷。选型时,许可证要和功能放在一起看,这是工程师容易忽略、但老板一定会问的事。
四、给你一个决策树和我的建议
如果还是懒得纠结,照这个走:
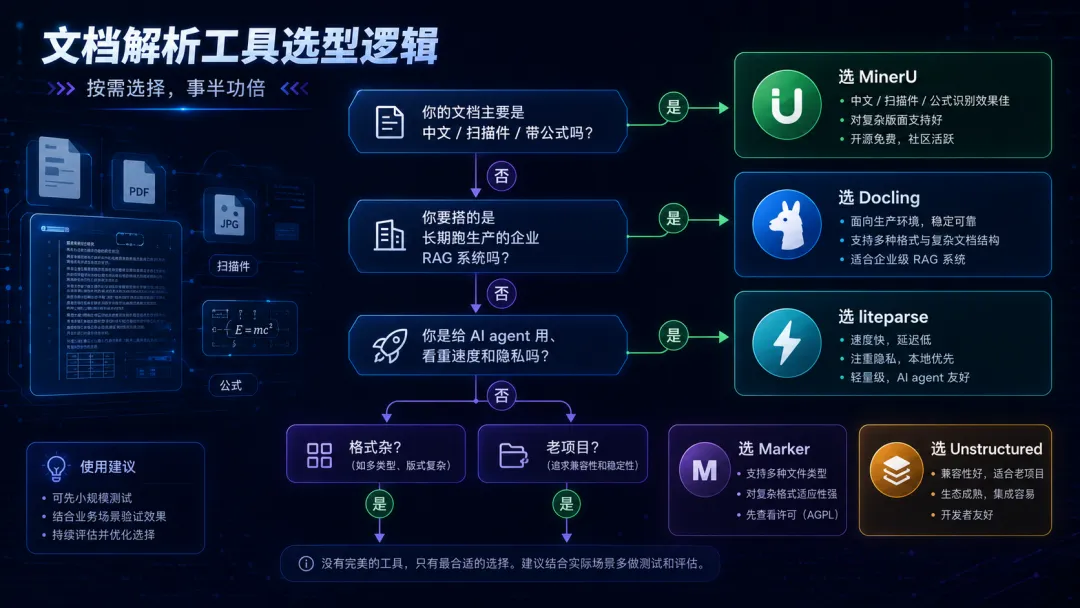
三个最常见的选型误区,对照着避开:
- 只看 GitHub 星数选
——星多代表受欢迎,不代表适合你的格式。MinerU 星最多,但你全是英文规整 PDF,未必比轻量工具划算。 - 忽略许可证
——这是隐形地雷,商用前必查。 - 盲目追精度
——给 agent 扫的场景,高精度用不上,还拖慢整条链路。
我自己会怎么选? 坦白说我没在生产环境把这 5 个全压测过。但从实测数据和设计取向看,如果让我现在起一个新项目:中文文档为主就 MinerU,搭正经知识库就 Docling,做 agent 工作流就 liteparse——而且我会先拿自己最典型的 3 份文档,用候选工具各跑一遍,半天就能看出差距,这比看任何评测都靠谱。
如果你只能记一句话带走:
给知识库入库 → 选精度派(MinerU / Docling);给 agent 迭代扫 → 选速度派(liteparse)。两类都干,就别纠结,按文档类型分着用。
五、写在最后:这件事对职场人意味着什么
你可能会说,我又不写代码,了解这些工具干嘛?
恰恰相反。"文档解析怎么选型"这种以前躺在工程师后台的事,正在变成所有想用 AI 干活的人,必须有判断力的地方。
因为今天你想用 AI 搭一个能问答的知识库、做一个能读合同的助手、搭一条自动处理文档的工作流——第一步就撞上它。你不需要会自己写解析代码,但你得能判断:我的场景该要精度还是要速度?这个工具能不能商用?数据要不要出内网?
这种判断力,本质上是 AI 时代的一种新基础能力——不是"会不会用某个工具",而是"能不能在一堆工具里,按自己的真实需求做出正确取舍"。 工具每个月都在变,但这套"看场景、看约束、做取舍"的选型思维,是会一直增值的。
下次再有人在群里问"这俩选哪个",希望你能像今天这样,先反问一句:"你拿它来干嘛?" ——这一问,你就已经超过大多数人了。
数据与资料来源:OmniDocBench / DocLayNet 公开评测、各项目官方文档与 LlamaIndex 博客、2026 年多篇开源文档解析横评。
