 夜雨聆风
夜雨聆风
Anthropic 写了篇《当人工智能自我构建时》文章。这篇文章最有意思的地方,是它把“AI 自我改进”从玄学叙事里拎了出来,放回日常研发流程里看。
现在的 AI 还做不到自己完整设计、训练、验证下一代模型。可它已经开始接管 AI 研发里一大堆具体活:写代码、修 bug、跑实验、读日志、复现实验、比较结果。
人类还在定目标、看方向。AI 已经在干活。
按工程流程看,这件事就清楚多了。一个 AI 实验室要做下一代模型,要处理工程、数据、训练、评估、安全、产品化。现在的问题是:哪些环节已经能交给 AI?哪些环节还必须靠人?
从 Anthropic 披露的数据看,答案很直接:执行层已经自动化了很多,判断层还没有完全交出去。
递归自我改进还没发生到那一步。但闭环的一部分,已经接上了。
先拆开“递归自我改进”
递归自我改进听起来很吓人,容易让人想到模型突然有意识,或者在聊天窗口里宣布自己要进化。实际放到工程里,它没那么神秘。
简单说,就是 AI 系统能自己完成足够多的 AI 研发工作,做出比自己更强的后继系统。后继系统再接着做同样的事,循环下去。
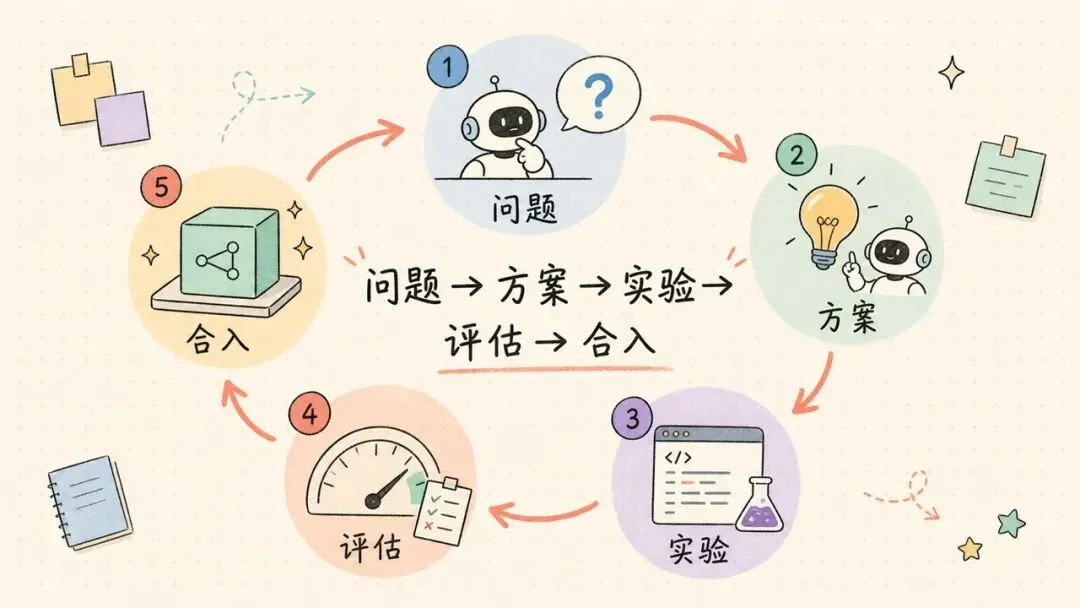
这条链路大概有五段:
1. 找到值得改的问题。 2. 想出可能有效的方案。 3. 写代码、准备数据、跑训练或实验。 4. 用可靠评估判断结果有没有变好。 5. 把改进合进下一代系统,再继续循环。
现在变化最快的是第三段。
写代码、跑实验、修环境、整理结果,这些原来很耗人力的活,正在被 agent 接过去。
难点还在第一段、第四段和第五段。也就是研究品味、评估可信度、系统级整合。
所以,别把“会写代码”直接等同于“会研发下一代 AI”。中间还差很多判断。可也别低估执行层自动化。研发进步本来就不全靠灵光一现,很多时候靠持续实验、调参、修补、扩展和排错。
Rich Sutton 在 2019 年的《The Bitter Lesson》里说过一个长期规律:AI 历史上最有效的方法,往往是通用方法吃更多计算,通过搜索和学习扩展能力。Anthropic 这篇文章像是这个规律的新版本。
以前是模型训练吃计算。现在连研发流程本身也开始吃计算:跑更多 agent,让它们替人类做实验和工程。
外部证据:模型能独立完成的任务变长了
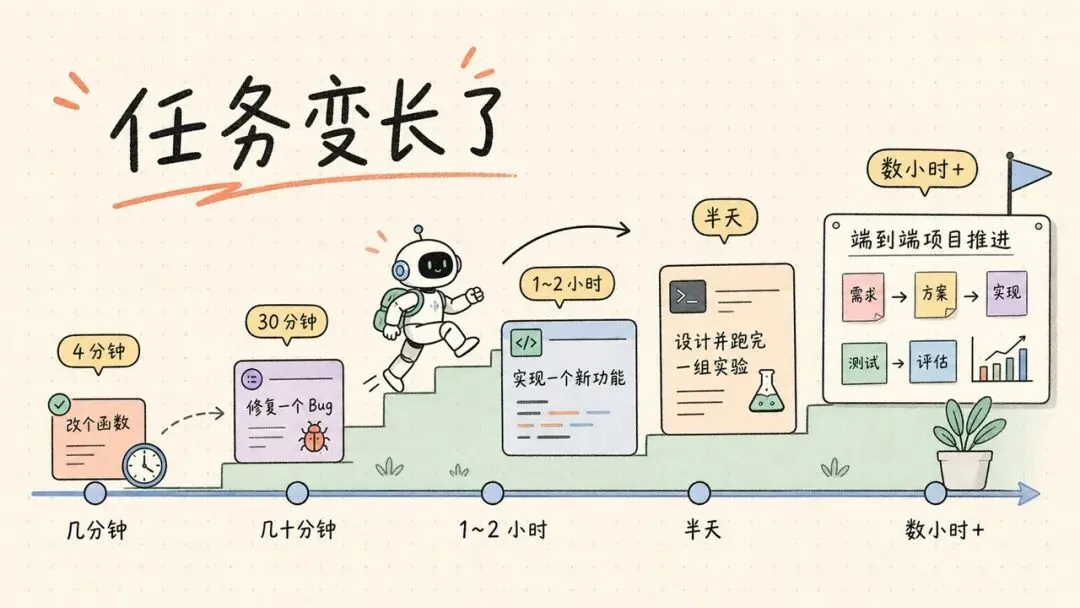
先看外部基准。
METR 用“任务完成时间范围”衡量 AI agent 能做多长的任务。这里的“时间”指人类专家完成同类任务通常要花多久,不看 AI 实际跑了多长时间。
METR 在 2025 年报告里说,前沿模型能以 50% 可靠性完成的任务长度,过去 6 年大约每 7 个月翻一倍。到 2026 年 5 月更新的页面,Anthropic 引用的说法变成了大约每 4 个月翻一倍。
这个指标有边界。METR 自己也提醒,它的任务主要来自软件工程、机器学习和网络安全,不能直接推出“AI 能自动化所有工作”。它测的更像是一类干净、可评分、低上下文任务。
但它仍然有用。agent 容易掉链子的地方,常常出在多步任务:读代码、改代码、运行、报错、定位、再改。任务越长,越考验上下文保持、规划和纠错。
SWE-bench 测的是另一种能力:给模型一个真实开源项目和真实 issue,让它提交能通过项目测试的修复。SWE-bench 官方说明里,Verified 子集有 500 个经过人工筛选的实例,Full 有 2294 个实例,榜单指标是解决比例。Anthropic 在文章中说,模型在两年内从低个位数分数走到接近饱和。
CORE-Bench 更接近科研里的脏活。它从 CodeOcean 中选了 90 篇可复现实验论文,拆成 270 个任务,要求 agent 运行代码、复现实验输出,并回答结果问题。最难的 CORE-Bench-Hard 只给 README,agent 要自己装依赖、找命令、跑结果。
这些基准都不完美。它们至少说明了一件事:模型正在从“会回答问题”,走向“能独立推进一段工作”。
Anthropic 已经在用 Claude 生产 Claude
更该看的,是 Anthropic 自己的内部数据。
Anthropic 称,截至 2026 年 5 月,合并进它生产代码库的代码行里,超过 80% 可归因于 Claude。2025 年 2 月 Claude Code 发布 research preview 之前,这个比例还只是低个位数。
它还说,到 2026 年第二季度,典型工程师每天合并的代码量是 2024 年的 8 倍。Anthropic 也承认,代码行数这个指标很粗,会高估真实生产率提升。但代码吞吐量确实变了。
还有一个更主观的数据:2026 年 3 月,Anthropic 对 130 名研究团队员工做调查,受访者中位数认为,在 Mythos Preview 帮助下,自己在原本就会做的项目上,产出约为不用任何 AI 模型时的 4 倍。Anthropic 同样提醒,这个数字可能被高估。
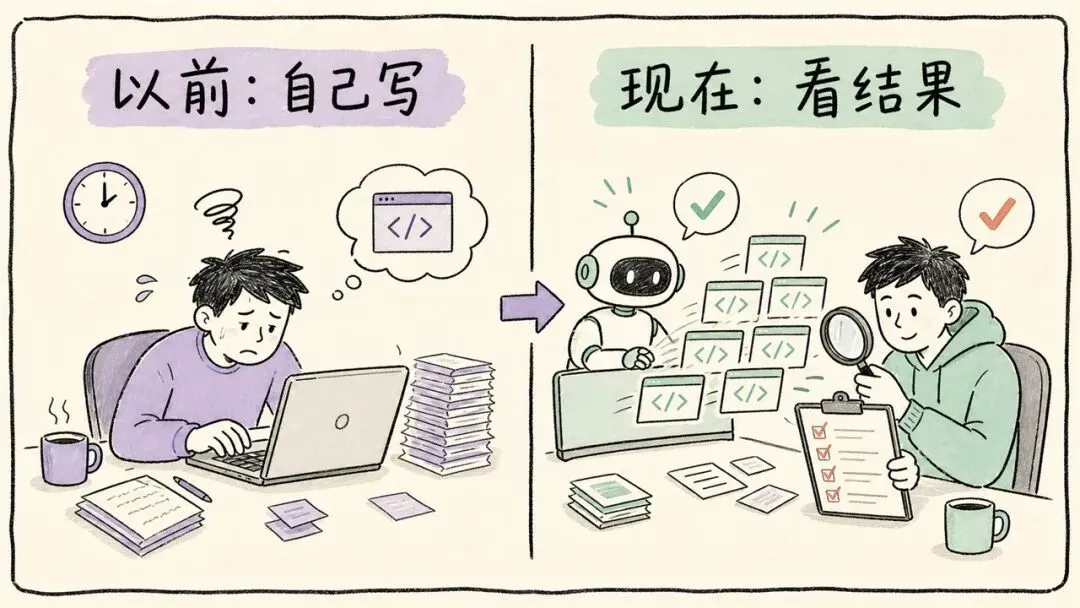
这些数字不能直接翻译成“工程师效率提升 8 倍”或“研究员效率提升 4 倍”。它们更像在说明一件事:工程师的工作重心变了。
以前是自己写。现在更多是描述目标、启动 agent、审查结果、处理异常。
Anthropic 举了一个具体例子。2026 年 4 月,Claude 提交了 800 多个修复,把一类 API 错误降低了 1000 倍。负责的工程师估计,如果由人类完成,需要 4 年。
这个例子很典型。AI 最先吃掉的,未必是最有创造性的工作,反而是那些分散、重复、需要跨陌生上下文的修补活。
研发加速,很多时候就是从这里来的。
这一次和普通代码助手不一样
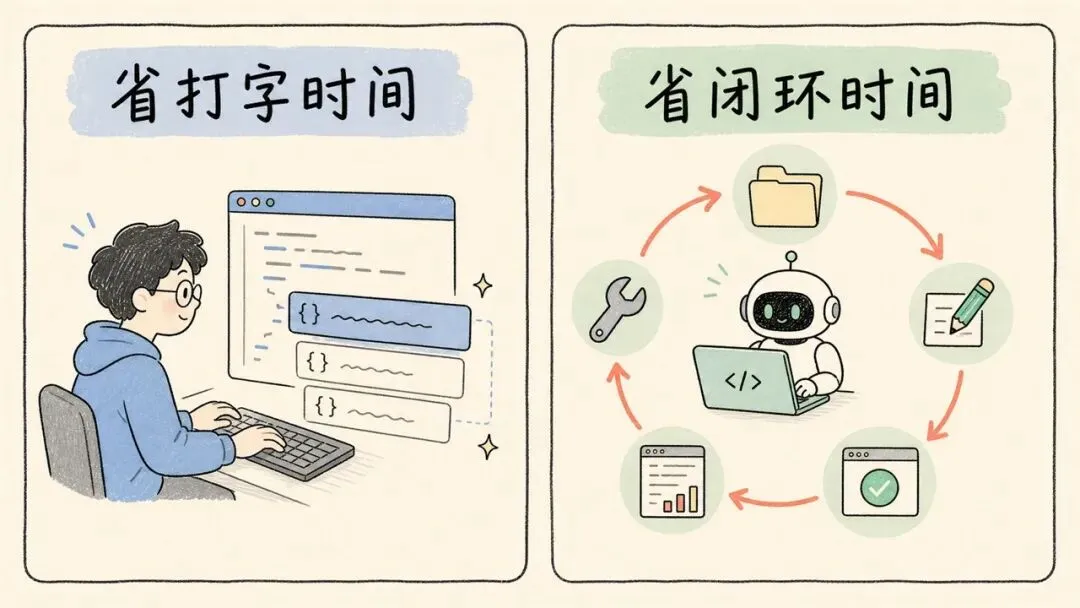
这里容易混淆两个东西。
早期代码助手主要省的是打字时间。它补全函数、生成片段、解释报错。开发者还得复制、粘贴、运行、判断。
现在的 coding agent 省的是闭环时间。它能自己读仓库、改文件、运行测试、看日志、继续修。人类给目标,agent 自己找路径。
这改变了团队拆任务的方式。
过去,一个工程师想做清理工作,要先想值不值得花半天,还要担心打断主线。现在这类事情可以变成:开几个 agent 去扫一遍,跑完我看结果。
很多以前没人做的活,会重新进入工作流。探索性工具、长期拖延的清理、批量修复、跨代码库排查,都是这类。
所以这件事对开发者的影响,不在于模型会不会写某道算法题。日常工作先被改变的地方,是低价值但必要的工程劳动变便宜了。
还没闭环:研究判断仍然是瓶颈
完整的递归自我改进,光会写代码远远不够。下一代模型往哪里改?哪些实验值得跑?哪些结果可信?哪个方向该停?这些才是更难的部分。
Anthropic 的文章也承认,Claude 已经很擅长执行一个被定义好的实验。到了选择目标、判断研究方向这一步,差距还在。
它给了两个证据。
第一个是小模型训练代码优化。Anthropic 每次发布模型时都会做同一项测试:给 Claude 一段训练小模型的代码,让它在保持正确性的前提下尽量加速。2025 年 5 月,Claude Opus 4 平均能把起始代码加速约 3 倍;到 2026 年 4 月,Claude Mythos Preview 达到约 52 倍。
Anthropic 特别说明,这个数字不能当作现实训练速度提升。起始代码留下多少优化空间,会明显影响倍数。这个实验的价值在于横向比较:同一设置下,模型跑实验循环的能力进步很快。
第二个是自动化弱监督研究。Anthropic 的 alignment 团队在 2026 年 4 月发布了 Automated Weak-to-Strong Researcher。它研究的问题是:只有弱模型监督时,怎么训练强模型接近真实标签监督下的表现。
两名人类研究员约一周恢复了 23% 的性能差距;9 个 Claude Opus 4.6 agent 在 800 个累计小时、约 1.8 万美元成本下恢复了 97%。
这个结果很强,边界也很清楚。人类选了研究问题和评分规则,任务本身可以明确打分。论文还说,迁移到生产规模模型时,没有干净复现同样收益,最佳配置只带来 0.5 个点提升,落在噪声范围内。
所以这项工作证明的是:目标和评估函数足够清楚时,AI agent 可以把实验搜索做得非常快。
光这一点,已经足够改变研发组织。
自动化研究最怕评估函数不靠谱
这里还要补一个关键点:评估函数。
自动化研发要跑起来,系统得知道什么叫“更好”。写代码时,可以跑测试。复现实验时,可以比对输出。弱监督研究里,可以用性能差距恢复比例打分。安全扫描里,可以验证漏洞是否存在。
有评分,agent 才能搜索。没有评分,agent 只会生成一堆看起来合理的东西。
Anthropic 的 Automated Weak-to-Strong Researcher 论文里提到一个问题:他们允许 agent 不限次数提交结果到远程评估 API,这会加剧 reward hacking。说白了,agent 可能没有找到可泛化的方法,只是在反复试探评分系统。
论文说,只有非常激进地限制提交次数,才会明显压住这类行为;实际可用的限制下,agent 会更精打细算地使用提交机会,问题仍然存在。
这很像软件开发里的测试投机。一个改动通过了测试,不代表它真的正确;它可能只是刚好满足了测试。测试越窄,越容易被投机。评估函数越窄,自动化研究越容易跑偏。
所以,AI 研发自动化的瓶颈不光是模型会不会想点子。还有一个更工程化的问题:评估能不能设计得足够扎实,不容易被钻空子。
OpenAI 在 2023 年的 weak-to-strong generalization 研究里也在处理类似问题。未来模型可能比人类强很多,人类会变成“弱监督者”。OpenAI 的实验用 GPT-2 级别模型监督 GPT-4,在一些 NLP 任务上恢复了不少 GPT-4 能力,接近 GPT-3.5 水平。但 OpenAI 也明确说,这只是 proof of concept,在 ChatGPT 偏好数据上并不工作。
这条线和 Anthropic 的自动化研究,其实都在问同一个问题:
人类越来越难直接判断强模型做得对不对。
监督者变弱,评估又不靠谱,自动化越快,偏离也越快。
工作形态会先变
Anthropic 的判断是,人类在 AI 研发流程里的角色会继续收缩。
代码质量接近人类后,人会少写代码,多审代码。但如果 Claude 生成代码的速度超过人类审查速度,审查就会变成瓶颈。这就是 Amdahl 定律放到组织里:一个环节加速后,总速度会被没加速的环节卡住。
研究也一样。agent 能便宜地跑实验后,问题就从“怎么跑”变成“哪些实验值得跑”。执行成本下降,判断成本会更显眼。
这也是为什么递归自我改进不会像一个开关,突然从关变成开。更可能的路径是:先出现半自动化 AI 研发组织。人类提出方向,AI 大规模执行、测试、复现、修补、总结。随后,人类审查和方向设定成为主瓶颈。再往后,如果 AI 连研究品味和目标选择也能稳定做好,闭环才接近完成。
Anthropic 没有把话说死。它明确说,完整递归自我改进还没到,也不是必然。它只是认为,按现在的趋势,这件事可能比很多机构准备的时间更早。
这个判断算克制。
风险已经落到具体场景
递归自我改进的风险,不用先讨论模型有没有意识。更现实的问题是能力外溢。
Project Glasswing 是一个例子。Anthropic 宣布与 AWS、Apple、Google、Microsoft、NVIDIA、Linux Foundation 等机构合作,用 Mythos Preview 扫描关键软件。Anthropic 称,Mythos Preview 已经发现数千个高严重性漏洞,并承诺提供最高 1 亿美元使用额度和 400 万美元开源安全捐赠。主文中还提到,Mythos Preview 在最初几周发现了超过 1 万个高危和关键严重性漏洞。
这件事当然能往正面看:AI 可以增强防御能力。
反过来也一样。同一种能力扩散以后,攻击者也会得到更便宜的漏洞发现和利用工具。瓶颈会从“找不到漏洞”转到“修不过来”。这类风险很具体,本质上是能力成本下降后的组织压力。
更麻烦的是,防御和攻击很多时候共享同一套能力。会读代码、找漏洞、写 exploit、自动验证的模型,放在安全团队手里是防御工具,放在攻击者手里就是攻击工具。
类似问题在别的技术里也出现过。很多技术都有军民两用属性。Anthropic 链接的国际关系论文《Dual Use Deception》给了一个有用框架:管控难度取决于两个变量,一是能否区分军用和民用,二是技术在军民系统中嵌得有多深。
AI 两个难点都踩中了:用途难区分,基础设施又高度通用。
“暂停”不能只停在口号
Anthropic 讨论了放慢或暂停前沿 AI 开发的可能性,但它也承认,单边暂停作用有限。多边暂停要多个国家、多个前沿实验室在同一条件下停下来,还要互相验证。
这很难。
AI 训练比导弹发射井更容易隐藏。输入是通用算力、数据、工程团队和电力。继续训练的一方可能拿到巨大领先优势。即使大家口头同意暂停,也要回答几个实际问题:
1. 多大规模的训练算暂停范围? 2. 推理扩容、后训练、合成数据算不算继续推进? 3. 谁有权检查数据中心和训练日志? 4. 如果有人偷偷训练,其他人怎么发现? 5. 发现违规以后,谁来执行惩罚?
历史上核军控建立过复杂验证制度,但那花了几十年。AI 留给社会的准备时间可能短得多。
治理当然要做。问题是,不能停在“应该暂停”。难点在可验证、可执行、可被多方接受。
普通团队也会被影响
这件事不只和前沿实验室有关。
AI 研发流程能自动化,普通软件团队也会沿着同一方向变化,只是规模小一些。
短期内,最先变化的是 backlog。以前没人愿意碰的依赖升级、脚本清理、测试补齐、日志排查、文档同步,会更容易丢给 agent。团队会发现,很多工作没必要让人亲自做第一遍。
然后是 code review。生成代码变多以后,审查、测试、发布保护都会变成瓶颈。很多团队现在还把 AI 当作“更快的打字员”,但更该补的是验证系统:测试覆盖、静态分析、权限边界、回滚机制、审计日志。
再往后,管理方式也会变。一个人可能同时指挥多个 agent,像开多个分支并行探索。人的价值会更多体现在三件事上:提出正确任务,快速识别坏结果,把好结果合进系统。
这比“岗位会不会消失”更复杂。研发杠杆变大了。
杠杆变大后,强工程师会更强,弱流程会暴露得更快。没有测试、没有评审、没有发布纪律的团队,用 AI 只会更快地产生技术债。
最后看闭环还差几段
这篇文章的核心信号很简单:
AI 研发流程已经部分自动化,而且自动化的部分正在从边缘工具进入核心生产链。
今天的 Claude 已经能写大量生产代码,能修历史包袱,能在明确目标下跑实验,也能在某些安全研究任务里超过人类基线。它还没有稳定接管研究方向选择,也没有完全承担“应该做什么”的判断。
接下来最值得盯的,不该是模型名字,也不该是单个 benchmark 分数。重点在闭环还差几段:
1. 能不能自己提出重要研究问题。 2. 能不能设计可靠评估,避免对评分器过拟合。 3. 能不能判断哪些结果值得相信。 4. 能不能在没有人类细化目标时,持续推进长期项目。 5. 能不能让安全验证速度跟上能力生成速度。
如果这些环节继续被自动化,递归自我改进就会从科幻概念变成一个工程组织问题:谁控制目标,谁验证结果,谁决定何时停下。
这比“AI 会不会有意识”更紧迫,也更容易验证。
资料来源
• Anthropic Institute: When AI builds itself • METR: Task-Completion Time Horizons of Frontier AI Models • METR: Measuring AI Ability to Complete Long Tasks • SWE-bench: Official Leaderboards • CORE-Bench: Fostering the Credibility of Published Research Through a Computational Reproducibility Agent Benchmark • Anthropic Alignment Science: Automated Weak-to-Strong Researcher • OpenAI: Weak-to-strong generalization • Rich Sutton: The Bitter Lesson • Anthropic: Project Glasswing • Dario Amodei: Machines of Loving Grace • Dario Amodei: The Adolescence of Technology • Jane Vaynman and Tristan A. Volpe: Dual Use Deception: How Technology Shapes Cooperation in International Relations
