 夜雨聆风
夜雨聆风SkillOpt 教程 | 还不知道Skill是什么?一篇文章教你怎么全自动设计属于自己的Skill
SkillHub :将生信分析需求转化为精准 Skill 检索
上期回顾: Codex + CCSwitch + DeepSeek 的环境配置
给生信人的 AI 编程助手配置指南:Codex + CC Switch + DeepSeek
本期目标:
理解 Skills 的工作原理
将 bioSkills 部署到 Codex环境中
以 GEO 数据库中的真实数据集为例,完成一套标准的 bulk RNA-seq 差异表达分析
目录
一,bioSkills 介绍 二,Codex 部署 三,bioSkills 部署 四,实战:GSE52778 数据分析
一,bioSkills 介绍
1.1 什么是 skills
可以把 skills 理解成给 AI Agent 准备的“专业说明书”。
普通大模型虽然会写代码,但面对专业任务时,常常不知道这个领域真正该怎么做。skills 就是把这些行业规范、常见流程和避坑经验写进一个个 SKILL.md 文件里,让 Agent 在需要时自动查看。
1.2 skills 和 Agent 有什么区别
skills 不是新模型,也不是单独运行的软件。
它是给 Agent 加了一套专业知识库。Agent 还是原来的 Agent,但在遇到生信任务时,它可以按 bioSkills 里的规则来进行分析。
1.3 bioSkills 能帮什么忙
bioSkills 的价值是让 Agent 少犯低级流程错误。
对新手来说,你可以直接用自然语言描述任务,让 Agent 按生信分析标准流程搭好分析框架,再逐步学习每一步为什么这么做。
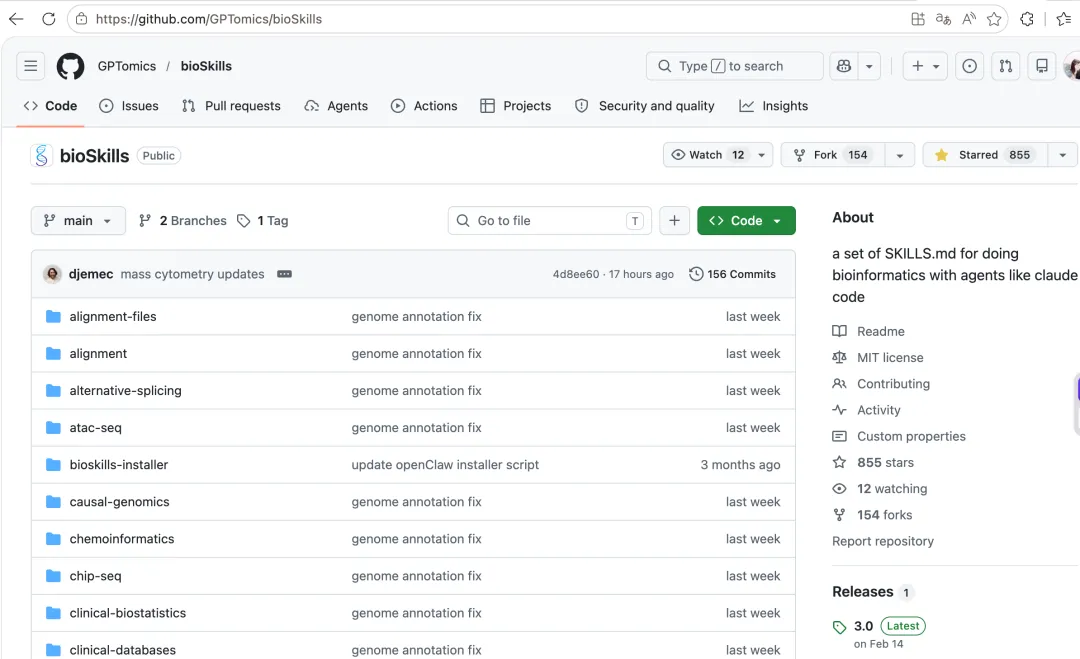
二,Codex 部署
具体可以参考上期推送:
给生信人的 AI 编程助手配置指南:Codex + CC Switch + DeepSeek
三、bioSkills 部署
部署 bioSkills 到 Codex
bioSkills 的安装本质上是将 SKILL.md 文件复制到 Codex 的 skills 路径中。推荐按项目需求选择性安装,可以参考之前的文章:
零代码时代!手把手教你怎么用Codex+Skills优化传统生信分析工作流
或者最简单也是最推荐的方法,直接让Agent为你代劳!(记得给权限)
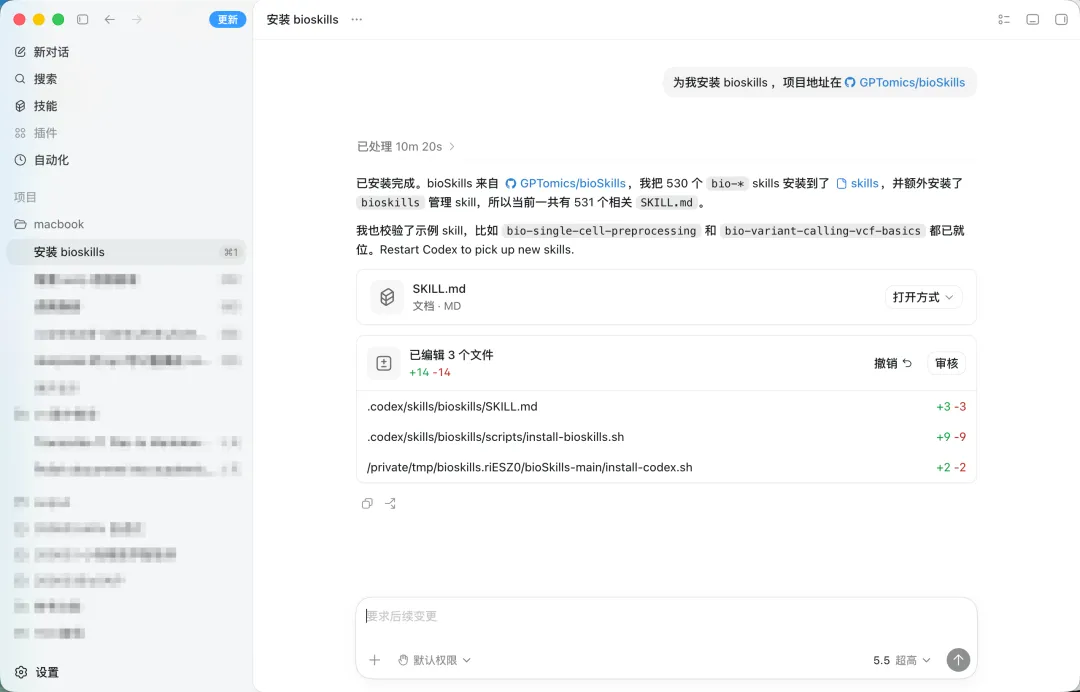
安装 R/Bioconductor 依赖
bioSkills 本身只是文本指令集,实际分析依赖本地的 R 环境。对本期内容而言,至少需要安装以下包:
温馨提示:让Codex直接帮你配置环境更简单哦!
if (!require("BiocManager", quietly = TRUE)) install.packages("BiocManager")BiocManager::install(c("DESeq2", # 差异表达分析核心"apeglm", # log2FC shrinkage"clusterProfiler", # 功能富集分析"org.Hs.eg.db", # 人类基因注释"airway", # 示例数据集(本期使用)"pheatmap"# 热图可视化))# Python 可视化辅助(可选)pip install pandas numpy matplotlib seaborn验证部署
启动 Codex 后,有两种方式确认 skills 已正确加载:
方式一:TUI 内交互
/skills将列出所有已发现的 skills 及其描述。
方式二:直接触发
$bio-de-deseq2-basics如果 Codex 正确响应并加载该 skill 的完整指令,则部署成功。
四、实战:GSE52778 airway 数据分析
接下来进入本期实战部分:使用公开数据集 GSE52778 展示Codex 分析 bulk RNA-seq 差异表达的结果。
1.数据集下载及概况
本次示例使用公开数据集 GSE52778,也是 DESeq2 教程中常用的数据。
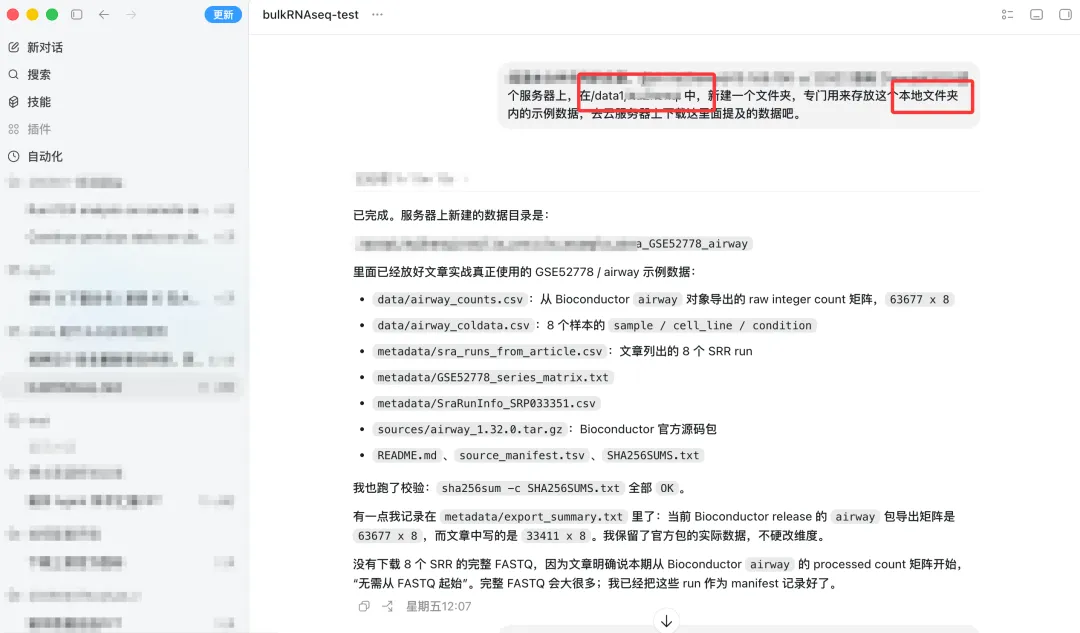
除了常用的去 GEO 等数据库上手动下载或者命令行下载外,现在还有更简单的方式,那就是使用 Codex 来通过对话下载:
阅读本文件夹内的文章(任何你想要复现的数据,或者直接写明数据集 ID),去XXX服务器上,在/data1/(文件目录地址)中,新建一个文件夹,专门用来存放这个本地文件夹内的示例数据,去云服务器上下载这里面提及的数据吧。
只需要告诉它以下几点:
你需要下载什么数据(数据集 ID 最好是存放在本地txt 文件内方便读取)
你想要下载到什么位置(本地或者云服务器)
剩下的就是等待几分钟,交给 Codex 去完成吧!
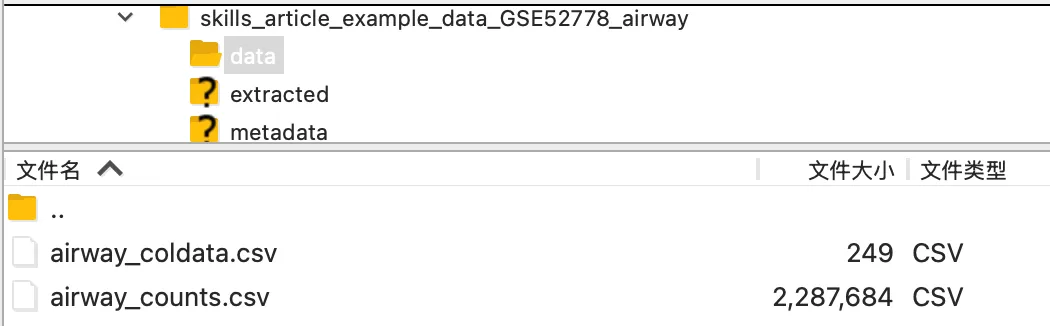
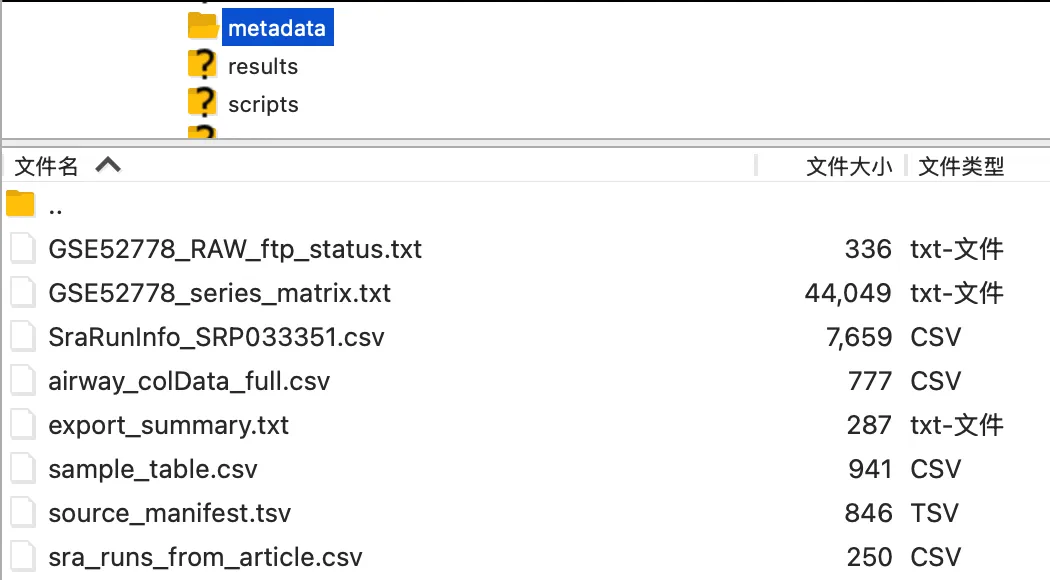
得到如上两个文件夹,每个文件夹的含义如下:
skills_article_example_data_GSE52778_airway/├── data/│ ├── airway_counts.csv│ │ └── 核心表达矩阵:每个基因在 8 个样本中的 raw count│ │ 是后续差异表达分析的主要输入│ ││ └── airway_coldata.csv│ └── 样本分组信息:记录每个样本的细胞系和处理条件│ 用来区分 treated 与 untreated,并识别细胞系批次│├── metadata/│ ├── GSE52778_series_matrix.txt│ │ └── GEO 数据集整体注释文件│ │ 包含 GSE52778 的实验描述、样本来源和平台信息│ ││ ├── SraRunInfo_SRP033351.csv│ │ └── SRA run 详细信息│ │ 包含 SRR 编号、实验编号、样本编号和测序相关信息│ ││ ├── airway_colData_full.csv│ │ └── airway 对象中的完整样本注释│ │ 比 airway_coldata.csv 信息更全│ ││ ├── sample_table.csv│ │ └── airway 包自带样本表│ │ 可用于核对样本编号、处理条件和数据来源│ ││ ├── sra_runs_from_article.csv│ │ └── 根据文章整理出的 8 个 SRR 样本│ │ 适合用于推送中展示样本信息│ ││ ├── export_summary.txt│ │ └── 本次数据导出摘要│ │ 包含 count 矩阵维度、样本数量等信息│ ││ ├── source_manifest.tsv│ │ └── 数据来源清单│ │ 记录哪些文件来自 Bioconductor、GEO 或 SRA│ ││ └── GSE52778_RAW_ftp_status.txt│ └── 原始 GEO supplementary 数据下载状态说明│ 本次分析未下载完整 raw 数据,因为使用的是 airway 包中的 count 矩阵│└── 可以得出的整体信息 ├── 本项目使用的是公开数据集 GSE52778 ├── 数据来自 Bioconductor airway 包 ├── 研究对象是人气道平滑肌细胞 ├── 实验比较为 dexamethasone treated vs untreated ├── 一共有 8 个 RNA-seq 样本 ├── 4 个细胞系,每个细胞系都有处理组和对照组 ├── data/ 中的两个 CSV 是真正用于差异表达分析的核心输入 └── metadata/ 中的文件用于解释数据来源、样本对应关系和可追溯性2.具体操作流程
具体使用方案很简单,直接在对话框中描述你的需求即可!
使用 bioskills和 R 语言对这个数据进行进行分析,最终得到差异基因火山图,GO 和 KEGG 通路富集可视化图。
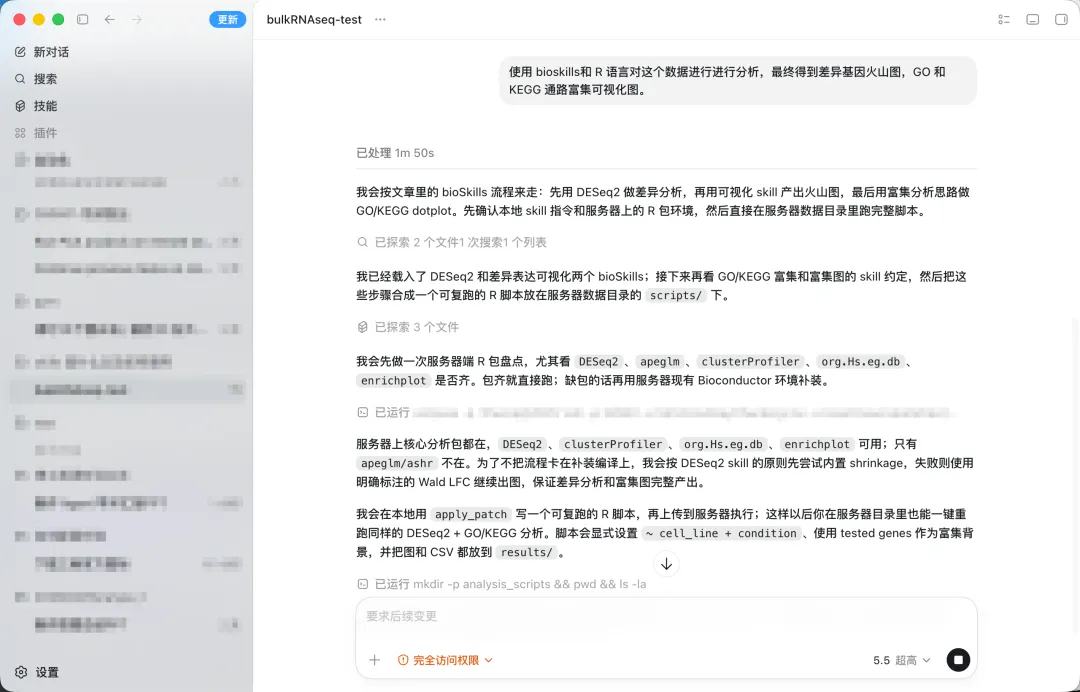
然后 AI就会开始思考,最后就能得到以下内容:
全程无人为干扰(除给权限之外)

五、结果展示
1.可复现的脚本
运行不到 10分钟,已经得到我们需要的结果!
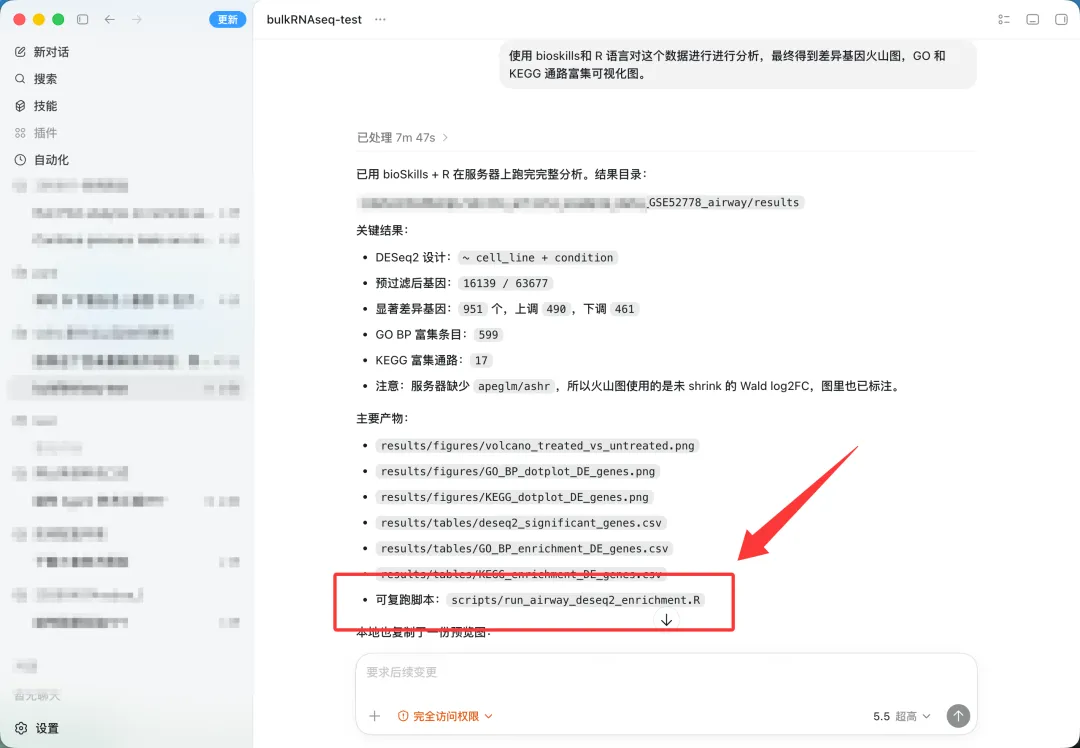
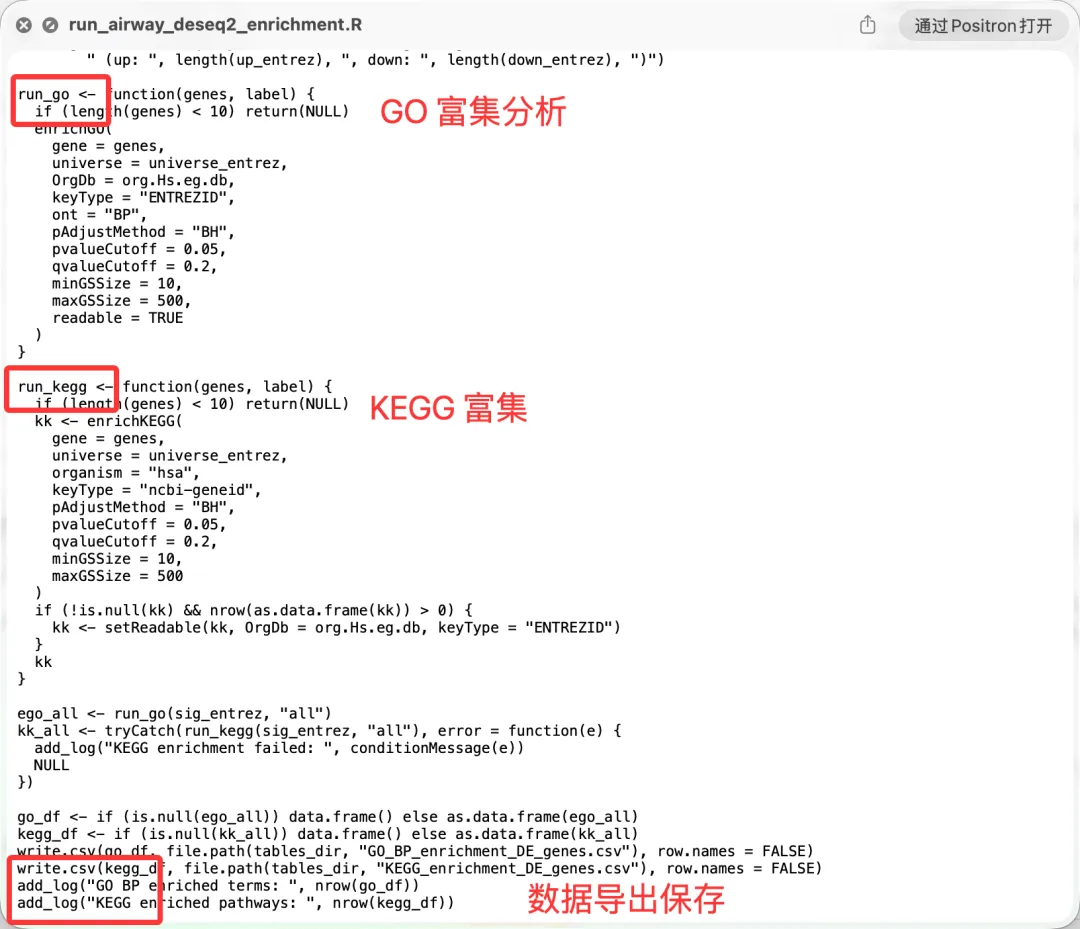
完美符合生信分析流程!
2.差异表达结果
本次比较的是 dexamethasone treated vs untreated。
以 padj < 0.05 且 |log2FC| > 1 作为筛选标准,共得到:
火山图如下。红色为处理后上调基因,蓝色为处理后下调基因。
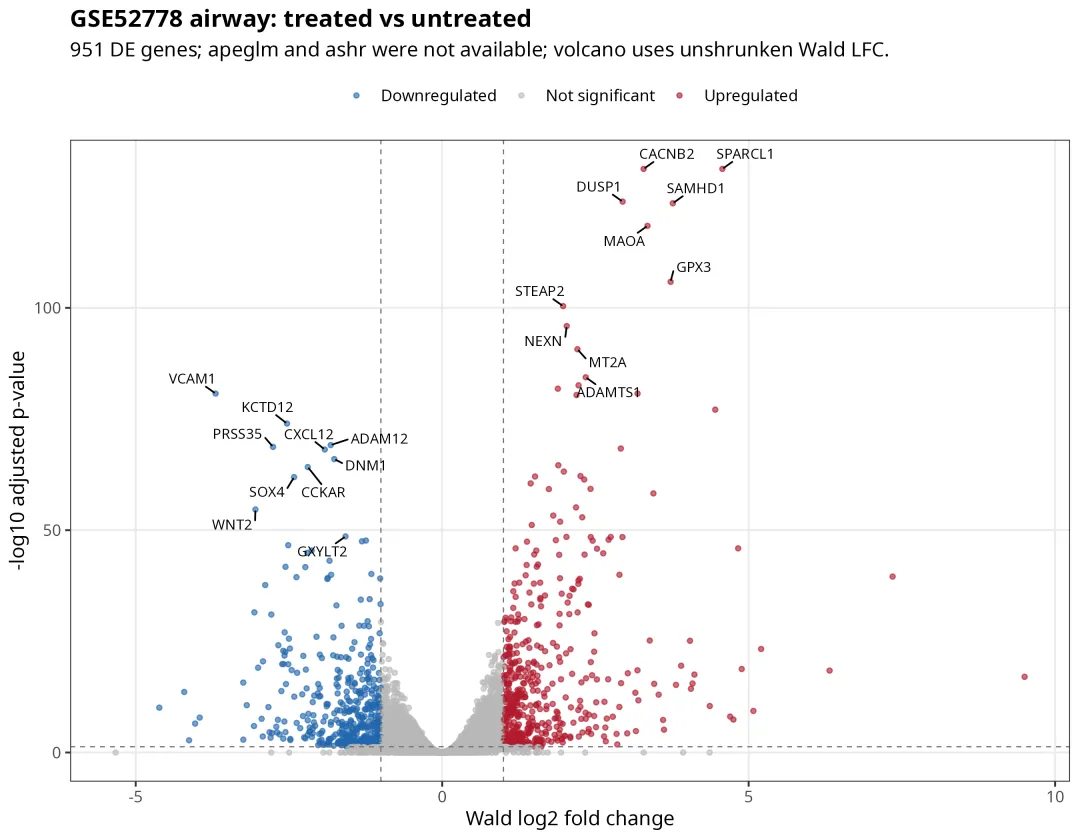
从图中可以看到,地塞米松处理后出现了一批非常显著的响应基因。上调端包含 DUSP1、MAOA、SPARCL1、SAMHD1、GPX3 等;下调端可以看到 VCAM1、CXCL12、WNT2 等基因。
其中 DUSP1 是糖皮质激素反应中非常经典的响应基因之一,这与该数据集的生物学背景相符。
3.GO Biological Process 富集结果
对差异基因进行 GO Biological Process 富集后,共得到 599 个显著富集条目。
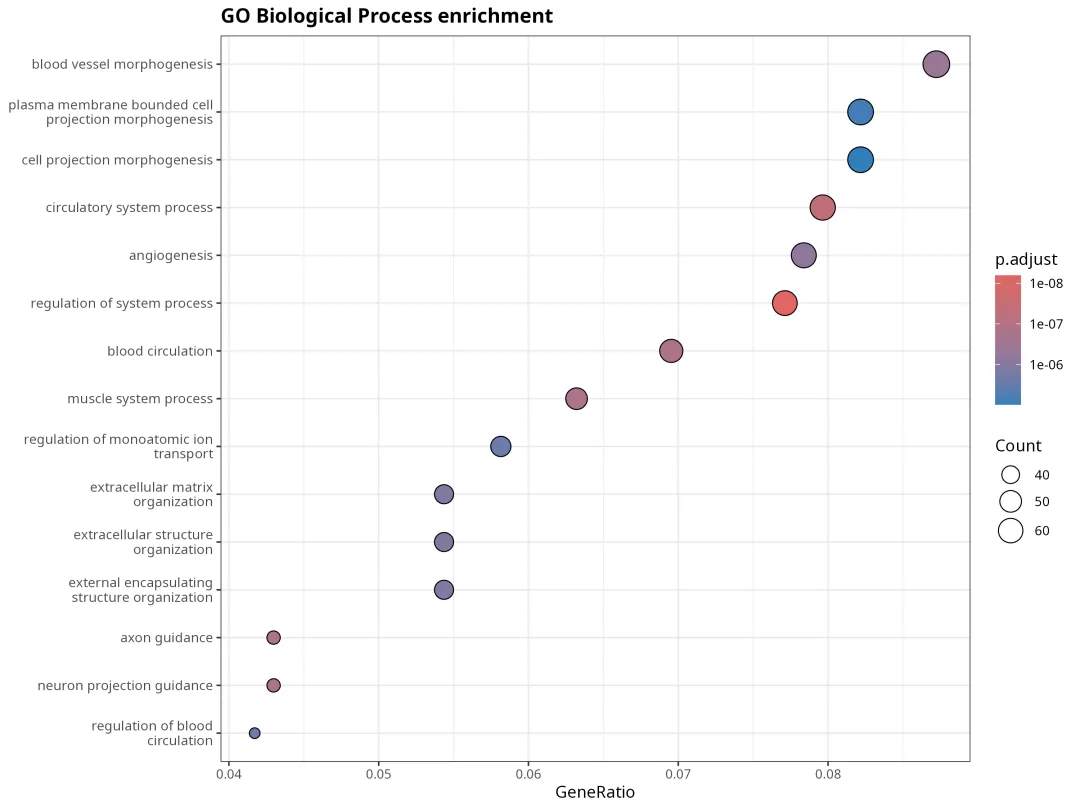
这些结果与 airway smooth muscle 细胞的组织来源有较好的对应关系。尤其是血管生成、细胞外基质组织、肌肉系统过程等条目,提示地塞米松处理不仅改变了炎症相关基因,也牵动了细胞结构、迁移和组织重塑相关程序。
4.KEGG 通路富集结果
KEGG 富集共得到 17 条显著通路。
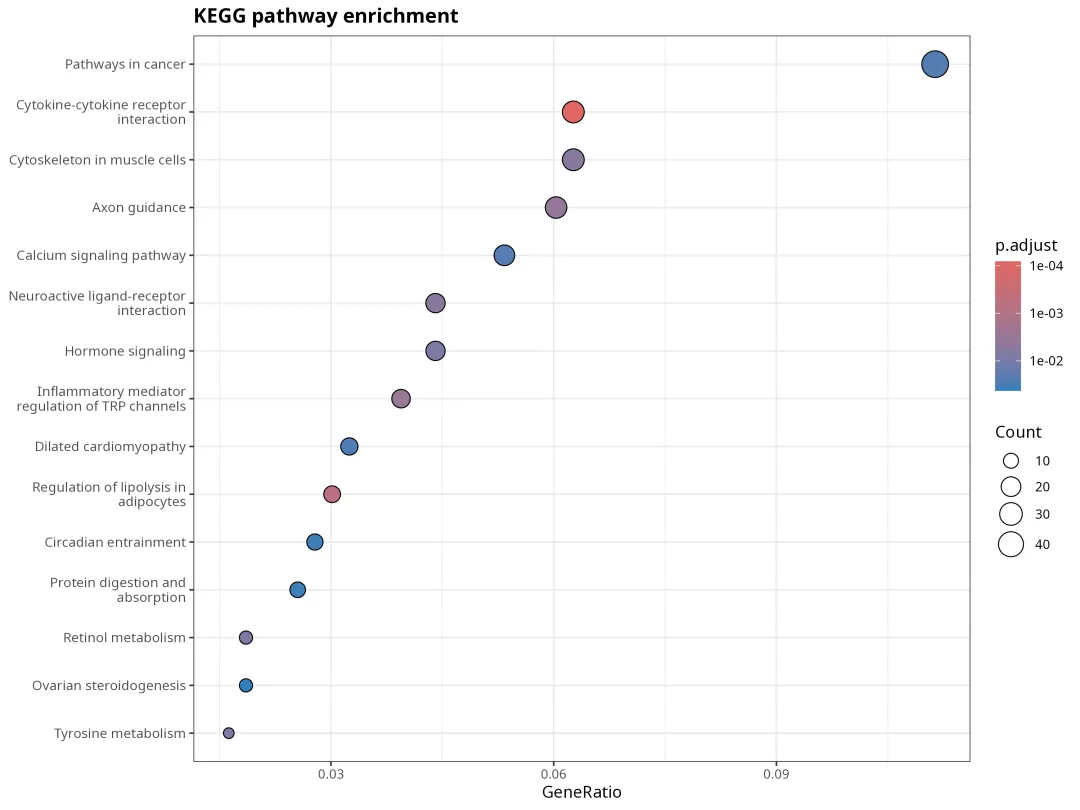
其中 Cytokine-cytokine receptor interaction 和 Inflammatory mediator regulation of TRP channels 与炎症调控背景相吻合;而 cytoskeleton、calcium signaling、hormone signaling 等通路,则提示处理后细胞状态和信号转导层面也发生了系统性变化。
六、总结
对于 bulk RNA-seq 这样的标准流程,bioSkills 可以把许多容易出错的经验固化下来,使 Agent 更像一个能协作执行的分析助手:理解任务、组织流程、产出结果,并把图表和表格整理成方便复盘的形式保存。
生信 Agent 不是替代研究者的判断,而是把稳定、繁琐、容易遗漏的分析执行部分交给 Agent,让研究者把更多精力放回到问题设计和生物学解释上。
本文示例分析基于公开数据集 GSE52778 和 GPTomics/bioSkills 开源项目(MIT License)。
