 夜雨聆风
夜雨聆风PDF 一直是知识库、论文、合同、报告和企业资料里最常见的文件格式,但它对 AI 应用并不算友好。你把 PDF 直接丢给普通解析器,经常会遇到阅读顺序错乱、表格拆散、多栏论文串行、图片和公式丢失、段落坐标缺失等问题。对于 RAG、企业文档检索、合规归档或者无障碍改造来说,这些细节不是锦上添花,而是直接决定后续数据能不能用。
OpenDataLoader PDF 就是针对这类问题做的开源项目。它主打把 PDF 转成 AI 更容易消费的结构化数据,支持 Markdown、JSON、HTML、文本、带标注 PDF,以及面向屏幕阅读器的 Tagged PDF 输出。项目当前在 GitHub 上已有约 23.8k Star、2.2k Fork,热度很高,定位也很明确:不是只把 PDF 里的文字扒出来,而是尽量保留标题、段落、列表、表格、图片、坐标、阅读顺序等结构信息。

一、相关链接
GitHub 地址:https://github.com/opendataloader-project/opendataloader-pdf Python 包地址:https://pypi.org/project/opendataloader-pdf/ 官方文档地址:https://opendataloader.org/ Node.js 快速开始:https://opendataloader.org/ Java 快速开始:https://opendataloader.org/
二、OpenDataLoader PDF 是什么
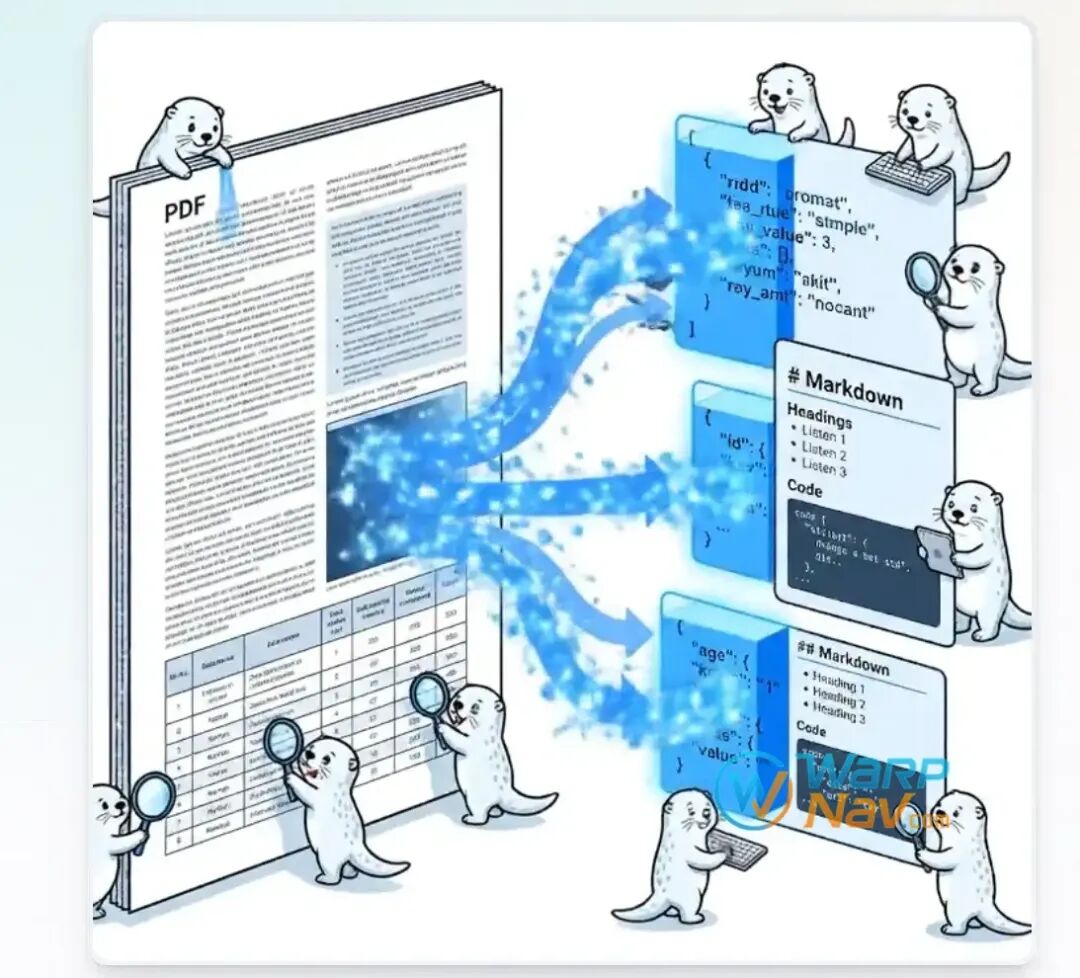
OpenDataLoader PDF 是 opendataloader-project 开源的一套 PDF 解析与无障碍自动化工具。它的核心目标可以分成两块:一块是为 AI 数据提取提供更干净、更结构化的 PDF 内容;另一块是自动把未打标签的 PDF 转成 Tagged PDF,帮助文档进入更可访问的无障碍处理流程。
从 README 的介绍看,它并不只面向单一语言生态。项目提供 Python、Node.js 和 Java 的使用方式,Python 包名是 opendataloader-pdf,Node.js 包名是 @opendataloader/pdf,Java 侧则提供 Maven 依赖。对于开发者来说,这意味着你可以把它接进 Python 数据处理脚本,也可以放进 Node.js 服务,或者在 Java 后端里做批量 PDF 转换。
它的输出也比较贴近 AI 应用场景。普通 PDF 解析工具通常更关心“提取文字”,而 OpenDataLoader PDF 更强调“提取结构”。例如 JSON 结果中会包含元素类型、页码、边界框、标题级别和内容字段;Markdown 适合直接进入 RAG 切块流程;HTML 可以用于页面展示;Annotated PDF 则适合调试解析结果,查看模型或规则识别出的标题、段落、表格、图片区域是否准确。
三、 核心功能
- PDF 转 Markdown / JSON / HTML / Text
可以把 PDF 转换成多种常见格式,其中 Markdown 适合知识库和 LLM 上下文,JSON 适合需要坐标、页码和元素类型的结构化处理。 - 元素级坐标输出
JSON 会给出 heading、paragraph、table、list、image、caption、formula 等元素信息,并附带 bounding box,方便做来源引用、页面高亮和可视化校对。 - 阅读顺序修复
项目强调对多栏文档、论文和复杂页面的阅读顺序处理,减少直接抽取后段落串行错误的问题。 - 表格识别
支持简单有边框表格,也支持复杂或无边框表格;复杂场景可通过 Hybrid 模式处理。 - OCR 支持
对于扫描版、图片型 PDF,可以在混合模式下启用 OCR,并支持多语言识别,适合处理无法直接选中文字的旧文档。 - 公式提取
面向论文、教材和技术文档,可以在 Hybrid 模式下把数学公式提取为 LaTeX 形式。 - 图片和图表描述
通过视觉模型生成图片或图表描述,可用于 RAG 检索、无障碍 alt text 或文档理解。 - Tagged PDF 支持
如果原 PDF 已有结构标签,工具可以优先读取作者定义的结构;如果是未打标签 PDF,也可以生成 Tagged PDF。 - AI 安全处理
针对 PDF 中可能存在的隐藏文本、透明文本、页面外内容和可疑不可见层,项目提供过滤能力,并支持显式启用脱敏处理。 - LangChain 集成
提供 langchain-opendataloader-pdf,可以把 PDF 解析结果接入 LangChain 文档加载流程。
四、 能解决哪些问题
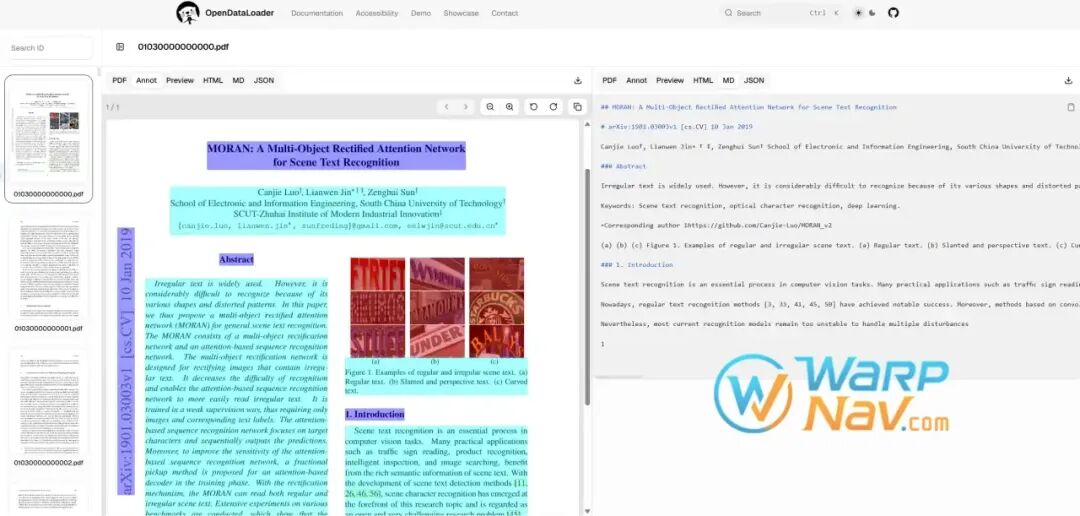
如果你处理的是论文或技术资料,公式、图表和标题层级也很关键。README 中提到,Hybrid 模式可以处理复杂表格、扫描 PDF、公式和图表描述。对于科研资料归档、企业技术文档搜索、学习资料整理,这类能力比简单文本提取更有价值。
另一个比较特别的方向是 PDF 无障碍。很多历史 PDF 没有结构标签,屏幕阅读器难以正确理解标题、段落、列表和表格。OpenDataLoader PDF 提供从未打标签 PDF 到 Tagged PDF 的自动化流程,免费部分基于 Apache 2.0 协议,PDF/UA-1、PDF/UA-2 导出和可视化编辑则属于企业增强能力。对需要做文档合规、公共服务资料无障碍改造的团队来说,这个方向很实用。
五、快速部署
OpenDataLoader PDF 的基础使用门槛不高,但需要注意环境依赖。官方要求 Java 11+ 和 Python 3.10+。如果你准备使用 Python,先确认本机可以执行:
java -version然后安装 Python 包:
pip install -U opendataloader-pdf最简单的 Python 调用方式如下:
import opendataloader_pdfopendataloader_pdf.convert(input_path=["file1.pdf", "file2.pdf", "folder/"],output_dir="output/",format="markdown,json")
如果你更习惯命令行,也可以直接处理单个文件、多个文件或整个文件夹:
opendataloader-pdf file1.pdf file2.pdf folder/Node.js 项目可以安装:
npm install @opendataloader/pdf然后在代码中调用:
import { convert } from '@opendataloader/pdf';await convert(['file1.pdf', 'file2.pdf', 'folder/'], {outputDir: 'output/',format: 'markdown,json'});
如果要处理扫描件、复杂表格、公式或图表描述,可以安装 Hybrid 版本:
pip install -U "opendataloader-pdf[hybrid]"启动后端服务:
opendataloader-pdf-hybrid --port 5002再使用混合模式处理文档:
opendataloader-pdf --hybrid docling-fast file1.pdf file2.pdf folder/扫描版 PDF 可以额外启用 OCR:
opendataloader-pdf-hybrid --port 5002 --force-ocr如果是中文、英文或其他多语言扫描文档,可以指定 OCR 语言,例如:
opendataloader-pdf-hybrid --port 5002 --force-ocr --ocr-lang "ch_sim,en"六、 输出格式及使用建议
OpenDataLoader PDF 的几个输出格式适合不同场景:
输出格式 适合场景 Markdown RAG 切块、LLM 上下文、知识库导入 JSON 结构化解析、坐标引用、页面高亮、数据管线 HTML Web 展示、预览页面、格式还原 Annotated PDF 调试解析效果,查看识别出的元素区域 Text 简单纯文本提取 Tagged PDF 无障碍处理、屏幕阅读器友好文档 如果你只是想把普通数字 PDF 放进知识库,可以先用默认模式输出 Markdown 和 JSON。Markdown 负责给 LLM 提供可读内容,JSON 负责保留页码和坐标信息。对于多栏论文、复杂表格或扫描件,再考虑 Hybrid 模式和 OCR。这样做的好处是成本更可控,不必一上来就把所有页面都交给更重的模型处理。
七、适用人群
正在搭建 RAG 知识库,需要把 PDF 转成高质量 Markdown 或结构化 JSON 的开发者。 需要处理论文、报告、合同、手册、财报等复杂 PDF 的数据工程师。 希望在答案中保留页码、坐标和来源引用的 AI 应用开发团队。 需要批量处理扫描 PDF、图片型 PDF、多语言 OCR 的资料整理人员。 关注 PDF 无障碍、Tagged PDF 和文档合规的企业或公共服务团队。 想在 Python、Node.js 或 Java 项目中集成 PDF 解析能力的后端开发者。
八、 测试体验
小编测试了 OpenDataLoader PDF 的基础安装和调用流程,整体感觉它更像一个偏工程化的 PDF 数据处理组件,而不是单纯的“PDF 转 Markdown 小工具”。安装步骤比较直接,真正需要提前准备的是 Java 环境;如果本机没有 JDK,第一次运行前会卡在环境配置这一步。
基础数字 PDF 的使用方式很清晰,Python 里几行代码就能把文件夹批量转成 Markdown 和 JSON。它输出 JSON 时保留元素类型、页码和坐标,这一点对做 RAG 引用很有帮助,因为你后续可以把答案定位回 PDF 页面,而不是只有一段孤立文本。
比较值得注意的是,项目文档反复提醒批量转换要放在一次调用里完成。这个提示很实在,因为背后会启动 JVM,如果你写循环一个文件调用一次,速度体验会明显变差。实际接入时,建议把它当成批处理任务或后端解析服务来设计。
Hybrid 模式的能力看起来更强,但部署复杂度也会上来,需要额外启动服务。普通资料整理可以先从默认模式开始,遇到扫描件、复杂表格、公式或图表时再切换过去。总体看,OpenDataLoader PDF 适合有真实 PDF 处理需求的开发者,尤其是想把 PDF 稳定接入 AI 工作流的人。
更多优质内容,尽在曲速导航:warpnav.com 开启网上冲浪 AI 新时代,你的首选资源网络导航站!
