 夜雨聆风
夜雨聆风“ 这里是「教育现场的 AI 观察」。不追热点词,也不把技术说得太玄,只聊老师、学生、学校每天真的会遇到的事。今天这篇,想从一个让高校师生都有点紧张的检测工具说起。”
2025 年 5 月,中国人民大学副教授董晨宇遇到了一件荒诞的事。
他耗时三年做田野调查写成的一篇论文,被 AI 检测系统判定为"AI 生成率 82.54%"。一个人类学者,用三年时间跑田野、做访谈、整理笔记——写出来的东西,被机器认定是 AI 写的。
这不是孤例。《滕王阁序》被网友输入某 AI 检测系统,公元 675 年的千古名篇,被判"AI 率超过 50%"。
我开始好奇:**这些 AI 检测工具,到底靠不靠谱?**
01
—
我做了个测试:5 篇论文,3 个工具,结果互相打架
准备了 5 段文本,每段 300 字左右,学术论文风格。
**样本 A**:2018 年发表的一篇教育学论文摘要。ChatGPT 还没出生的年份——确定是纯人写的。
**样本 B**:让 ChatGPT 直接生成的一段教育技术论文段落。100% AI 输出,一字未改。
**样本 C**:AI 生成初稿后,我自己动手改了三四遍——段落重排、加了三个具体案例、删掉了两段 AI 套话。AI 辅助起步,人做了实质编辑。
**样本 D**:我自己先写的初稿,然后用 ChatGPT 润色语言。人写 AI 改。
**样本 E**:前半段我自己写的,后半段 AI 写的,拼在一起没做额外编辑。人机混合。
把这 5 段文本分别丢进三个 AI 检测工具:GPTZero、ZeroGPT,以及国内某高校常用的检测系统——这里叫它"工具 X"。
结果出来的时候,我反复确认了三遍。
02
—
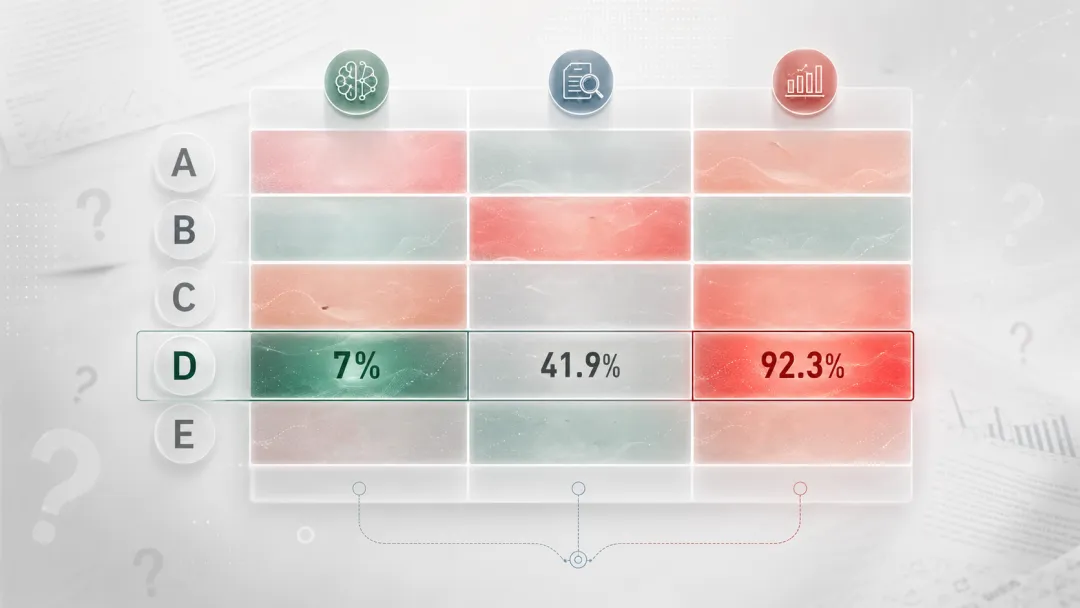
同一个样本,GPTZero 判 7%,ZeroGPT 判 92%
以样本 D——人写初稿后让 AI 润色——为例:
-**GPTZero**:"很可能由人类撰写",AI 概率仅 **7%**。
-**ZeroGPT**:"AI 生成概率 **92.3%**",建议"进行大幅度人工重写"。
-**工具 X**:AI 率 **41.9%**,恰好卡在灰色地带。
同一段文字。七成人类血统还是九成 AI 血统?取决于你用的是哪个法官。
最让人不安的是样本 C。这段文字我的修改痕迹占了至少一半——工具 X 判了它"AI 率 88.9%",依据是"句式结构高度规则化"。但问题出在:学术写作本身的规范要求,就是结构清晰、表达准确。把"写得规范"当成"写得像 AI"——这等于在惩罚遵守学术写作规范的学生。
样本 A,那篇纯人写的 2018 年论文——ChatGPT 诞生之前的东西——ZeroGPT 判了它 17% 的 AI 概率。不算高,但足够让一个紧张的研究生去查一整晚"怎么降 AI 率"了。
**但问题就出在中间地带。** 大部分学生提交的论文不是 100% 人写,也不是 100% AI 生成——而是 AI 辅助、编辑、混合的文本。恰好是检测工具分歧最大、最不可靠的区域。

03
—
检测工具不是审判庭
测完这一轮,我有两个判断。
**第一,检测工具在极端两端比较准,在中间地带不太靠谱。** "全 AI"和"全人类"两个极端的判定相对一致,但人机混合、AI 辅助润色、人改 AI 稿——这些中间状态,不同工具的结论天差地别。而高校学生提交的论文,大部分就在这个中间地带。
**第二,就算工具判了高 AI 率,不等于论文没有学术价值。** 董晨宇那篇被判 82.54% 的论文,最终顺利通过答辩——因为导师和答辩委员会看了内容,确认这是一个学者三年田野调查的扎实成果。南京大学 2025 年也明确:AIGC 检测结果"仅作为学术规范性辅助参考,不作为论文原创性判定依据"。
2025 年发表在《Advances in Physiology Education》上的一项研究给出了一组关键数据:单个 AI 检测工具的误判率约 1.3%,如果同时用多个工具、取交叉一致的结果,误判率可以降到接近 0%。这意味着不是检测这件事本身没用,而是**单靠一个工具就下定论,本身就是不靠谱的用法**。

04
—
下期预告
这篇文章确认了一件事:AI 检测工具顶多是个"警示灯",不是审判庭。
那问题就变成了——**如果论文被误判了,或者你想主动降低被误判的风险,具体该怎么做?**
下期我会把这套方法拆成四个步骤:用 AI 前的预防策略、AI 辅助写作中的写法、写完后的编辑技巧、以及万一被误判了该怎么申诉。不聊"多加点个人经验"这种空话——每一步都有具体可操作的方法。
不想错过的老师,可以点个关注。
你或者你的学生被 AI 检测误判过吗?在评论区说说你的经历,或者把这篇文章转给正在为期末论文头疼的同事。
