 夜雨聆风
夜雨聆风Agent Skills Hub 上浏览器自动化类目的总 Star 数高达42.6 万。30 个工具,比 Web 开发多 3 倍,比 GitHub MCP 多 8 倍,没有一个赛道比它更拥挤。
为什么?浏览器是 AI Agent 和真实世界之间最宽的那扇门,能操作浏览器,就能操作互联网上几乎一切信息。这个逻辑太直白了,直白到所有人都冲了进来。
问题是:30 个工具,5 种路线,你选哪条?
五大派系
把 30 个工具摊开看,格局很清晰。
派系一:Agent 浏览器框架
这是最核心的赛道。给 AI Agent 一双手,让它像人一样操作网页。
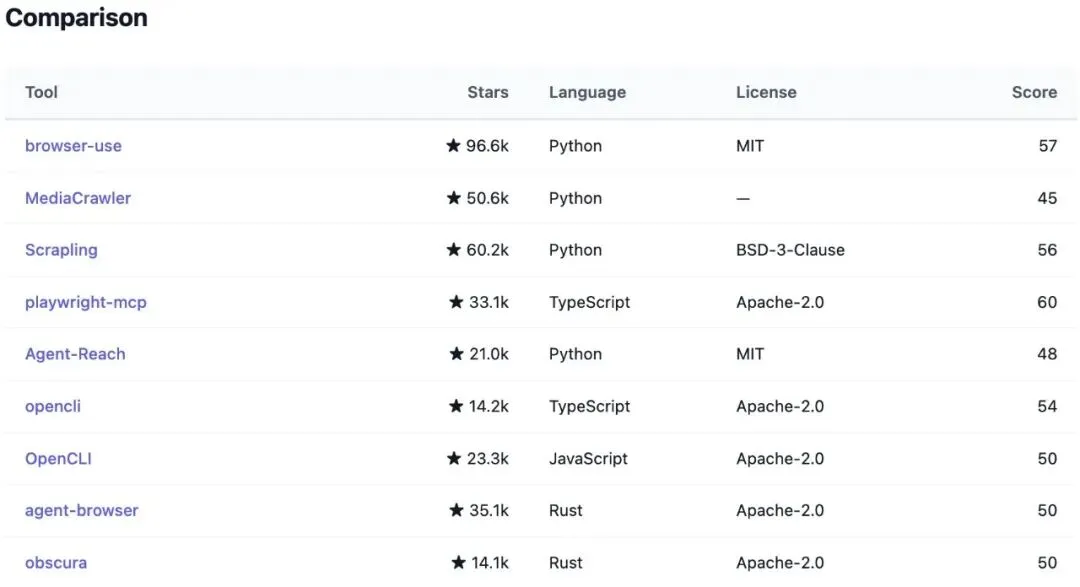
browser-use(96.6k Star,评分 57,Python)
断层第一。几乎成了"AI 浏览器自动化"的代名词。它的核心思路:把网页变成 Agent 可访问的结构化信息,然后让 LLM 决定下一步操作。简单,直接,有效。
agent-browser(35.1k Star,Rust,Vercel 出品)
Vercel Labs 做的。Rust 写的浏览器自动化 CLI。定位精准:给 AI Agent 用的浏览器命令行工具。Vercel 的品牌背书加上 Rust 的性能优势,让它在速度敏感场景有竞争力。
stagehand(22.9k Star,TypeScript,Browserbase 出品)
定位是"Browser Agent 的 SDK"。和 browser-use 的区别:stagehand 更偏开发者体验,提供更结构化的 API。Browserbase 同时还做了 mcp-server-browserbase(3.3k Star)和 skills(2.8k Star),三条产品线覆盖 MCP、Agent SDK 和 Claude Skill 三个接入层。
nanobrowser(12.4k Star,TypeScript)
Chrome 扩展形态。不需要本地部署,装个插件就能跑多 Agent 工作流。定位是 OpenAI Operator 的开源替代。
这四个工具代表了 Agent 浏览器框架的四种思路:Python 通用框架(browser-use)、Rust 高性能 CLI(agent-browser)、TypeScript SDK(stagehand)、浏览器扩展(nanobrowser)。
派系二:中文平台爬虫
这个派系的存在本身就是一个信号:中文互联网的数据需求足够大,撑起了一个独立赛道。
MediaCrawler(50.6k Star,Python)
小红书、抖音、快手、B 站、微博、百度贴吧、知乎。七个平台,笔记、视频、评论、帖子全覆盖。5 万 Star 说明需求有多真实。
Agent-Reach(20.9k Star,Python)
定位更广:让 AI Agent 看见整个互联网。支持 Twitter、Reddit、YouTube、GitHub、B 站、小红书。零 API 费用,一条命令搞定。
feedgrab(471 Star,Python)
通用内容抓取器。微信、小红书、X/Twitter、YouTube、B 站、Telegram、RSS,7 个平台。Star 数不多,覆盖的平台很实用。
AutoCLI(2.7k Star,Rust)
55+ 个站点,覆盖 B 站、知乎、Twitter、YouTube、微博、Reddit、Facebook、Instagram、TikTok、Notion、Cursor。还能控制 Electron 桌面应用,集成 gh、docker、kubectl 等本地 CLI。功能密度极高。
中文平台爬虫的共性:绕过平台 API 限制,直接操作浏览器获取数据。这条路有法律灰度,也有技术壁垒。5 万 Star 的 MediaCrawler 证明,需求不会因为灰度而消失。
派系三:自适应爬虫框架
Scrapling(58.0k Star,Python,评分 56)
自适应爬虫框架。从单次请求到大规模爬取,一套框架搞定。它的核心能力:自动适应网页结构变化。传统爬虫一改版就挂,Scrapling 能自己调整选择器。
firecrawl-mcp-server(6.5k Star,JavaScript,评分 56)
Firecrawl 官方 MCP 服务器。把网页爬取和搜索能力接入 Cursor、Claude 等 LLM 客户端。评分和 Scrapling 并列 56,说明 MCP 化的爬虫工具质量已经追上原生框架。
这两个工具解决的是同一个问题:让爬虫不那么脆。网页结构变了,反爬策略升级了,工具得自己扛住。
派系四:MCP 浏览器服务器
这个派系最值得关注的不是哪个工具最强,而是谁在背后。
playwright-mcp(33.1k Star,TypeScript,评分 60,Microsoft 出品)
全场最高评分。微软把 Playwright 封装成 MCP 服务器,让任何支持 MCP 的 LLM 都能直接操控浏览器。Playwright 本身就是浏览器自动化的工业标准,MCP 化之后,Agent 生态直接继承了它的全部能力。
mcp-chrome(10.7k Star,TypeScript)
Chrome 扩展形式的 MCP 服务器。你的 Chrome 浏览器直接变成 AI 可操控的工具。支持复杂自动化、内容分析、语义搜索。不需要额外部署浏览器,用你已经在用的那个。
browser-tools-mcp(7.1k Star,JavaScript)
从 Cursor 和其他 MCP 兼容 IDE 直接监控浏览器日志。开发调试场景很实用。
browser-use-mcp-server(811 Star,Python)
把 browser-use 封装成 MCP 服务器。从 Cursor 等工具直接浏览网页。
MCP 浏览器服务器的意义:它把浏览器自动化从"独立工具"变成了"Agent 生态的一个组件"。你不需要单独跑一个爬虫脚本,MCP 协议让浏览器能力像调用函数一样简单。
派系五:网站转 CLI
OpenCLI(23.3k Star,JavaScript)+ opencli(14.2k Star,TypeScript)
同一个作者的两个项目。核心思路:把任何网站变成 CLI 命令。AI Agent 用命令行操作网页,不需要 GUI。还支持复用你 Chrome 的登录态,不需要 API Key。
这个派系的野心很大:不只是自动化浏览器,而是重新定义 Agent 和 Web 的交互方式。命令行比浏览器更高效,也更符合 Agent 的工作模式。
评分和 Star 的错位
playwright-mcp 的 Star 只有 browser-use 的三分之一,评分却高出 3 分。firecrawl-mcp-server 的 Star 只有 6.5k,评分和 58k Star 的 Scrapling 持平。
评分体系衡量的是代码质量、文档完整度和维护活跃度。Star 衡量的是传播广度和话题热度。两者交叉看,才能识别出被低估的工具。
firecrawl-mcp-server 就是一个典型:6.5k Star,评分 56。如果你只看 Star 榜,会错过它。
Rust 的渗透
30 个工具里,3 个用 Rust 写的:agent-browser(35.1k)、obscura(14.1k)、AutoCLI(2.7k)。
Rust 在浏览器自动化场景有两个天然优势:反检测能力更强(编译型语言,运行时特征少),并发性能更好(大规模爬取场景)。obscura 直接把自己定位为"AI Agent 的无头浏览器",Anti-detection 是核心卖点。
camofox-browser(228 Star)更极端:专门做反检测浏览器服务器,用 Camoufox 引擎包装 REST API。虽然 Star 不多,方向值得关注。
Python 占了大多数(browser-use、MediaCrawler、Scrapling、Agent-Reach),但 Rust 正在从性能和反检测两个切面渗透。这个趋势在 2027 年会更明显。
选型决策树
根据你的场景,走不同的路。
场景一:让 AI Agent 自动操作网页完成任务
首选 browser-use。生态最成熟,社区最大,Python 上手快。如果你用 TypeScript,选 stagehand。如果你追求极致性能,选 agent-browser(Rust)。
场景二:抓取中文社交平台数据
MediaCrawler 是唯一的选择。七个平台全覆盖,5 万 Star 的社区验证。需要更广的覆盖面,加 Agent-Reach 或 AutoCLI。
场景三:在 MCP 生态里操控浏览器
playwright-mcp。微软出品,评分最高,Playwright 的工业级能力直接继承。需要用你自己的 Chrome 浏览器,选 mcp-chrome。
场景四:大规模爬取,网页结构经常变
Scrapling。自适应选择器是杀手锏。需要 MCP 接入,选 firecrawl-mcp-server。
场景五:让 Agent 用命令行操作网站
OpenCLI。复用 Chrome 登录态,不需要 API Key,55+ 站点覆盖。
被忽视的风险
浏览器自动化工具的法律灰度,尤其是中文平台爬虫这一块,需要单独说。
MediaCrawler 50.6k Star,没有标注 License。这意味着使用条款不明确,商业用途有风险。sp500-mcp-server 用的是 AGPL-3.0,对商业部署有限制。
反检测工具(obscura、camofox-browser)的技术本身不违法,用途可能踩线。爬取公开数据和绕过平台反爬机制之间的边界,在不同司法辖区定义不同。
选工具之前,先想清楚你的使用场景在法律上站不站得住。技术能力跑在合规前面,是这个赛道最常见的坑。
总结一个
42 万 Star 背后的信号很清楚:浏览器自动化是 AI Agent 落地的第一站。Agent 要做事,先得能看见和操作互联网。浏览器是唯一的通用入口。
五派并存说明这件事还没有最优解。browser-use 的通用框架、playwright-mcp 的工业标准、Scrapling 的自适应、OpenCLI 的命令行范式、MediaCrawler 的中文平台覆盖,各自解决不同切面的问题。
对开发者来说,现在入场不算晚。30 个工具之间还有大量缝隙:中文平台爬虫缺少 MCP 化的方案,自适应爬虫和 Agent 框架的集成还不够丝滑,反检测能力还没有成为标配。每一个缝隙都是一个可以深扎的方向。
相关链接:
• Agent Skills Hub 完整榜单:https://agentskillshub.top/best/browser-automation/ • browser-use:https://github.com/browser-use/browser-use • playwright-mcp:https://github.com/microsoft/playwright-mcp • Scrapling:https://github.com/D4Vinci/Scrapling • MediaCrawler:https://github.com/NanmiCoder/MediaCrawler • agent-browser:https://github.com/vercel-labs/agent-browser • OpenCLI:https://github.com/jackwener/OpenCLI
