 夜雨聆风
夜雨聆风【导读】你的 AI Agent 再聪明,换个应用就什么都不记得。Walrus 在 6 月 4 日正式发布 Walrus Memory,定位 AI agent 的「可携带记忆层」——agent 在不同 app 之间迁移时可以带走自己的上下文、权限和决策痕迹。发布帖超过 20 万次查看。这件事的核心指向一个越来越尖锐的问题:agent 的长期记忆,到底该归平台还是归用户?
Agent 越强,失忆越痛
2026 年的 AI Agent 已经能帮你写代码、跑数据、管日程、协调多个工具链。
但有一件事,几乎所有 agent 都做得很差:记住上一次发生了什么。
换一个 app,忘了。换一个 session,忘了。换一个 provider,彻底忘了。
这跟模型能力无关。Claude、GPT、Gemini 的上下文窗口越来越大,但上下文窗口再大,也只管得了当前这一轮对话。你关掉窗口,一切归零。
更要命的在后面:就算有些平台提供了「记忆」功能,这些记忆也被锁在平台内部。你在 A 平台积累的 agent 记忆,带不到 B 平台去。你甚至不知道平台到底记住了什么、谁能访问、有没有被篡改。
Walrus 团队在官方博客里把这个问题摆上了台面:
"Most agent memory lives locked inside platforms."
「大多数 agent 记忆都被锁在平台内部。」
Walrus Memory:让 Agent 带着记忆搬家
6 月 4 日,Walrus 通过官方 X 账号正式发布了 Walrus Memory。
▲ Walrus 官方 X 帖:「让你的 AI agent 在每个应用里都能携带上下文」,超 20 万次查看
官方给出的产品定义:
"A portable memory layer that lets your AI agents carry context across every app you run them in."
翻成中文:一层可携带的记忆层,让你的 AI agent 在你运行它的每个应用里都能带着上下文。
后面两个口号直指核心痛点:
"No more starting from zero. No more being locked into one platform."
「不用再每次从零开始。不用再被锁死在一个平台里。」
Walrus Memory 的核心目标:让 agent 的记忆变成用户自己的资产,可以跨工具、跨平台、跨 session 地携带和复用。
底层怎么做的?SDK + 链上权限 + 加密存储
Walrus Memory 的技术结构在今年 3 月的 beta 背景文和官方文档里已经公开。
核心架构是一套developer SDK + backend relayer的组合:
- 存储层
:agent 的记忆内容(对话、推理痕迹、工作流快照、长期知识)通过 Seal 做端到端加密,然后存入 Walrus 数据层。 - 权限层
:所有权和访问控制交给 Sui 智能合约管理。谁能读、谁能写、谁能把访问权限委托给第三方,都通过合约执行。 - 检索层
:relayer 和 indexer 负责 embedding、检索与恢复,让 agent 能快速调用历史记忆。
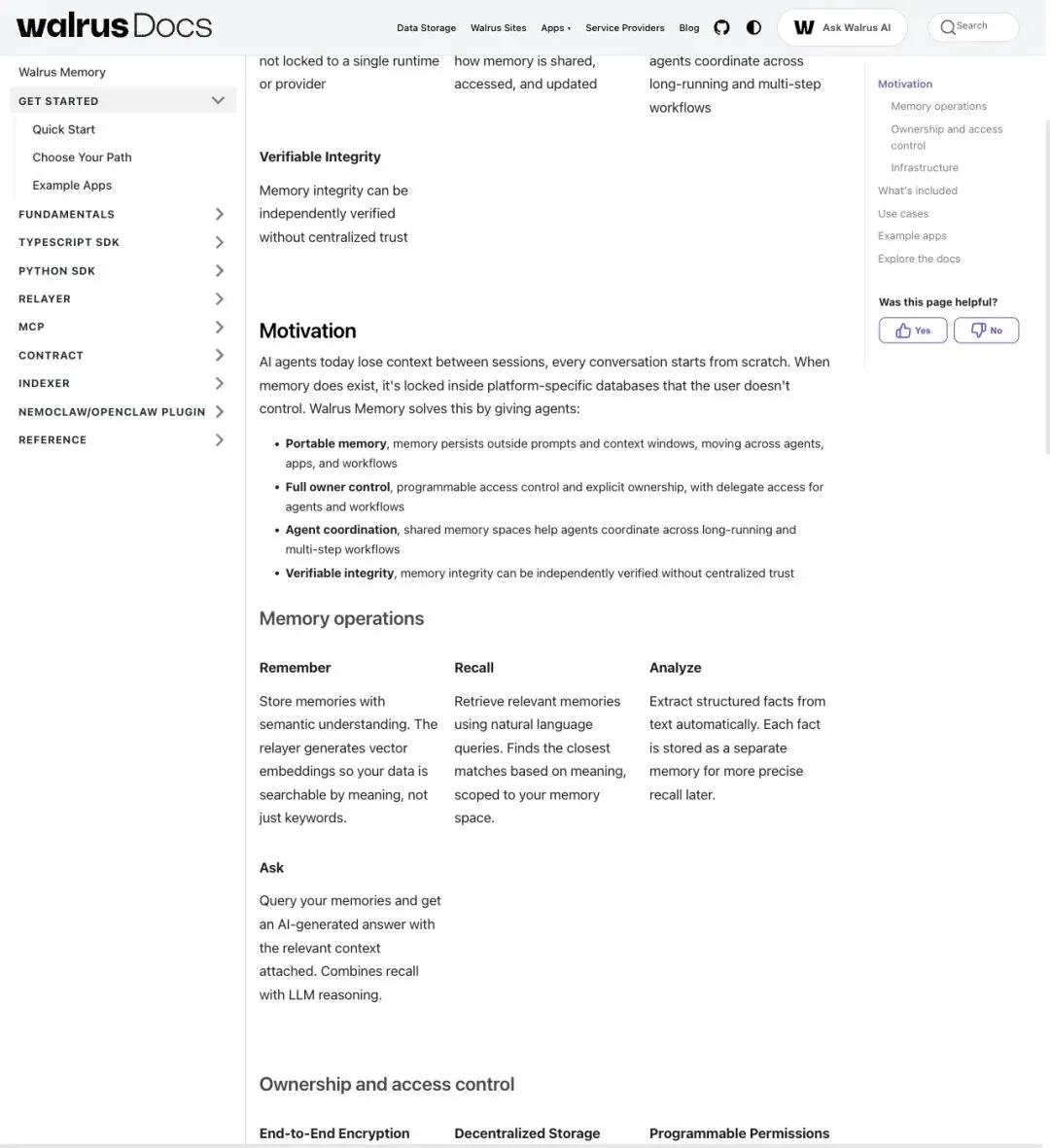
▲ 官方文档:展示了 Remember / Recall / Analyze / Ask 四类核心操作和 ownership / 加密 / 智能合约权限体系
基础操作被拆成四个动词:Remember(存入记忆)、Recall(检索记忆)、Analyze(提取结构化信息)、Ask(基于记忆回答问题)。
产品页还列出了兼容路线:支持 Claude、ChatGPT、Gemini 等主流 LLM,提供 OpenClaw 和 NemoClaw 的一方插件,原生支持 MCP 协议,SDK 覆盖 Python、TypeScript、JavaScript。
▲ 官方产品页:顶部标注「Build AI agents that remember with Walrus Memory」
需要注意:Walrus 声称这些兼容路线由它自己的 SDK 提供接入能力,目前没有证据表明这是与 Claude、ChatGPT、Gemini 各平台的官方联合发布。
比「聊天记忆」大一圈:它在做 Agent 的工作流协调层
如果只看「记住对话」,Walrus Memory 和市面上已有的 memory tools、向量数据库、Redis 方案很难拉开差距。
但 Walrus 在 4 月发布的 OpenClaw / NemoClaw 集成文章透露了更大的野心:多 agent 工作流的协调层。
▲ 3 月背景博客:Walrus 把 memory 定义为 agent 生产部署的瓶颈,提出 structured memory spaces 和 relayer 架构
在这个设想里,记忆的形态远超聊天历史:
- workflow checkpoints
:多步骤任务中断后可以从断点恢复 - reasoning traces
:agent 的推理过程被持久化,可追溯、可审计 - shared memory spaces
:多个 agent 可以共享同一块记忆空间,实现协作 - execution summaries
:每次运行的摘要被保留,跨环境、跨团队可复用
"open, portable, and not tied to a single vendor"
「开放、可携带,不绑定单一供应商。」
按 Walrus 的定位,这套东西更接近一个agent memory runtime,远超普通向量检索库的范畴。
社区反应:有人看到缺口,有人等着看 adoption
截至发稿,Walrus 的官方 X 发布帖已被超过 20 万次查看。
社区反应大致分三类:
认可方向的人。有开发者在回复里说「Portable memory is the missing piece for agents」——agent 真正缺的,是跨工具、跨时间的连续性。
提出产品追问的人。市面上已有大量 memory tools、plugins、向量数据库方案,Walrus Memory 到底有什么根本区别?Walrus 给出的差异化主张包括链上 ownership、delegate access、verifiable integrity 和一体化的 plugin + relayer + storage + smart contract 架构。但这仍然是产品层面的自我区分,市场还没有验证这套方案一定优于更成熟的 Redis、S3 或其他 agent memory 栈。
冷静观望的人。有回复指出,技术突破看起来重要,但最终要靠 adoption 来证明。这个判断成立——Walrus 目前能证明的是产品页、文档、SDK、开源仓库和生态引用都存在,但还不能凭这些证明自己已成为跨平台 agent memory 的事实标准。
还在 beta:别把蓝图当成品
几件事需要放在一起看。
第一,Walrus Memory 目前仍标注 beta。官方文档和 GitHub README 都明确写了:
"Walrus Memory is currently in beta and actively evolving."
「Walrus Memory 目前仍处于 beta,且在持续演进。」
这意味着 developer experience 还在打磨,运维指引还在补全,稳定性和 adoption 都不能按成熟基础设施来评估。
第二,GitHub 仓库(MystenLabs/MemWal)目前只有 26 个 star 和 6 个 fork。代码公开、Apache-2.0 许可,路线可接入、可审查,但规模上离「基础设施级别的社区共识」还有距离。
第三,「打破平台锁定」在当前阶段仍属于 Walrus 的产品主张和设计目标。它提供了一套围绕 portability、control、verifiability 的具体实现,但最终能否真正改变 agent 记忆的归属权格局,取决于开发者是否买账、生态是否跟进、链上方案在性能和体验上能否和中心化方案竞争。
记忆层正在从模型平台里独立出来
抛开 Walrus 这一家的具体路线,agent 需要独立于平台的记忆基础设施——这个判断正在被越来越多的工程实践验证。
上下文窗口能解决「当前对话」的记忆问题,但解决不了跨 session、跨工具、跨团队的长期状态管理。agent 一旦从「单轮对话助手」进化成「长时运行的多步骤系统」,就必然需要外部记忆层——而这层记忆放在谁手里、谁能控制、能不能迁移,将直接决定开发者和用户在 AI agent 生态里的自由度。
Walrus 给出的答案带着明显的区块链基建色彩:数据放 Walrus,权限交 Sui 合约,内容用 Seal 加密。这条路线不一定是所有 AI builder 想要的默认方案,但它确实指出了一个和「把所有记忆留在闭环平台里」完全不同的方向。
至于这个方向能走多远——答案在 adoption 里,在真实的多 agent 工作流里,在开发者用脚投票的选择里。
— END —
