夜雨聆风
夜雨聆风链接:https://pan.baidu.com/s/15r0rLWkJlcecUvBPKZo_MQ?pwd=mnsj提取码:mnsj
https://www.mizhushare.com/docs/
在科研实验设计中,经常会遇到一类“分组里再分小组”的数据结构。例如:
不同班级里,嵌套不同学生;
不同地区里,嵌套不同学校; 不同工厂批次里,嵌套不同检测样品。
这种因素之间存在层次结构的设计,就是我们常说的【嵌套设计(Nested Design)】。
嵌套设计:
嵌套设计(也叫巢式设计、窝设计或系统分组设计),属于多因素实验设计,因素之间存在层级隶属关系,无交叉、无交互作用,次级因素完全嵌套在一级因素内部,不同一级因素下的次级因素相互独立、不通用。
简单来说就是:因素B的不同水平只在因素A的某一个水平下出现,而不是在所有水平下都出现。因为因素之间不是完全交叉的,所以嵌套设计中不存在所谓的“交互作用”,这一特点把它和析因设计区别开来。
示例说明:

本次将通过嵌套设计方差分析探究不同催化剂、以及同一催化剂下不同温度对转化率的影响。
一、菜单操作:
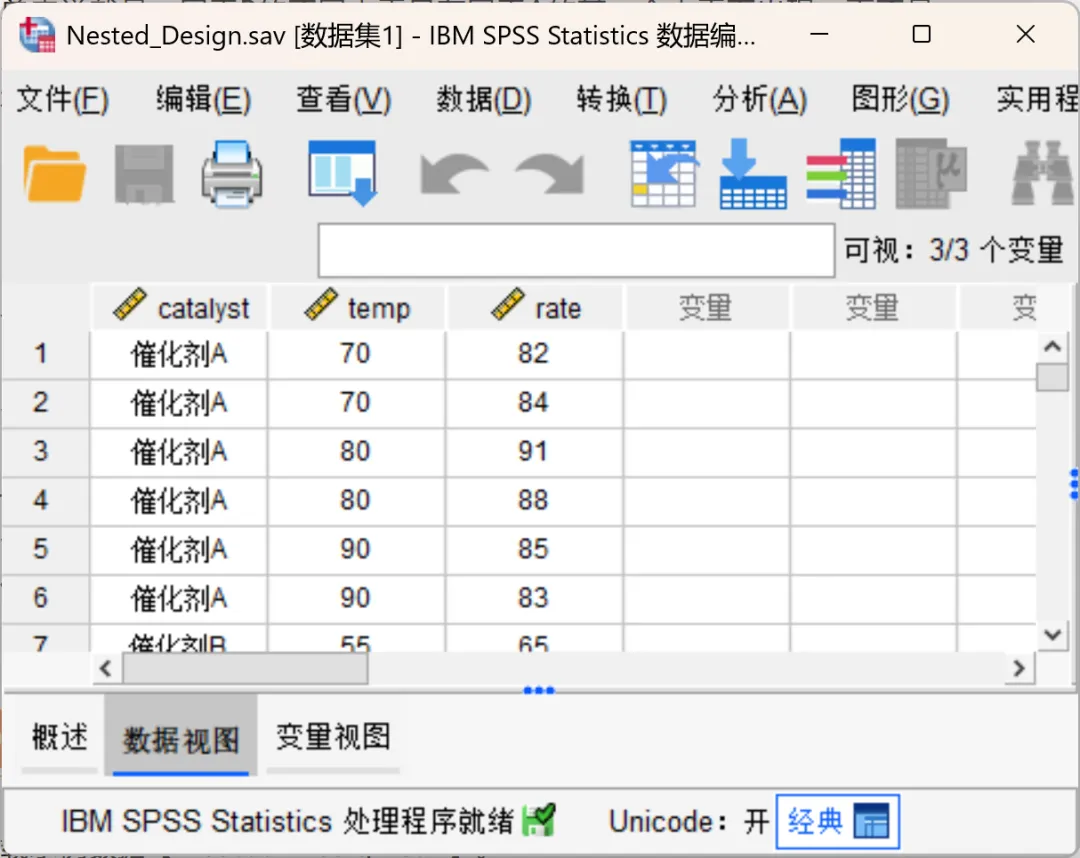
点击顶部菜单栏的【分析→一般线性模型→单变量】,在打开的对话框中进行相应设置。
将「转化率(rate)」设置为因变量。
将「催化剂(catalyst)」、「温度(temp)」设置为固定因子。
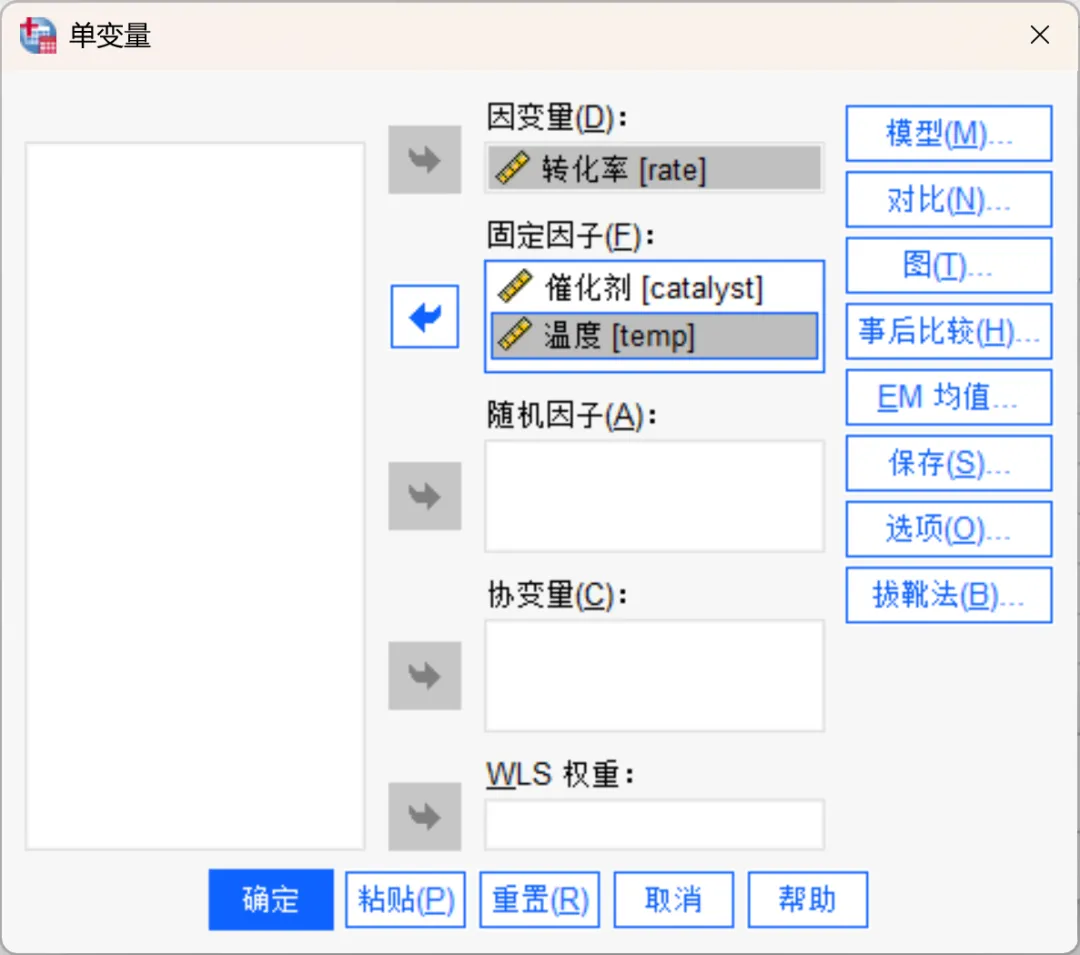
点击「模型」按钮打开「单变量:模型」对话框。
因为嵌套设计中不存在交互作用,因此本次将「模型」设置为「构建项」。然后将「构建项类型」设置为「主效应」,然后分别将「催化剂(catalyst)」、「温度(temp)」变量移入「模型」框中。
点击「事后比较」按钮打开「实测平均值的事后多重比较:模型」对话框。
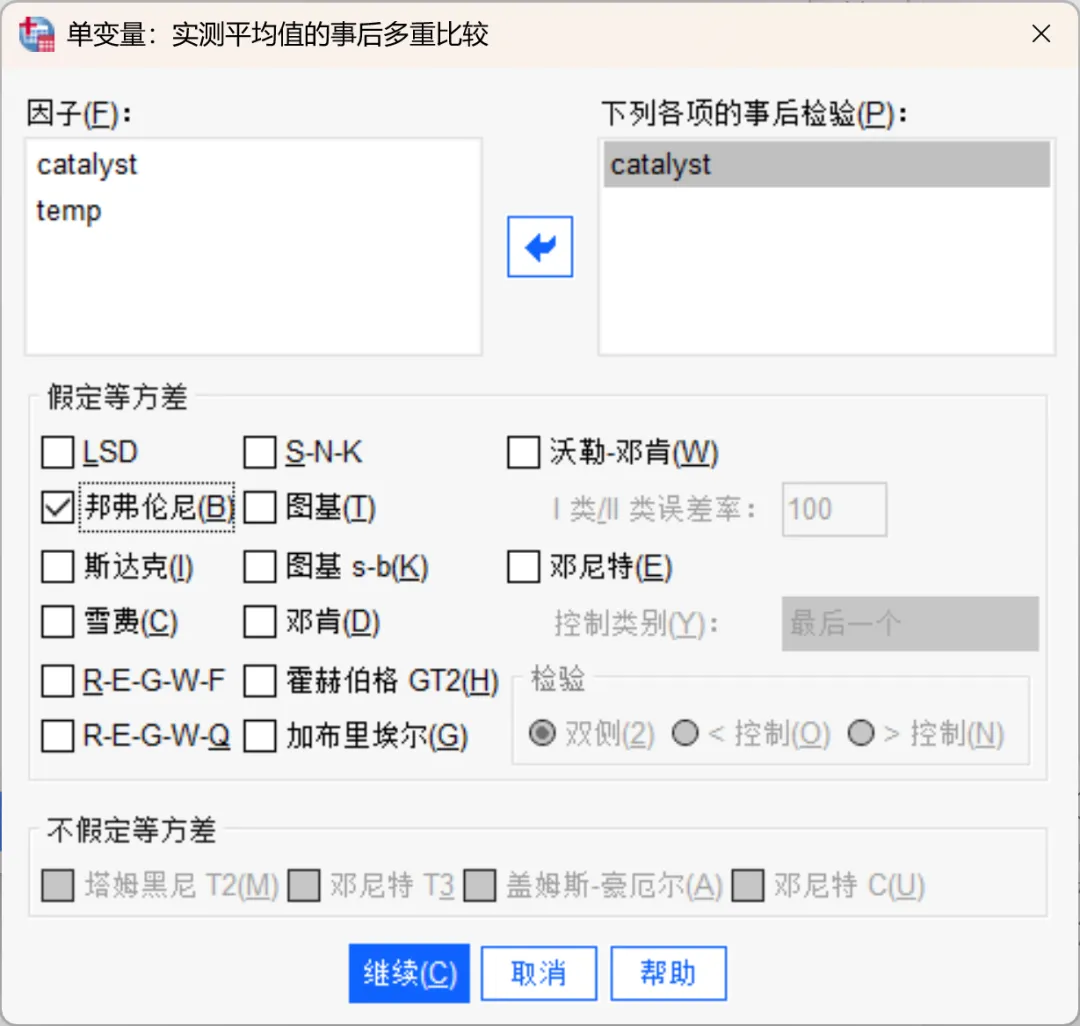
因为需要对催化剂之间进行多重比较,因此将「催化剂(catalyst)」移入「事后检验」框中,并勾选「邦弗伦尼(Bonferroni)」多重比较方法。
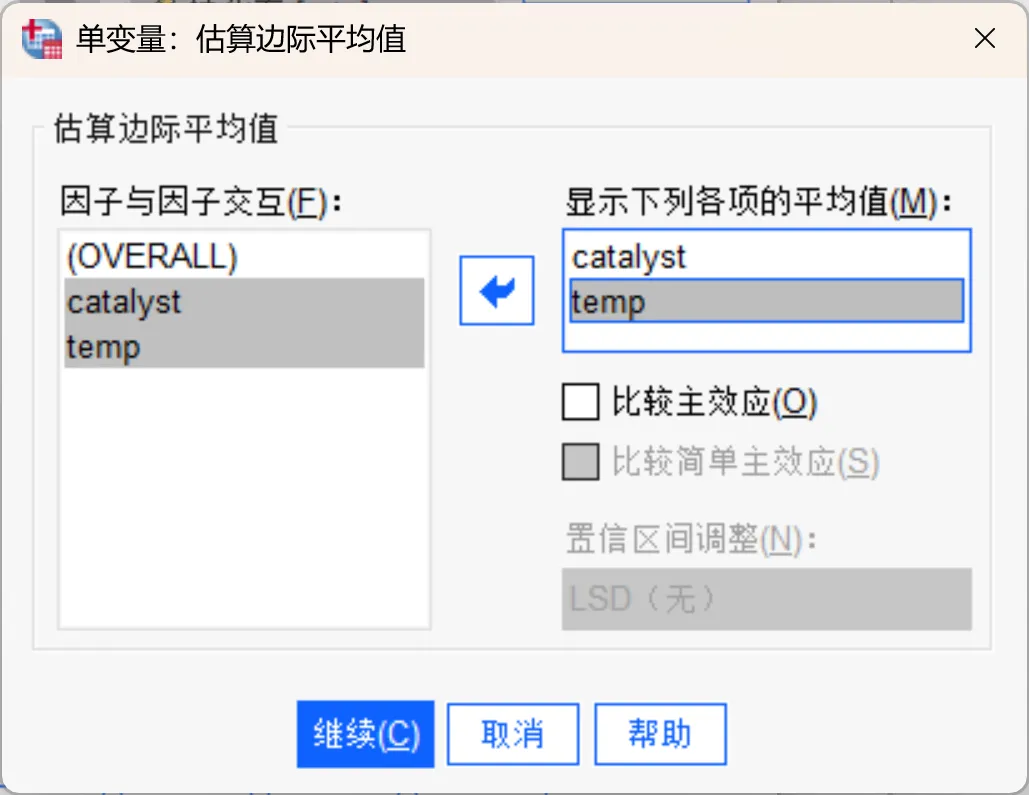
点击「EM均值」按钮打开「单变量:估计边际平均值」对话框。
本次将「催化剂(catalyst)」、「温度(temp)」变量移入「平均值」框中。
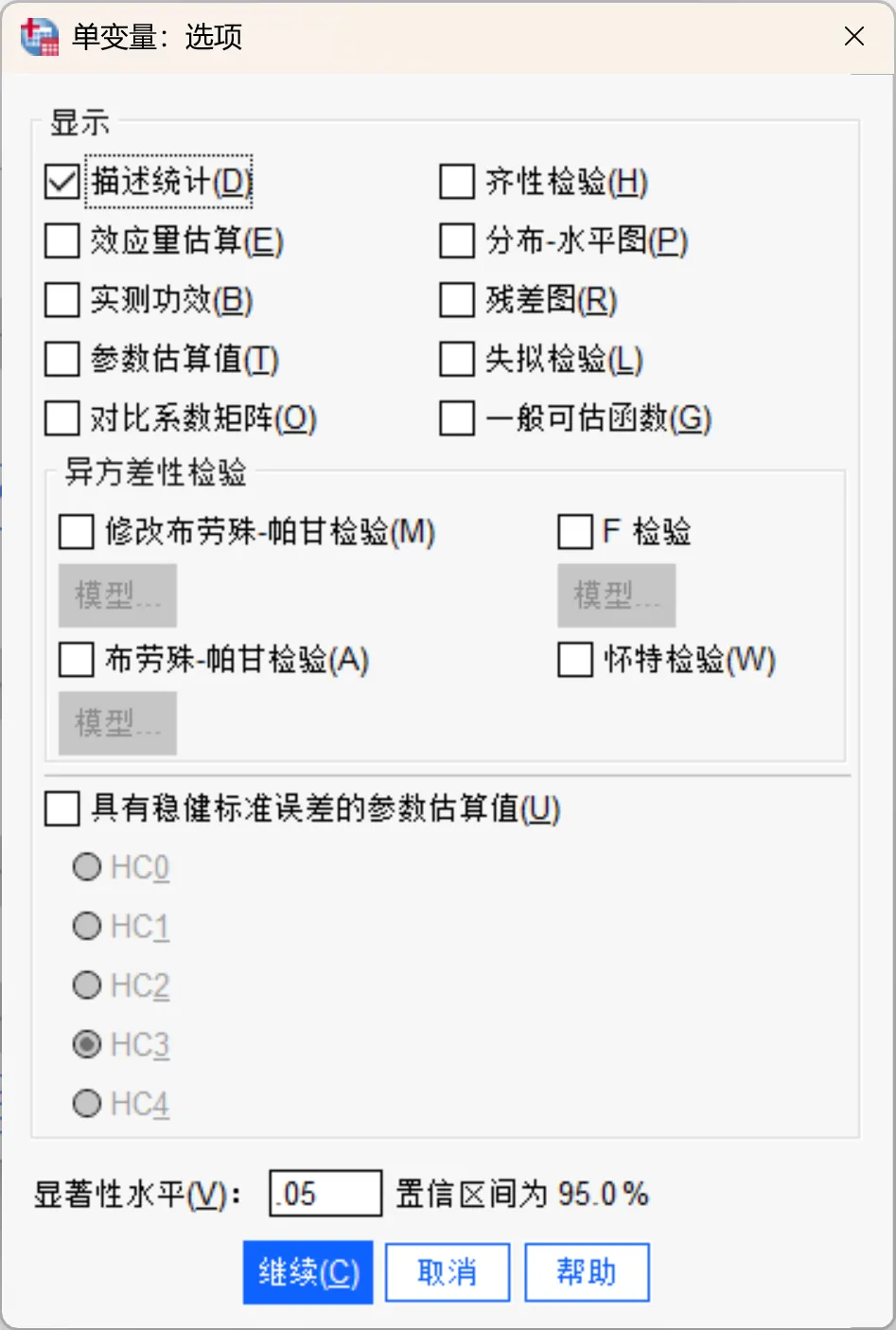
点击「选项」按钮打开「单变量:选项」对话框。
本次勾选「描述统计」。因为嵌套设计非完全随机分组,因此不需做齐性检验。
二、修改语法:
设置完成,点击「粘贴」按钮,SPSS会弹出语法窗口,自动生成以下程序:
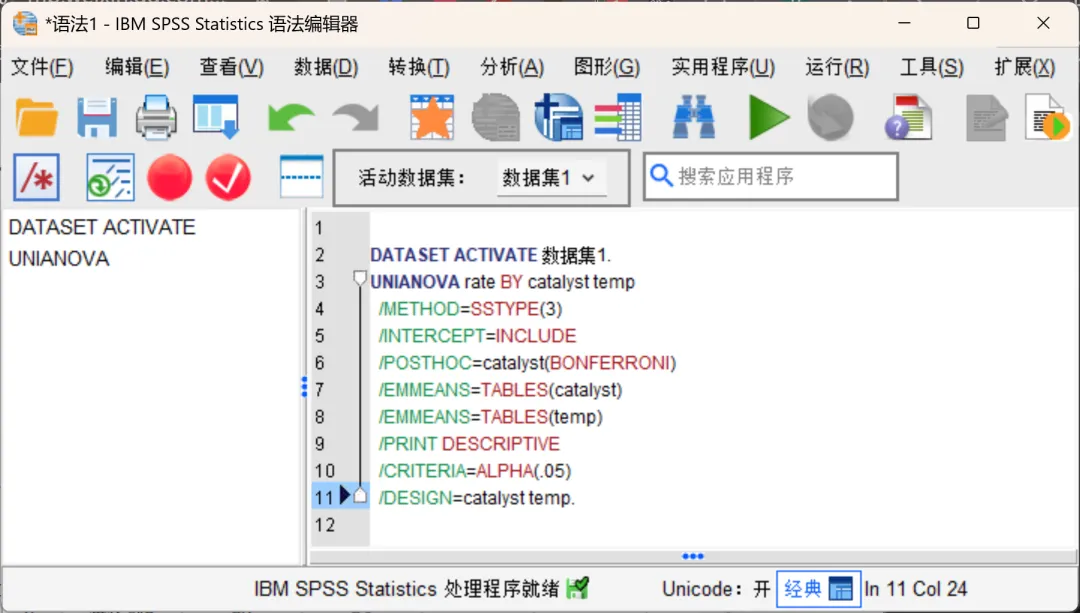
修改最后一行语法,从而将模型修改为嵌套模型:
* temp(catalyst) 表示“温度嵌套于催化剂之内” .* 告诉SPSS这不是一个交叉设计,而是一个嵌套设计 ./DESIGN=catalyst temp(catalyst)
此外,为了获得正确的一级因素F检验,还需要在最后增加一行自定义检验,用温度(嵌套于催化剂内)的均方作为检验催化剂的误差项:
/TEST=catalyst vs temp(catalyst).修改后的完整语法如下:
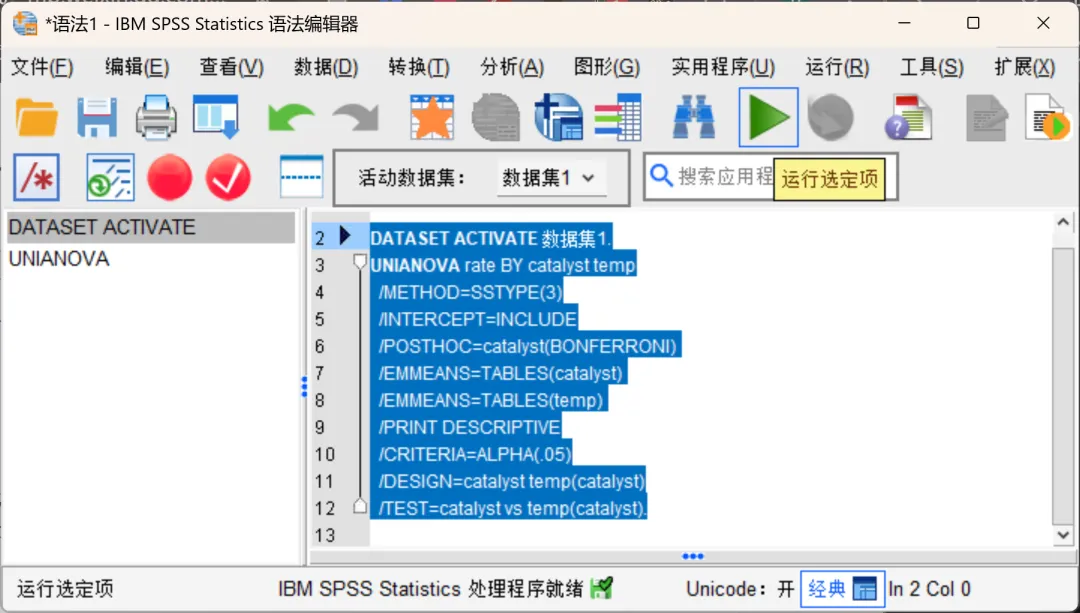
语法修改完毕后,点击语法窗口顶部的绿色运行三角按钮,执行分析。

输出结果一:主体间因子
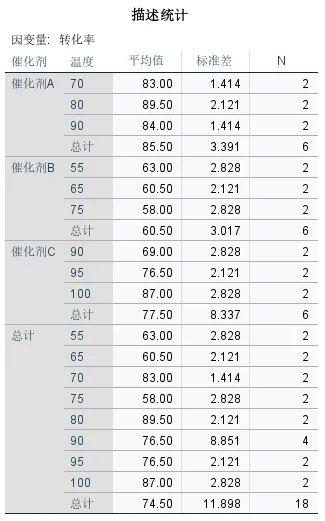
输出结果二:描述统计表
表提供了各组数据的基本概况,是观察初步趋势的关键。
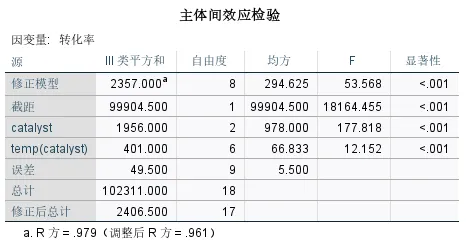
输出结果三:主体间效应检验
主体间效应检验表是嵌套设计的方差分析结果。
本次示例中,因变量是转化率,自变量是催化剂(主因子)和嵌套于催化剂下的温度(次因子):
catalyst(催化剂)效应:显著性P<0.001,说明不同类型的催化剂对转化率的影响有极显著差异。
temp(catalyst)(嵌套在催化剂下的温度)效应:同样显著(P<0.001),这表明即使在同一种催化剂内部,改变温度水平也会显著影响转化率。说明温度对转化率有显著影响,
需要注意的是,该表中catalyst对应的F检验中作为分母的误差项是组内误差(每个催化剂×温度组合下的重复样本误差),而不是嵌套因子本身的变异。因此对于嵌套设计而言,不能直接使用这个结果来判断催化剂的效应,需使用后续的定制假设检验结果作为判断依据。
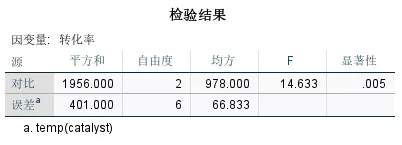
输出结果四:定制假设检验
该表这才是判断一级因素(主因子)的关键。该表计算F值时,用的是嵌套因子「temp (catalyst)」的均方作为误差项,这是更严谨的嵌套设计检验方法,因为它考虑了温度嵌套带来的变异。
经过更严苛的检验,催化剂的显著性P=0.005,虽然比之前的P<.001略大,但依然显著。这也证明了催化剂的效应是跨越不同温度水平依然稳健存在的。
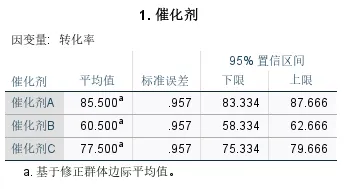
输出结果五:估算边际平均值
该表展示了控制了其他因素影响后,每个水平的均值及其95%置信区间。
催化剂的边际平均值表展示了三种催化剂校正后的平均转化率(修正群体边际平均值),消除了温度嵌套带来的干扰。可以看出,催化剂A的平均转化率最高(85.5),其次是催化剂C(77.5),催化剂B最低(60.5),三者差距非常明显,和之前描述统计的趋势完全一致。
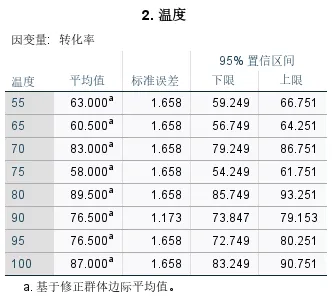
温度的边际平均值表展示了不同温度下校正后的平均转化率,同样是修正后的边际平均值。可以看出:
转化率的温度趋势:最高平均转化率出现在80℃(89.5),最低平均转化率出现在75℃(58.0)。
特殊的 90℃:90℃的标准误差(1.173)比其他温度的(1.658)小,这是因为该温度包含了催化剂A和C两组数据,样本量是其他温度的2倍,数据稳定性更高,置信区间也更窄。
嵌套效应的直观体现:不同温度的转化率差异,本质上是 “温度嵌套于催化剂” 的效应结果。55/65/75℃只出现在催化剂B中,所以转化率整体偏低;70/80℃只出现在催化剂A中,转化率整体偏高;95/100℃只出现在催化剂C中,转化率随温度升高而上升。
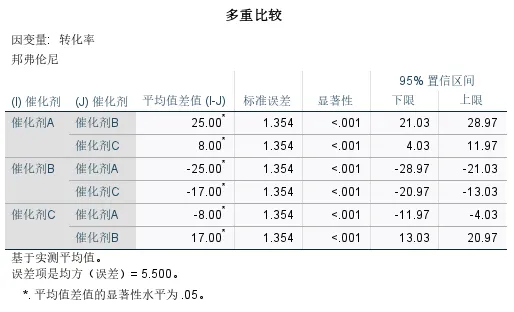
输出结果六:事后多重比较
该表是嵌套设计方差分析中,催化剂主效应的邦弗伦尼(Bonferroni)事后多重比较结果,用来判断三种催化剂之间的转化率差异是否两两显著。
本次示例中,有对比的 p 值都小于0.001,说明三种催化剂的转化率两两之间都存在统计学上的显著差异。根据差值方向(催化剂的估算边际平均值相减)判断,三种催化剂整体表现为A>C>B,这也与之前边际平均值表相对应。
需要注意的是,嵌套设计中只对主因子做多重比较。这是因为嵌套因子的水平是隶属于特定主因子的。比如“催化剂A下的80度”和“催化剂B下的55度”在统计上往往不具备直接横向比较的意义。我们更关心的是在特定主因子内部,嵌套因子是否造成了波动。