 夜雨聆风
夜雨聆风0基础vibe coding,借助AI,从0到1做出一款能用的桌面软件。前后推翻重做三版,踩过的坑比写出来的代码还多。这篇不讲代码,只讲故事。
一、写在前面:为什么我要做这个?
这是我第一次完全靠AI辅助,从零开始做一个桌面软件。
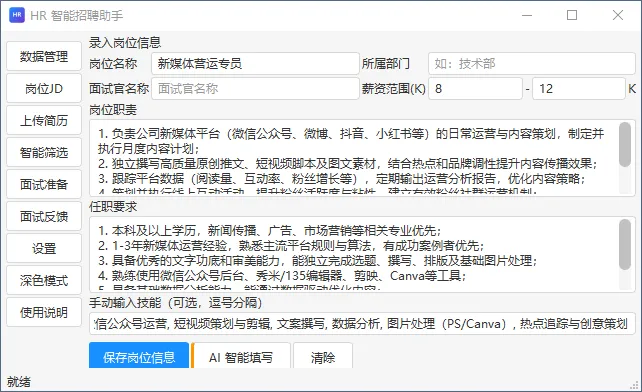
目标很实在——给HR日常办公用的智能招聘助手。前后推翻重做了三个版本,整整折腾了一个月,才算正式完工。
为什么选招聘这个方向?两个原因:
1. 我发现身边有不少非HR的朋友也要处理招聘流程,整理简历、筛选候选人,又烦又费时间。做出来就能直接帮到他们。
2. 招聘这件事,天然适合AI上场——简历自动读取、岗位匹配打分、定制面试问题、面试总结点评……全流程都能让AI搭把手。后续还能慢慢进化成真正的"智能招聘小助理"。
顺便说一句,受相关规范限制,这个软件暂时不做商业化售卖,纯粹是自己用+朋友用。
关于隐私,我特意把软件设计成本地使用 + 联网调用AI双选项。很多中小企业不愿意把求职者的身份证、电话、工作经历这些敏感信息上传到陌生平台。本地版所有数据都留在你自己电脑里;如果多人共用,或者电脑配置跟不上,也能切到线上AI模式。
核心一句话:成本和隐私,你自己说了算。
全文不贴代码,用大白话聊聊踩过的坑、三次改版的心路历程,以及产品设计上的小思考。不懂编程也能看懂。
二、用什么做的?为什么选这条路?
Python不是唯一能做AI的语言,但它是效率最高、生态最全、门槛最低的那个。
几乎所有大厂和开源社区都默认用它,想做AI交互,Python是前中期最好的选择。
实际做下来,换皮肤、后台批量处理简历、页面布局,都很省心。哪怕你不懂深层编程逻辑,借着AI的提示也能把界面搭出来。
三、三次全盘重做,新手踩过的坑我一个没落
全程用AI辅助开发,但盲目堆功能 + 选错工具,直接导致连续三次推翻重做。
V1:贪多求全,工具选错,全盘作废
第一版想法太多:简历管理、AI筛简历、自动出题、面试记录……全想塞进去。
没有规划整体使用逻辑,想到哪改到哪。
选AI开发工具时,贵的太贵,国外的没中文。最后选了个国产带中文界面的,结果它的智能编码能力偏弱,代码看着在疯狂生成,成品却漏洞百出,连最基础的功能都没跑通。最后只能清空项目,从头再来。
V2:规划有了,但数据各玩各的
第二版学乖了,先写产品需求文档,还参考了多款大模型的建议。
文档越写越长,内容越来越冗余,最后手动删减精简才落地。
新麻烦来了:从简历录入、AI解析、标注分类,到预约面试、最终录用/淘汰,全流程数据根本没法联动。同一个候选人,在不同页面里信息不一致、不更新。数据像被切成了好几块,每次修一个bug只能解决单点问题,根本没法全局调整。无奈,再次换工具。
V3:敲定工具,五天精细化打磨
第三版沿用精简后的方案,换了一套更顺手的AI开发工具。
基础框架成型后,剩下5天全部用来做精细化优化:调界面排版、理顺数据流转、优化AI交互体验、全功能查漏补缺。
最终成品和第一版相比,已经是完全不同的东西了。
三次改版最深的一个感悟: AI写代码再快,如果没有统一的规范和清晰的产品思路,写得越快,后期返工越累。
四、一个普遍误区:别拿"完美人类标准"去要求AI
做这个软件的过程中,我发现一个很有意思的现象:很多人一听到AI工具,本能地就抵触,习惯性全盘否定——"AI这里不行""那里不准"。
他们总在用行业顶尖老员工的最高标准去要求AI。达不到人的完美水准,就直接弃用。
但AI本质就是个辅助工具。
你不需要它面面俱到、滴水不漏,只要它能帮忙搞定批量整理简历、初步筛选、自动写面试题这些机械重复的工作,帮你省下大把琐碎时间,这工具就已经值了。
用极致完美的人类标准去苛求AI,反而会忽略它实实在在的提效作用。

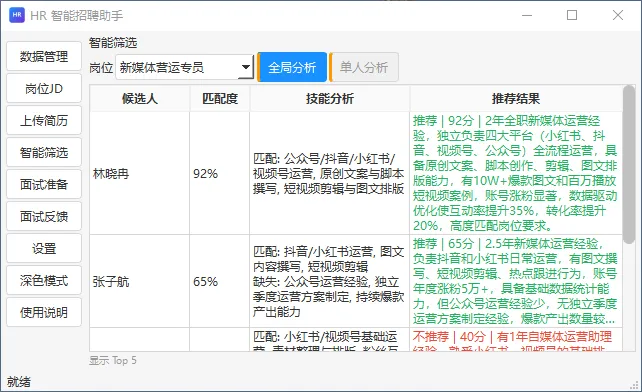
五、核心亮点:AI筛选简历的逻辑,我大改了一版
软件里AI有四种使用场景,不同场景下AI的风格也不一样:
• 简历信息提取:只做客观摘抄,不自由发挥。 • 岗位简历匹配打分:严格按岗位要求客观评分。 • 自动生成面试问题:适度灵活,根据候选人经历定制。 • 面试结果总结:结合HR的打分,客观整理评语。
优化1:放弃关键词比对,直接让AI读全文
最初的设计思路是:让AI分别提炼简历关键词和岗位关键词,然后靠关键词重合度来打分。落地之后发现漏洞很多——本地小模型提取关键词经常缺这少那,打分忽高忽低,参考价值很低。
后来灵机一动:AI既然能读懂整篇文字,为什么非要拆成关键词?
直接把完整简历 + 招聘需求一起扔给AI,让它综合评判打分。
优化之后,匹配精准度大幅提升。这个核心功能才算真正成型。
这里很容易陷入思维定势——传统开发做到一半要推翻重来,沉没成本很高。但大模型时代不一样了,重开的成本极低,而且往往因为架构更合理、需求更明确,重做比修修补补还快。
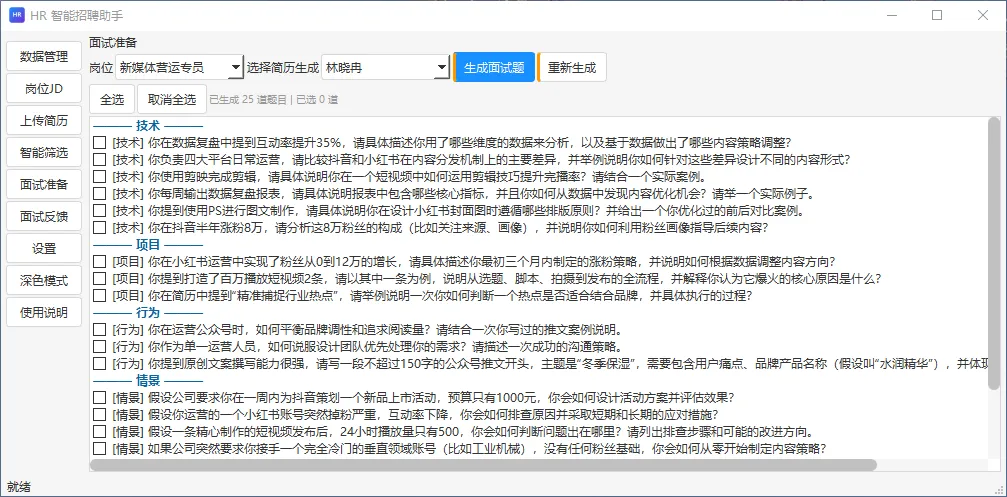
优化2:从"单一筛简历"升级为"全流程帮手"
开发过程中不断拓展功能:除了简历匹配,又加了一键生成招聘文案、自动出面试题、面试结束自动写评语。
原来的模式是"人为主,AI辅助";现在变成了AI承接重复性工作,员工重点做人工判断。
重复劳作实实在在地减少了。
六、五层简易架构:小软件也有清晰分工
软件内部从前端到后台分成五层,各司其职,严格遵守数据流转规则:
操作界面 → 简历&AI处理中心 → AI调用+数据存储 → 通用辅助工具
很多人觉得只有大型企业软件才算"好用"。但大型系统采购费用高、部署麻烦、还要专门培训员工。
而这款小软件聚焦HR单点招聘需求,轻量化、易上手,反而更适合中小公司日常使用。
七、数据本地储存,从根源解决隐私顾虑
按照国内个人信息保护相关法规,求职者的手机号、住址、工作履历都属于隐私。软件从设计上就规避了泄密风险:
所有简历数据默认保存在你自己电脑的文件夹里,软件没有自动上传到外网的设置。 AI接口密钥单独存放,跟简历资料分开。就算别人把你的软件整个拷走,也带不走API和数据。 PDF、Word原始简历解析完后可以自动删除,只保留整理后的结构化信息。
缺点也有:没法一键多台电脑同步数据。但对单人办公的HR来说,隐私优先级远大于多端同步,完全够用。而且这个软件定位就是小工具,功能加太多反而会模糊它的定位。退一步说,同样的功能,作为独立软件和作为大系统里的一个模块,区别是非常大的。

八、AI两种使用模式:本地离线 + 在线联网,自由切换
1. 为什么设计双模式?
有些企业的规章制度严禁把简历内容发送到外网。所以我开放了两种模式:
• 本地离线AI:不用联网,全部在你本机运算。
• 在线云端AI:联网调用商用大模型。
用户在设置界面一键切换就行。
📊 关键数据卡片
• 批量处理:5份简历打包发送,节省八成AI使用费和等待时间。
• 排队机制:同一时间只运行一项AI任务,防止软件卡死。
补充一句:本地部署AI的硬件入门成本可控,但不能照搬在线AI的用法。如果大批量简历全程用在线AI,长期开销不低。注重隐私、长期高频使用的用户,更适合本地部署。
这里是特地使用暗黑模式的图,因为整体配色适配的非常满意。
九、软件里那些让人舒服的小细节
- 统一排版
:全软件按钮、输入框大小、边距都统一,界面整洁舒服。 - 功能标注
:所有需要调用AI的按钮旁边都做了橙色标记(●),鼠标悬浮会提示,提前告诉你"这个功能要跑AI"。 - 多语言切换
:内置五种语言,简中繁中英语日语韩语,多语言适配0压力。 - 浅色/深色双皮肤
:一键切换,护眼暗黑模式或者常规浅色模式,随你心情。
十、测试:用真实简历"烤"了一遍
我收集了18份真实简历素材,包括PDF、Word、图片简历,甚至还有几个破损的无效文件,用来做全功能测试,覆盖了近百项检测点。
不刻意模拟AI运行,直接接入真实AI做功能校验。
这个小工具完全基于大模型和MinerU构建,一开始规划里还有一些冗余模块,后来全给剥离了——越简单,越可靠。
十一、写在最后:一个月能换来什么?
历时一个月,从一个简陋的简历存档页面,迭代成了一款AI全链路辅助招聘工具。
整个项目最宝贵的经验其实就一句话:动手开发之前,先把产品规范定好。界面、数据、AI调用、文档、测试,全部提前梳理出标准,能避开绝大多数返工问题。
一点致谢
本软件使用 OpenCode 进行开发,DeepSeek-V4-Flash 作为主力开发模型。特别感谢上海AI实验室 OpenDataLab(书生·浦语 InternLM 团队)开源的 MinerU——工业级文档结构化解析引擎,专治PDF/图片/Office转Markdown/JSON,是目前RAG知识库和LLM训练最主流的文档预处理工具。目前直接注册后可以免费使用。小规模体验的话,可以全部采用在线模式。本地模型采用的是Jackrong/Qwen3.5-9B-DeepSeek-V4-Flash-GGUF,Q5量化,感谢相关作者对开源大模型的贡献。
相关服务注册地址:
https://www.deepseek.com/
https://mineru.net/
如果你也在尝试用AI做小工具,欢迎交流踩坑经验。毕竟,AI不会替你掉坑,但坑可以一起少掉几个。
