 夜雨聆风
夜雨聆风别再指望 AI 帮你重构万行老代码了:真正能落地的是“绞杀者模式”
实战分享:如何让 AI 编程助手在不崩盘的前提下,逐步蚕食历史遗留系统的老代码
作者: ExploreAll|日期: 2026-06-07|阅读时间: 约 9 分钟
很多程序员把 AI 当作包治百病的“神药”,一拿到历史遗留项目的万行老代码,就迫不及待地让 AI 一键重构。结果往往是代码改得千疮百孔,系统彻底崩盘。AI 时代重构的正确姿势,绝不是“大乾快上”的推倒重来,而是用“绞杀者模式”进行蚕食与更替。 |
接手过历史遗留项目的朋友,大概都体会过那种“在高速公路上给开着的跑车换轮子”的无力感。
代码库里动辄是上千行、没有任何注释、嵌套了七八层 if-else 的“祖传代码”。你不敢轻易改动它,因为你根本不知道它在哪个隐秘的角落跟别的业务模块发生了耦合。
这时候,市面上铺天盖地的 AI 编程助手(比如 Cursor 或 Claude Code)看起来像是一个完美的救星。你心里一乐:把这几万行的老文件一把复制塞给 Claude,让它帮我用最新的框架、最优雅的模式重构一遍,岂不是美滋滋?
AI 表现得极为敬业,几秒钟就吐出了几千行排版整齐、逻辑通顺的新代码。当你兴高采烈地把它们贴进项目,点击运行——
控制台瞬间被几百个编译器错误和诡异的运行时报错淹没。
你开始根据报错让 AI 继续修改,它指挥你改 A 依赖,又让你重写 B 模块。折腾了两天后,你的 Git 分支改动已经多到无法控制,而项目依然连跑都跑不起来。最终,你只能在一声叹息中默默输入 git checkout .,顺便在心里给大模型打上一个“华而不实”的标签。
其实,错的不是 AI,而是你重构的方法论。指望 AI 一键帮你推倒重构几万行的复杂系统,在逻辑上就是一条死路。
图 1:VS Code 中庞大臃肿的历史遗留代码,充满各类警告
一、为什么 AI 一键重构老代码注定会崩?
为什么现在的 AI 能够写出完美的单体小模块,却在面对老代码重构时频频翻车?核心原因有三个:
第一,注意力稀释与幻觉。 虽然主流大模型的上下文窗口(Context Window)已经扩展到几十万甚至上百万 Token,但“能装得下”不等于“理解得精”。当老代码文件极其庞大时,AI 的注意力会被大量冗余的业务代码稀释,在生成新代码时就会漏掉关键的隐式边界逻辑。
第二,无法感知的“隐式耦合”。 老系统最可怕的地方在于,那些没有写在当前文件里的“历史遗留潜规则”。比如某个全局变量在初始化时的微小延时,或者某个被遗忘的数据库触发器。AI 只能看到你喂给它的代码,却看不到整个复杂的运行环境。这种信息不对称,注定了它重构出的代码只是“看起来很美”。
第三,测试闭环的缺失。 一次性修改太多的代码,会导致测试链路完全断裂。你根本分不清是哪个函数在重构后出了问题,AI 也无法在如此庞大的改动量中进行逐步排查。
图 2:AI 一次性输出整套庞大系统代码导致运行报错的典型失败现场
二、架构演进的智慧:什么是“绞杀者模式”?
既然一键重构不可行,那在 AI 时代,我们到底该如何安全地翻新历史遗留系统?
在传统软件架构中,有一个非常经典的设计模式,叫做绞杀者模式 (Strangler Fig Pattern)。这个名字源于热带雨林中的“绞杀榕”:
它的种子落在老树的顶端,向下发出气生根,顺着老树的树干伸入土壤。随着时间的推移,这些根系越来越粗,织成一张网,牢牢把老树包裹在里面。老系统(老树)不再增长,而新系统(新树)逐步接管所有的营养(流量)。最终,老树枯死,绞杀榕成为一棵完全独立的新树。
在软件重构中,绞杀者模式的核心思想是:不对老系统的代码进行伤筋动骨的修改,而是在老系统外围建立新的功能模块。通过一个路由或代理层,将流量逐步从小功能点分流到新模块,直至老模块被完全替代、彻底下线。
在 AI 时代,这一机制被赋予了更加恐怖的效率——因为 AI 极其擅长做“局部切片”的高保真重构。
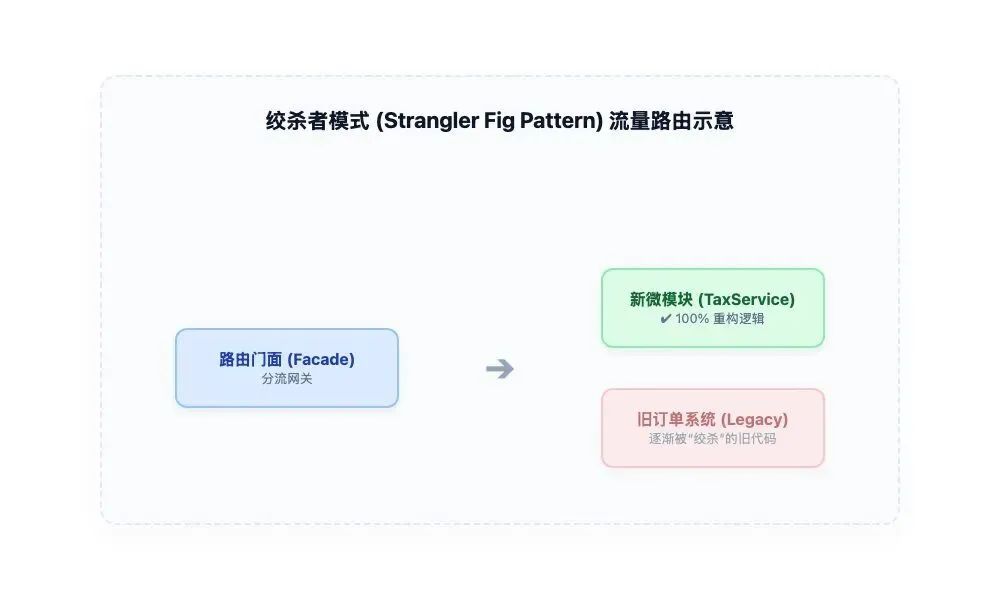
图 3:绞杀者模式 (Strangler Fig Pattern) 路由代理工作机制示意
三、AI 绞杀者重构工作流实战
下面,我们以一个真实的 Python 后台重构为例,看如何用 AI 落地这套工作流。假设我们有一个极其臃肿的老旧订单结算服务 LegacyOrderService。
### 第一步:用 AI 建立路由网关(Facade)
我们首先不修改任何老代码,而是让 AI 帮我们写一个门面代理(Facade)。它负责拦截流量,并根据我们迁移的进度,选择走新逻辑还是旧逻辑。
class OrderServiceFacade: def __init__(self, legacy_service, new_service): self.legacy = legacy_service self.new = new_service # 我们可以在这里配置迁移开关,比如只迁移某个商户的流量 self.migrated_methods = { "calculate_tax": True,# 已重构完成,走新逻辑 "apply_coupon": False# 仍走旧逻辑 } def calculate_tax(self, order_id): if self.migrated_methods.get("calculate_tax"): return self.new.calculate_tax(order_id) return self.legacy.calculate_tax(order_id)
有了这个代理层,新旧系统可以并存运行,甚至可以在生产环境中实现“灰度放量”。
图 4:在高度降噪的纯净单文件中,AI 对小段函数进行的局部精准重构
### 第二步:解耦核心逻辑,让 AI 进行“微重构”
不要把整个几千行的 LegacyOrderService 丢给 AI。
我们使用“二分法”或者局部解耦,每次只把一个 50 行左右的纯计算函数(例如 calculate_tax 税率计算逻辑)抽离出来,丢给 AI:
“请帮我重构下面这段 Python 的税率计算逻辑。要求:1. 使用 Python 3.10 的强类型提示;2. 增加完整的异常处理;3. 编写 3 个核心边界情况的单元测试。注意:不要引入任何外部依赖。” |
因为重构的输入范围极窄、没有业务噪声,AI 在这种“局部微重构”中的准确率高达 100%。
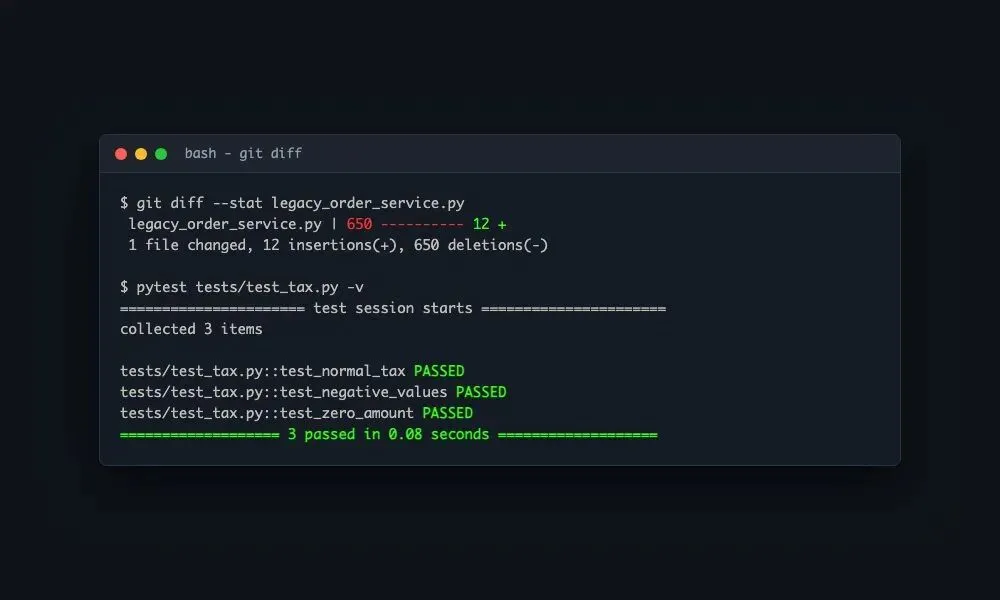
图 5:重构后老代码精简 90% 以上且通过全部单元测试的 git diff 反馈
### 第三步:双轨运行与“差错校验”
这是绞杀者模式中最安全、最爽的一步。
在将新接口完全切过去之前,我们让代理层同时调用新旧两个逻辑,对比它们的返回结果。这被称为双轨对比校验。我们甚至可以让 AI 帮我们写这个对比脚本:
def check_new_logic(order_id): # 同时调用新老服务 legacy_result = legacy_service.calculate_tax(order_id) new_result = new_service.calculate_tax(order_id) # 差错比对 if legacy_result != new_result: # 记录不一致的 case,用于修正新逻辑 logger.warning(f"Diff found on order {order_id}: Legacy={legacy_result}, New={new_result}") return legacy_result# 生产环境依然以老逻辑为准,保证绝对安全 return new_result
通过生产环境的真实流量跑上几天,如果没有任何 Diff 报警,说明新重构的模块在逻辑上与老系统完全一致。此时,我们就可以放心地把开关彻底拨向新系统。
✦✦✦
四、写在最后:人机协同的降噪艺术
从“一键重构”到“绞杀者模式”,改变的不仅仅是代码的迁移方式,更是我们对 AI 能力的认知。
在 AI 编程的语境下,重构的本质,其实是一场降噪的艺术。
把万行代码塞给模型是创造噪声,而用门面路由和微服务化隔离出干净的局部代码,则是极致的降噪。只有在足够低噪的上下文里,大模型才能发挥出它最极致的推理与生成能力。
下一次看着手里的屎山老代码抓耳挠腮时,别再命令 AI 一次性重写了。架起你的路由网关,像森林里的绞杀榕一样,一步一步、优雅而安全地蚕食掉那些历史遗留问题吧。
✦✦✦
如果你对微信公众号的排版提效、AI 编程的最佳实战技巧感兴趣,欢迎点击“在看”并关注本公众号。如果你在重构老代码时踩过什么坑,欢迎在评论区留言交流,我们下期不见不散! |
