 夜雨聆风
夜雨聆风项目卡片
项目:agentmemory[1] 状态:v0.9.24 / 19.8K Star / 2026年2月创建,3个月近2万星 一句话判断:目前最完整的 AI 编程助手记忆方案——自动捕获、跨 Agent 通用、检索准确率碾压基线
用 AI 编程助手写代码的人大概都有这个体验:
第一次会话,你让助手加了 JWT 认证。第二次会话,你接着说"加个限流"。助手不知道你上次用了 jose 中间件、测试文件在 test/auth.test.ts、选 jose 而不是 jsonwebtoken 是为了 Edge 兼容性。
你又花 5 分钟重新解释一遍。
第三次会话又来。
这不是某一款助手的 bug——所有 AI 编程助手都有这个问题。Claude Code 有 MEMORY.md,Cursor 有 Notepad,Cline 有 Memory Bank。它们本质上都是便签纸:写多少你自己决定,搜不到什么,写到 200 行就得手动删。
agentmemory 要解决的就是这件事。
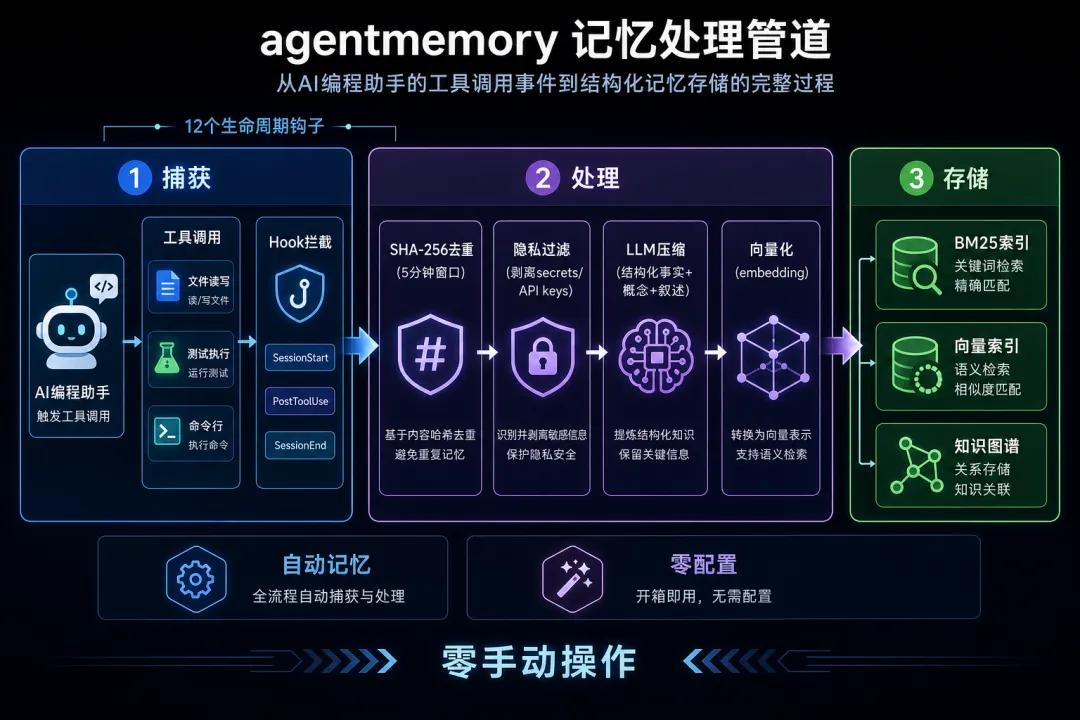
agentmemory 在后台跑一个轻量记忆服务器。你的编程助手每用一次工具——读写文件、跑测试、执行命令——它就自动捕获,压缩成结构化记忆,建索引。
下次开新会话,根据当前上下文自动检索相关记忆注入对话。你的助手直接"知道"上次做了什么。
没有手动 add() 调用,没有复制粘贴。仓库文档里管这个叫"12 个生命周期钩子"——其实就是拦截了助手从 SessionStart 到 PostToolUse 再到 SessionEnd 的关键事件,全程静默。
试一下最快要多久:
npx @agentmemory/agentmemory— 启动服务器npx @agentmemory/agentmemory demo— 灌入示例会话,看语义搜索效果npx @agentmemory/agentmemory connect claude-code— 连接你的编程助手
做记忆系统,这个指标决定一切。
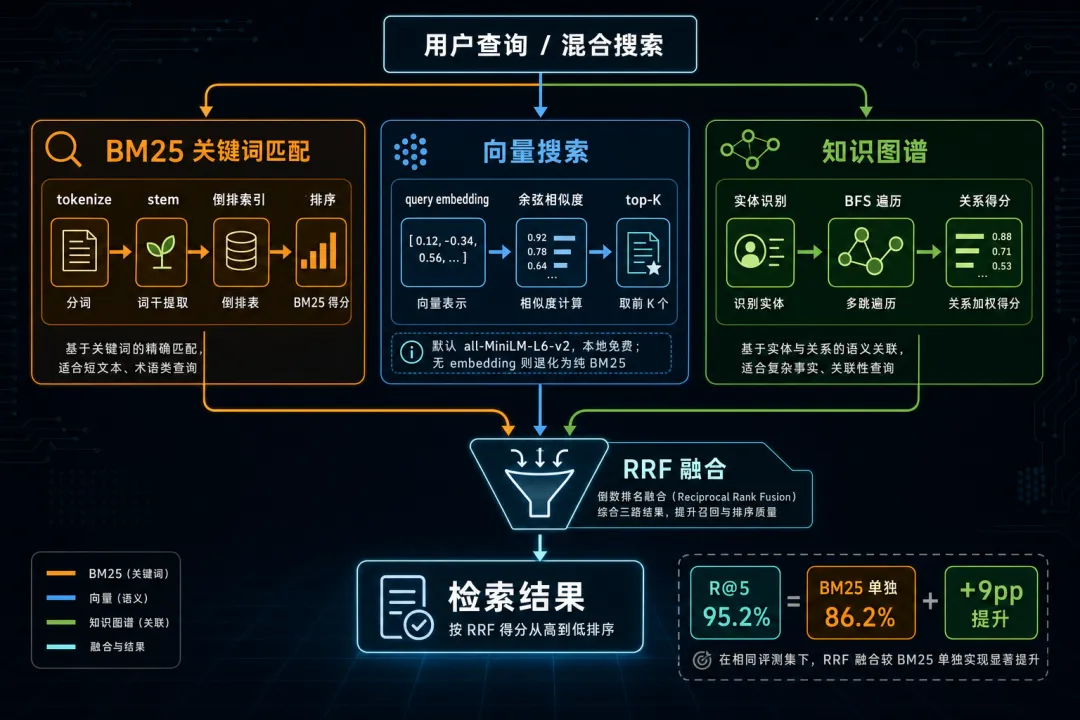
agentmemory 在 LongMemEval-S(ICLR 2025,500 道题)上跑出 95.2% R@5——每 5 个候选里命中目标的概率。纯 BM25 关键词是 86.2%,grep 基线虽然覆盖率一样,但精确率只有 agentmemory 的一半不到。
三路搜索并行跑:
BM25:关键词匹配,永远在线 向量搜索:语义相似度,需要 embedding provider 知识图谱:实体关系遍历,通过图谱连接发现间接关联
三路结果用 RRF(Reciprocal Rank Fusion)融合排序。embedding 默认用 all-MiniLM-L6-v2,本地跑、免费、不需要 API key。不装的话退化为纯 BM25,也能用。
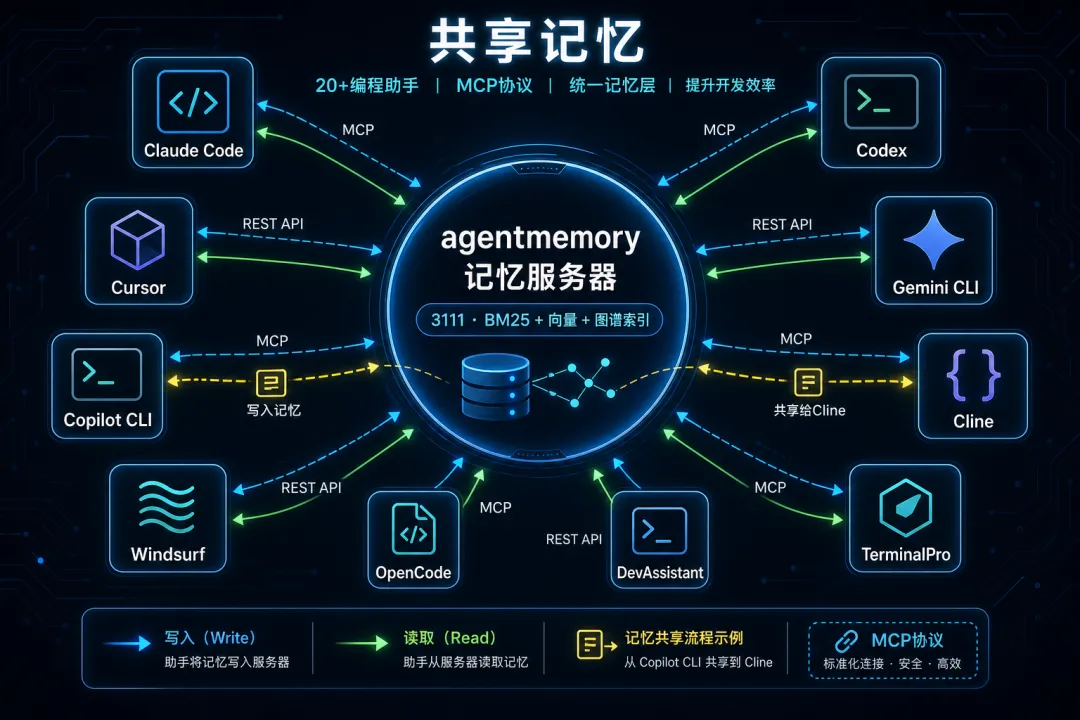
agentmemory 支持的编程助手数量确实多:Claude Code、Codex CLI、GitHub Copilot CLI、Cursor、Gemini CLI、OpenClaw、Hermes、OpenCode、Cline、Windsurf、Goose、Aider……超过 20 个。
统一走 MCP(Model Context Protocol)或 REST API 连接。你的 Claude Code 会话产生的记忆,Cursor 也能检索到。
这种"一个记忆、多个消费者"的模式,mem0 做不到(需要手动调 API),Letta 做不到(绑定自己的运行时),各家内置方案也做不到(各管各的)。
编程助手的上下文窗口是按 token 收费的。如果你选择每次把历史全贴进去——很快就超过窗口限制,一年 1950 万 token,实际不可行。
LLM 摘要方案好一些,一年约 65 万 token,花费约 $500。
agentmemory 只注入 token 预算内的相关记忆(默认 2000 token/会话),一年约 17 万 token,约 $10。如果用本地 embeddings,这笔钱也可以省掉。
仓库里内置了 token 节省计算器,跑几个会话后执行 agentmemory status 就能看到省了多少。
agentmemory 有 4 层记忆结构,参考了人脑的记忆处理:
| 层级 | 类比 | 内容 |
|---|---|---|
| 工作记忆 | 短期记忆 | 每次工具调用的原始记录 |
| 情景记忆 | "发生了什么" | 压缩后的会话摘要 |
| 语义记忆 | "我知道什么" | 提取的事实和模式 |
| 程序记忆 | "怎么做" | 工作流和决策模式 |
不常访问的记忆会衰减(仓库文档说是"艾宾浩斯曲线"),经常使用的会强化,矛盾的记忆会被检测。这套整合需要配置 LLM provider 才启用。BM25 模式下正常工作,只是没有 LLM 压缩和图谱提取。
我一开始看到"4 层记忆整合"以为是噱头,但仔细看了 consolidaton 的代码逻辑,发现确实在 SessionEnd 时做了 session 摘要压缩、图谱节点提取、lesson 生成——不是空壳。
最低门槛只需 Node.js 20+:
# 终端 1:启动服务器
npx @agentmemory/agentmemory
# 终端 2:跑 demo
npx @agentmemory/agentmemory demo
demo 灌入 3 个真实会话(JWT 认证、N+1 查询修复、限流),跑语义搜索。搜"数据库性能优化"能命中"N+1 查询修复"——纯关键词做不到。
连 Claude Code 用两步:
agentmemory connect claude-code # 写入 MCP 配置
npx skills add rohitg00/agentmemory -y # 安装 8 个原生技能
打开 http://localhost:3113 看记忆积累的实时界面。
我试装的时候发现几个坑,提前说一下:
零外部依赖不等于零配置。 agentmemory 本身只需要 SQLite(通过 iii-engine 内置),但它需要安装 iii-engine 这个原生二进制作为运行时。macOS/Linux 有预编译包,Windows 需要手动下载或用 Docker。
LLM 功能需要额外配置。 不配置 API key 也能跑(noop 模式,BM25 压缩 + 搜索照常工作),但 LLM 压缩、摘要、图谱提取、4 层整合都需要 provider。仓库支持 OpenAI、Anthropic、Gemini、OpenRouter、MiniMax,也支持 Ollama/LM Studio 等本地模型。
成本敏感场景建议用本地模型。 仓库明确推荐 DeepSeek V4 Pro 和 Qwen3 Coder 做压缩工作——质量接近 Sonnet 4.6,成本约十分之一。7B 模型对于压缩和摘要任务够用。
隐私设计比较靠谱。 API key、secret、<private> 标签在存储前会被自动剥离。REST API 默认绑定 127.0.0.1,远程部署需要手动设 AGENTMEMORY_SECRET。
项目还在 v0.9,没到 1.0。 功能迭代很快(3 个月 24 个版本),但 API 可能变。路线图规划 Q1 2027 才冻结 REST + MCP 表面。 iii-engine 依赖。 agentmemory 基于 iii 引擎构建,目前锁定 v0.11.2。如果 iii 生态不成熟,这可能成为风险点。 中文/Japanese/Korean tokenization 需要额外安装分词器。 不装的话退化为整词匹配,精度会降。 Codex Desktop 的 hook 还有个上游 bug(openai/codex#16430),需要手动绕路。 对比 mem0(53K star)和 Letta(22K star),agentmemory 在自动捕获和跨 Agent 通用性上有明确优势,但 mem0 有托管云选项,Letta 提供完整的 Agent 运行时。选哪个取决于你要不要记忆之外的东西。
如果你日常用 AI 编程助手写代码,并且经常在多个会话之间重复解释项目背景——agentmemory 是目前解决这个问题最完整的方案。
推荐的上手路径:先用 npx 跑 demo 看效果,然后全局安装连上你最常用的编程助手。不需要外部数据库,不需要云服务,本地 embeddings 免费可用。
开源(Apache 2.0),19.8K star,3 个月 24 个版本。社区足够活跃,但离生产级稳定还有距离。适合愿意折腾的个人开发者现在就用,不适合追求开箱即用的团队直接上生产。
如果你想继续看这类 AI 工具拆解,我会把上手路径、关键限制和可复用配置整理成清单,方便你直接判断值不值得试。
引用链接
[1]agentmemory: https://github.com/rohitg00/agentmemory
