 夜雨聆风
夜雨聆风AI 淘汰的不是员工,而是不会运行的公司
大多数人理解企业 AI 的方式,一开始就错了。
他们以为问题是:公司有没有买最强模型,员工有没有用 AI 工具,团队有没有做出几个 demo。
但真正的问题不是这些。
真正的问题是:一个组织有没有能力把 Agent 放进自己的真实工作流里,让它长期、稳定、可控、可观测地执行任务。
模型只是入口。
运行协议才是分水岭。

这不是一条普通新闻
6 月 2 日,Microsoft 在 Build 2026 之后连续释放了几组信息:
企业 Agent 平台要覆盖 build、contextualize、run、govern、improve、surface; Foundry 开始强调 hosted agents、long-running agents、A2A、tracing、evaluation、agent optimizer; Windows 把 Agent 安全往 OS 层推,做 policy-driven execution container; Security 团队把 autonomous agent 的核心安全模式拆成 identity、least permission、deterministic HITL、agent-as-microservice。
如果只看表层,很容易把它理解成一次产品发布。
但我更关心的是另一件事:
Microsoft、IBM、AI Harness Engineering 论文、开发者社区里关于 circuit breaker 和 audit trail 的讨论,都在指向同一个判断。
AI 正在从“工具采用问题”,变成“组织运行系统问题”。
IBM 在 Think 2026 里把它叫 AI Operating Model。它不是一个更大的 AI 平台名词,而是一个更清楚的结构判断:
Agent 负责执行和适应; Data 负责实时上下文; Automation 负责把动作接进流程; Hybrid / governance 负责让这些东西在真实组织边界里可控运行。
换句话说,AI 不再只是某个岗位旁边的助手。
它开始进入组织的运行层。
工具解决效率,系统形成杠杆
过去一年,很多团队对 AI 的理解停在三个层面:
给员工开账号; 接一个 RAG; 做几个内部 Copilot。
这些不是错。
但它们只能证明“AI 可以被使用”,不能证明“AI 可以被运行”。
两者差别很大。
工具使用关心的是单次输出。
系统运行关心的是:
这个 Agent 谁创建的? 它能访问什么数据? 它能调用哪些工具? 它什么时候必须停下来? 它怎么证明任务完成了? 它失败之后,系统怎么知道失败在哪里? 它的每次执行,能不能沉淀成下一轮改进?
如果这些问题没有答案,AI 只是散落在组织里的能力碎片。
看起来到处都是智能,实际上到处都是不可控的临时脚本。
真正的 AI Operating Model,至少有六层协议
我会把企业 AI 的生产化拆成六层。
不是六个功能。
是六个必须长期运行的协议。
第一层:Lifecycle Protocol。
Agent 不能只是 prompt 文件或聊天入口。它需要像软件一样有 source、test、deploy、observe、improve。
没有 lifecycle,就没有版本管理、回滚、审计和复盘。
第二层:Context Protocol。
不要把上下文理解成“把更多资料塞进窗口”。
真正的 context 是结构化、授权过、按任务暴露的企业知识。哪些信息永远在场,哪些信息按需加载,哪些信息禁止进入上下文,都应该是协议,不是临时拼接。
第三层:Runtime Protocol。
Agent 不只是调用模型。它要运行在某个环境里。
这个环境要处理隔离、状态、文件系统、长任务、工具调用、异常恢复、成本上限和执行边界。
Demo 可以裸跑。
Production 必须有 runtime。
第四层:Governance Protocol。
Agent 必须有身份。
不是“某个用户通过 AI 做了什么”的模糊记录,而是每个 Agent 实例都有自己的 identity、owner、permission、audit trail 和 lifecycle。
没有身份,就没有权限边界。
没有权限边界,就没有可靠自治。
第五层:Eval Protocol。
Eval 不能只发生在上线前。
生产 Agent 的每次行为都应该留下 trace。trace 进入 evaluation,evaluation 变成改进候选,候选经过验证再部署。
这不是“调 prompt”。
这是生产反馈闭环。
第六层:Organization Protocol。
Agent 最终不是一个技术组件,而是组织成员的一种新形态。
它需要 sponsor,owner,职责边界,协作方式,升级路径,退出机制。
当 Agent 可以在后台长期执行任务时,组织的问题不再是“谁会用 AI”,而是“谁对这个 Agent 的行为负责”。

Harness 的价值:让能力变成证据
AI Harness Engineering 这篇论文给了一个很好的语言。
它没有把 autonomous software engineering 的失败归因于“模型还不够强”,而是把问题拆成 model、harness、environment 三者组成的系统。
这件事非常关键。
因为很多人评估 Agent 时,默认只看模型。
但 Agent 能不能干活,不是单纯由模型能力决定的,而是由它周围的运行基建决定的:
task specification; context selection; tool access; project memory; task state; observability; failure attribution; verification; permissions; entropy auditing; intervention recording。
论文里最有价值的不是新名词,而是 H0 到 H3 的分层。
H0 只有任务和代码。
H1 加工具和测试命令。
H2 加项目记忆、任务状态和上下文选择。
H3 加复现协议、失败归因、确定性检查、验证报告。
真正的变化在 H3。
低层级 Agent 只能给你一个 patch。
高层级 Agent 要给你一个证据包。
它不只是说“我完成了”。
它要证明:
我读了哪些上下文; 我调用了哪些工具; 我复现了什么失败; 我为什么认为原因在这里; 我跑了哪些验证; 我引入了什么维护负担; 哪些地方需要人类介入。
这就是 demo 和 production 的差别。
Demo 允许 Agent 自称完成。
Production 要求系统生成可审计证据。
组织真正需要的不是更多 Agent,而是更少黑箱
现在很多团队的误区是:既然 Agent 有用,那就多做一些 Agent。
这是一个危险的方向。
没有运行协议的 Agent 越多,组织不是更智能,而是更混乱。
你会得到:
一堆没人知道 owner 的 bot; 一堆权限边界不清的 tool call; 一堆无法复盘的执行结果; 一堆上线前看起来正常、上线后没人敢信的自动化; 一堆成本突然膨胀但找不到责任归属的长任务。
Agent sprawl 会成为新的 SaaS sprawl。
只是这一次,问题不只是账单。
还有权限、数据、审计、执行链路和业务责任。

所以我会把团队是否进入 AI 原生阶段,压缩成一组问题:
每个 Agent 是否有明确 owner 和 sponsor? 每个 Agent 是否有独立 identity,而不是借用人的账号? 每个 Agent 的工具权限是否按任务阶段收敛? 每个高风险动作是否有确定性 HITL 触发,而不是让模型自己决定? 每次任务完成是否有验证证据,而不是自然语言总结? 每次失败是否能回到 trace、eval 和改进候选? 每个 Agent 的成本、延迟、失败率和权限变更是否可观测? 每个 Agent 是否可以被暂停、降级、回滚或退休?
如果这些问题答不上来,就不要谈 autonomous enterprise。
那只是自动化债务。
反馈闭环才是长期价值
Agent 的长期价值,不在第一次跑通。
第一次跑通只是 demo。
长期价值来自一个可运行的 feedback loop:
Agent 在真实环境里执行任务; 系统记录完整 trace; eval 识别失败、退化、越界和成本异常; optimizer 或人工 review 生成改进候选; 候选通过回归测试和业务约束; 新版本小流量部署; 新 trace 继续进入下一轮循环。
这才是 AI 系统开始复利的地方。
不是模型突然变聪明。
而是组织把每一次执行都变成了可学习、可验证、可回滚的经验。
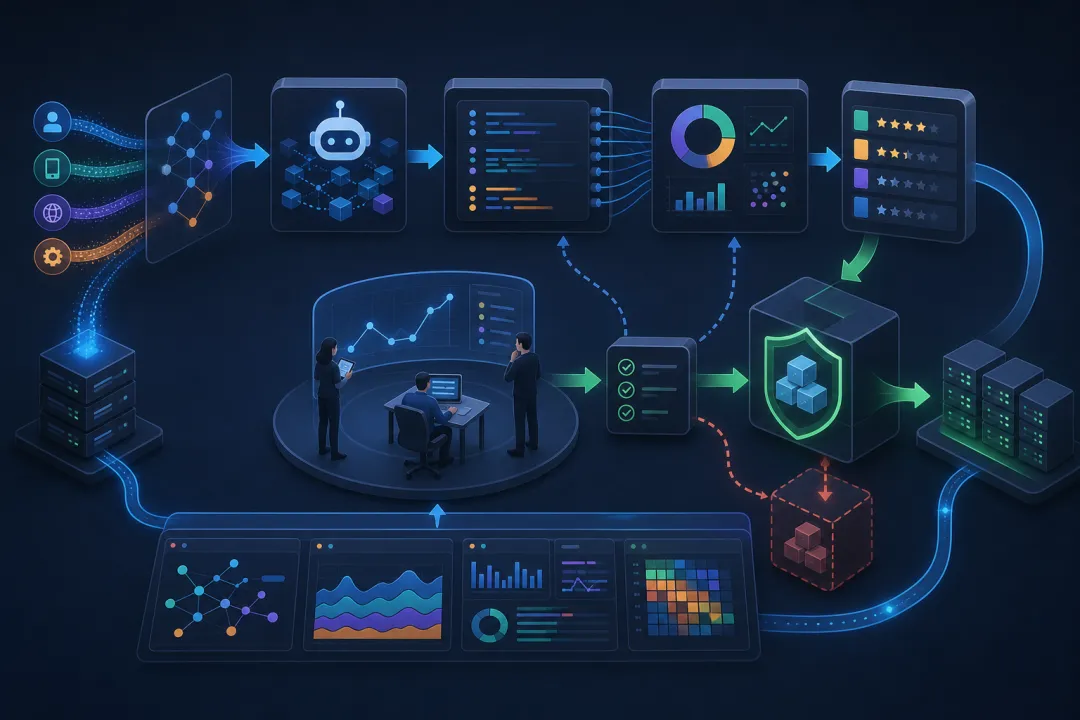
这也是为什么我不太相信“给所有员工配 AI 工具,组织自然就会变 AI 原生”。
工具扩散不等于系统升级。
很多组织会出现一种假繁荣:
使用率很高; demo 很多; 内部分享很多; 但真正进入核心流程的 Agent 很少; 真正能被审计、治理、复盘、持续改进的 Agent 更少。
这不是员工不努力。
这是组织没有运行协议。
不要把这些东西当成大厂专属
很多人看到 Microsoft、IBM 这类发布,第一反应是:这是企业级大客户的东西,和个人或小团队无关。
我不这么看。
大厂只是先把问题命名出来。
小团队同样会遇到同一组问题,只是尺度更小:
你的写作 Agent 是否知道你的长期选题边界? 你的 coding Agent 是否必须跑验证才能宣布完成? 你的研究 Agent 是否会记录一手来源和已写过的主题? 你的自动化是否有预算上限和失败通知? 你的个人 workflow 是否能从上次失败里学习?
所谓 AI 原生个人操作系统,本质上也是 operating model。
只是组织从公司变成了个人。
资产从部门流程变成了个人判断、写作风格、知识系统和反馈习惯。
几个必须避免的反模式
第一,不要做万能 Agent。
权限越宽,责任越虚。Agent 应该像 microservice 一样有窄边界、清接口和可组合能力。
第二,不要把 RAG 当 context protocol。
RAG 是检索方式,不是上下文治理。真正的问题是哪些知识被结构化、授权、排序、压缩和复用。
第三,不要让模型决定什么时候需要人类审核。
高风险动作的 HITL 应该由 application layer 或 orchestrator 触发。让模型自己判断是否升级,本质上是让被监管对象决定监管是否发生。
第四,不要只做上线前 eval。
Agent 的行为会随上下文、工具、模型、数据和用户变化而漂移。没有生产 trace 的 eval,只能证明过去某个静态样本。
第五,不要用模型升级掩盖系统缺陷。
更强模型可以提高上限,但不能替你定义权限、验证、观测、回滚和责任。
第六,不要忽略 circuit breaker。
长任务、递归调用、工具失败和成本异常都需要自动中断机制。Kill switch 需要人看到问题,circuit breaker 是系统自己先收住风险。
真正的分水岭
未来组织的 AI 差距,不会只体现在“谁用了更强模型”。
那是最容易被复制的部分。
真正的差距会体现在:
谁有更清晰的任务边界; 谁有更稳定的上下文结构; 谁有更强的运行时; 谁有更严格的权限和身份; 谁有更好的 eval; 谁能把失败转成下一轮改进; 谁能把人的判断沉淀成机器可执行的协议。
AI 不会先替代员工。
它会先淘汰那些没有把工作流协议化、没有把判断力系统化、没有把执行过程证据化的组织。
工具解决效率。
系统形成杠杆。
参考资料
Microsoft Official Blog: AI alone won't change your business. The system running it will.[1] Microsoft Foundry Blog: Build and run agents at scale with Microsoft Foundry at Build 2026[2] Windows Developer Blog: Windows platform security for AI agents[3] Microsoft Security Blog: Defense in depth for autonomous AI agents[4] IBM Newsroom: Think 2026: IBM Delivers the Blueprint for the AI Operating Model as the AI Divide Widens[5] arXiv: AI Harness Engineering: A Runtime Substrate for Foundation-Model Software Agents[6]
引用链接
[1]AI alone won't change your business. The system running it will.: https://blogs.microsoft.com/blog/2026/06/02/ai-alone-wont-change-your-business-the-system-running-it-will/
[2]Build and run agents at scale with Microsoft Foundry at Build 2026: https://devblogs.microsoft.com/foundry/agent-service-build2026/
[3]Windows platform security for AI agents: https://blogs.windows.com/windowsdeveloper/2026/06/02/windows-platform-security-for-ai-agents/
[4]Defense in depth for autonomous AI agents: https://www.microsoft.com/en-us/security/blog/2026/05/14/defense-in-depth-autonomous-ai-agents/
[5]Think 2026: IBM Delivers the Blueprint for the AI Operating Model as the AI Divide Widens: https://newsroom.ibm.com/2026-05-05-think-2026-ibm-delivers-the-blueprint-for-the-ai-operating-model-as-the-ai-divide-widens
[6]AI Harness Engineering: A Runtime Substrate for Foundation-Model Software Agents: https://arxiv.org/abs/2605.13357
