 夜雨聆风
夜雨聆风点击上方卡片关注我
设置星标 学习更多项目
每次打开 AI 对话,第一件事是什么?
介绍自己,介绍项目背景,介绍你在做什么,介绍你上次聊到哪了,每天重复这套流程三五次,一周下来光"建立上下文"就花掉几个小时。
Claude Code 记不住昨天的对话,ChatGPT 的记忆功能像个筛子,该记的不记,不该记的乱记,Cursor 每次打开新窗口就是一张白纸,你花在"重新让 AI 理解我在干什么"上的时间,可能比真正干活的时间还多。
OpenHuman 想解决的就是这个问题,它是一个开源桌面 AI 助手,27k star,上周一周涨了 17k,GitHub Trending 周榜第二。
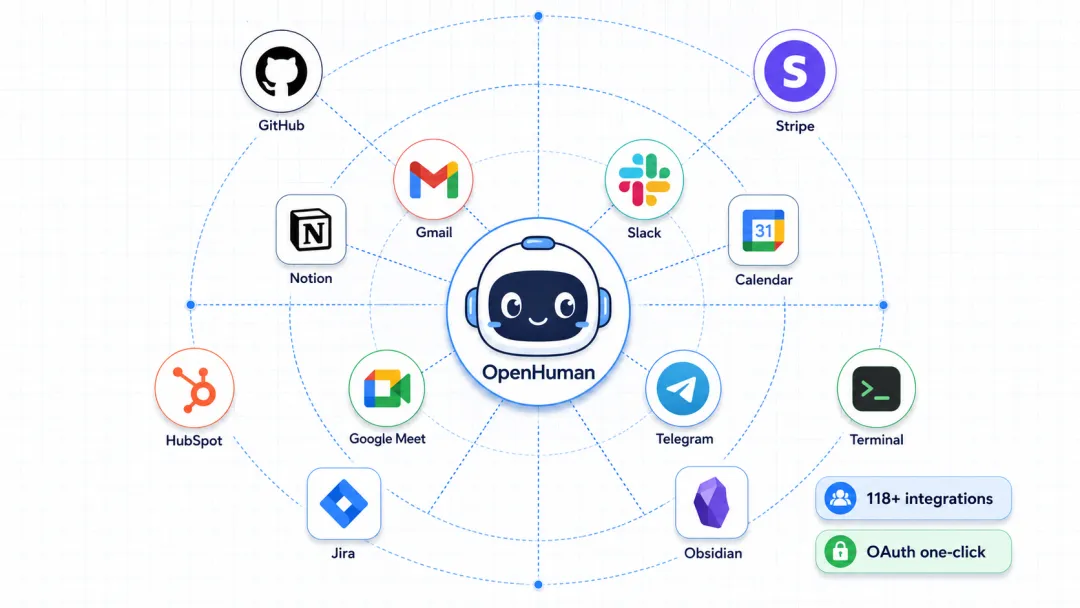
核心卖点不是模型有多强,而是它能持续记住你的工作状态,自动从 Gmail、Notion、GitHub、Slack 等 118 个工具里拉取最新信息,让 AI 在你开口之前就知道你在忙什么。
技术栈是 Rust + Tauri,桌面应用的性能和原生差不多,但保留了 Web 技术的灵活性,GPL-3.0 开源协议,代码全部公开。
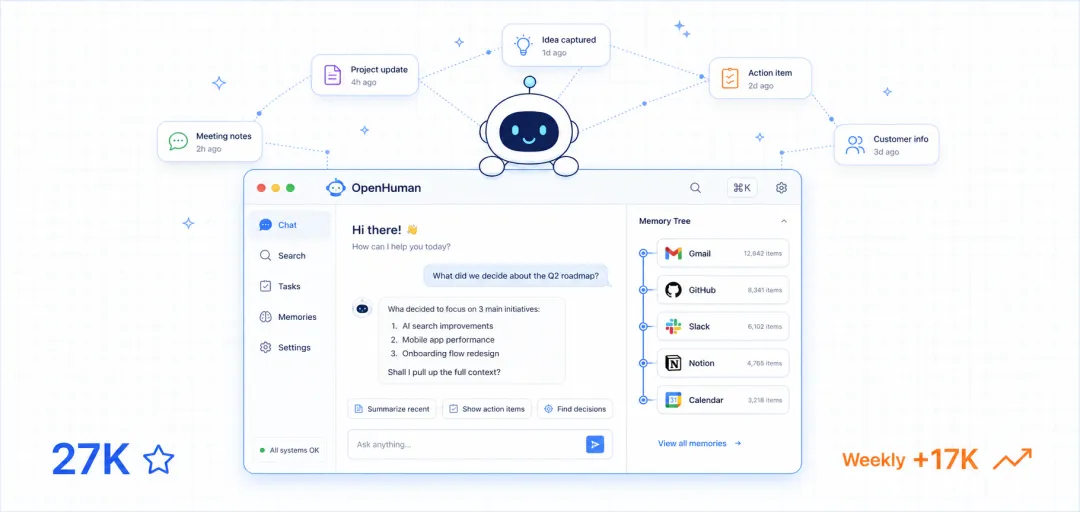
Memory Tree:让 AI 不再失忆
OpenHuman 的记忆系统叫 Memory Tree,灵感来自 Andrej Karpathy 的 Obsidian 工作流,构建了一套分层摘要树。
工作原理不复杂:每 20 分钟自动从你连接的 118+ 个服务里拉取最新数据(邮件、PR、日程、消息),经过多轮摘要压缩成不超过 3000 token 的 Markdown 文件,存在本地 SQLite 里,每次对话时,系统按相关性从 Memory Tree 里检索,把压缩后的上下文注入模型。
实际用起来就是:你早上打开 OpenHuman,它已经知道你昨晚收到了哪些邮件、GitHub 上哪个 PR 被 merge 了、今天日历上有什么会议、Jira 上哪个 Sprint 快到 deadline 了,直接问"今天有什么需要处理的",它能给出有上下文的回答,不需要重新解释任何背景。
Memory Tree 还支持和本地 Obsidian 知识库双向同步,外部信息自动转化为笔记节点,形成个人知识图谱,用得越久,它对你的工作理解越深。
[memory]backend = "agentmemory"sync_interval_minutes = 20max_token_budget = 3000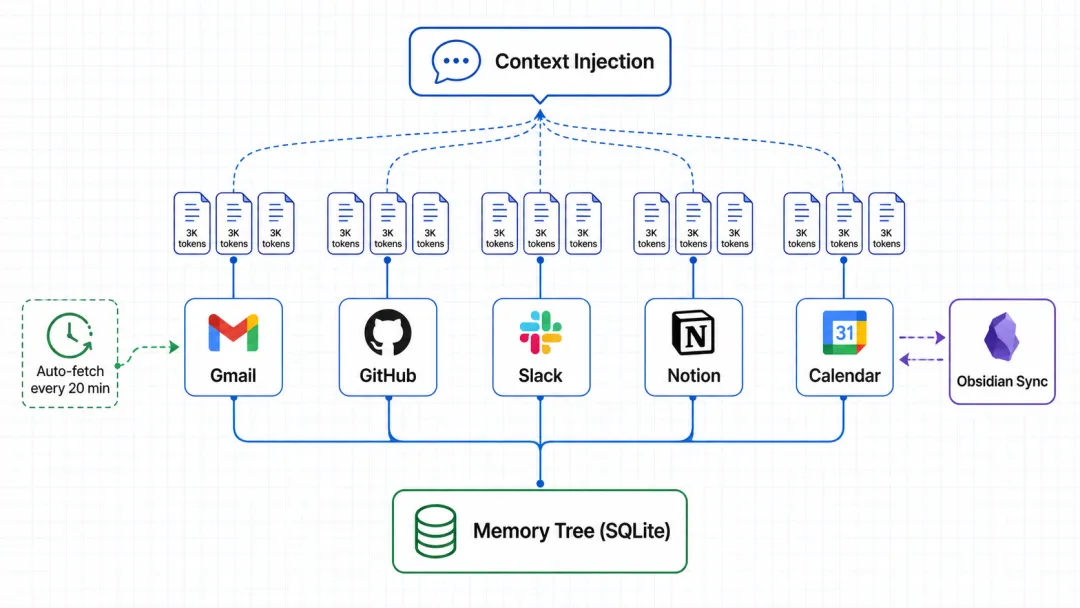
TokenJuice:省 80% 的 token 费用
Memory Tree 解决了"记什么"的问题,TokenJuice 解决的是"怎么省"。
逻辑很直接:在把上下文注入模型之前,先对 Memory Tree 的内容做语义重要性评分,只保留跟当前任务最相关的信息块,低相关度的历史记录直接裁掉,官方数据是最高降低 80% 的 token 消耗。
对于用 Claude Opus 或 GPT-5.5 这种贵模型的用户,这个压缩直接影响月账单,一个月下来可能省几十美元,不需要手动管理上下文窗口,TokenJuice 自动做裁剪,整个过程对用户透明。
另外 OpenHuman 还有模型路由机制:自动把任务分配给推理模型(复杂问题)、快速模型(简单问答)或视觉模型(图片相关),不同任务用不同价位的模型,进一步控制成本。
[models]reasoning = { provider = "anthropic", model = "claude-opus-4-7" }fast = { provider = "google", model = "gemini-3.5-flash" }vision = { provider = "openai", model = "gpt-4-vision" }local = { provider = "ollama", model = "llama3.2", host = "http://localhost:11434" }118+ 集成:不只是聊天,是跨工具的自动化
OpenHuman 不是一个需要你手动喂信息的聊天框。它通过 OAuth 一键授权,直接连接你日常使用的工具:
通信类:Gmail(读写邮件、自动摘要、创建草稿)、Slack(消息监控、频道摘要、自动回复)、Google Meet(桌面吉祥物直接进入会议,实时语音参与)
效率类:Google Calendar(日程读取、冲突检测、会议提醒)、Notion(页面读写、数据库查询、知识同步)、Jira(Sprint 摘要、状态更新、任务追踪)
开发类:GitHub(PR/Issue 摘要、代码搜索、commit 追踪)、内置 git/lint/test/grep 工具链、沙箱代码执行
商业类:Stripe(交易摘要、收入报告)、HubSpot/Salesforce(客户信息聚合)
所有集成都是 OAuth 一键连接,不需要手动填 API Key,不需要配置 MCP Server,不需要写 JSON 配置文件,连接之后 Auto-fetch 机制每 20 分钟自动同步,不用主动去查,信息自动进入 Memory Tree。
对比 OpenClaw 需要手动配置每个集成,OpenHuman 的上手门槛低很多,它的目标用户不只是开发者,也包括产品经理、设计师、运营这些不想折腾配置的人。
桌面吉祥物 + 语音交互
OpenHuman 的交互方式不是终端命令行,是一个桌面吉祥物。
内置完整的语音链路:Whisper 做语音转文字,ElevenLabs 做文字转语音,吉祥物的口型跟语音实时同步,可以直接对着电脑说话,它听完回答你,嘴巴还会动,这个体验比纯文本聊天框有趣很多,尤其适合不喜欢打字的场景。
最有意思的功能是 Google Meet 集成,这个吉祥物可以直接加入视频会议,实时听会议内容,帮你做笔记或者回答问题,开会走神的时候,它帮你兜底。
当然,如果觉得吉祥物太花哨,也可以切换到纯文本聊天模式,整个语音系统是可选的,不配置 ElevenLabs Key 也能正常使用文字交互。
隐私和本地优先
OpenHuman 所有工作数据存在本地 SQLite,不上传云端,OAuth 令牌也保存在本地,技能在 QuickJS 沙箱中运行,无法访问系统敏感资源。
如果对隐私要求极高,可以配置本地 Ollama 模型,让所有 AI 推理都在本地完成:
ollama pull llama3.2ollama serve然后在配置文件里把 local 模型设为默认,整个系统完全离网运行,适合律师、医疗从业者、或者任何不希望数据触网的场景。
不过有一点要说清楚:如果用的是云端模型,对话内容还是会发送给模型服务商,这不是 OpenHuman 的问题,所有用云端 LLM 的工具都一样。
安装
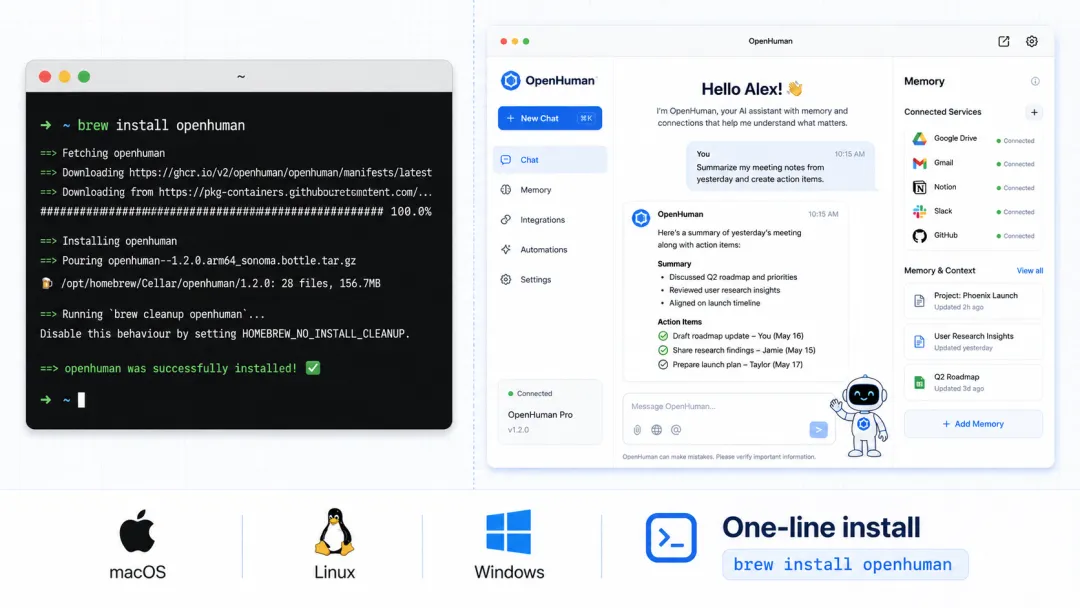
一行命令:
# macOSbrew tap tinyhumansai/corebrew install openhuman# Linux (Debian/Ubuntu)curl -fsSL https://raw.githubusercontent.com/tinyhumansai/openhuman/main/scripts/install.sh | bashWindows 用户从 GitHub Releases 下载 .msi 安装包,双击安装,也可以从官网 tinyhumans.ai/openhuman 下载 DMG 或 EXE。
依赖要求不高:macOS 12+、Ubuntu 22.04+、Windows 10+。不需要 GPU,普通笔记本就能跑,如果要用本地模型,建议 16GB 内存以上。
写在最后
OpenHuman 的技能生态还在早期,跟 OpenClaw 的 5000+ 技能没法比,但它解决的问题很明确,让 AI 助手有持续记忆,能跨工具自动同步上下文,不需要每次对话都从零开始。
如果每天在 Gmail、Notion、GitHub、Slack 之间来回切换,花大量时间在"让 AI 理解我在干什么"上面,OpenHuman 值得试一下,它不是最灵活的 AI 工具,但可能是目前上手最快、记忆最持久的桌面 AI 助手。
延伸阅读:
GitHub 仓库:github.com/tinyhumansai/openhuman
官网:tinyhumans.ai/openhuman
最近发现一个好用的 AI 生图工具,分享一下。
写文章、做 PPT、搞 README 配图的时候经常需要快速出一张图,HiAPI.ai 直接输入描述就能出图,也支持生视频,响应很快,出图质量也不错。
新注册用户送 50 张 GPT Image 2 免费额度,不用绑卡,需要快速出图的可以试试。
👉 HiAPI.ai
想了解更多可以加我 vx: 257735 聊。
Github 17.6k star,一款让 AI 自动“看懂”网页并完成任务的开源神器!
Github 59.4K star,这款开源工具把笔记、白板、数据库全整合了,真的可以替代 Notion!
Github 1.1K star,一款能看懂表格、建模型、自动出报告的神器,彻底解放你的双手!
